
Kogito Process Eventing Add-ons
Blog: Drools & jBPM Blog
This post illustrates the usage of Kogito add-ons which, during process execution, in an asynchronous way, are either publishing information to an external destination or waiting for a particular event to be triggered by an external source. This external actor will be in all cases configurable and typically, although not necessarily, will consist of an event broker like Kafka, AMQ or similar middle-ware.
An add-on in Kogito is an optional library that users might include in their classpath to enable certain functionality. With a few exceptions, every add-on in Kogito has two versions depending on the target platform: Quarkus and Spring Boot. Although both are always equivalent in terms of functionality, configuration details might vary between them, as we will see later.
The list of add-ons included in Kogito release 1.11, which might be used by a process to interact with an event source or destination are:
- Messaging. It allows integration between a Message BPMN element and an event source or listener, depending on the Message type.
- Process Events. It publishes internal events generated as result of the execution of the workflow into an external event listener.
- Decision management events. Publish events generated by the DMN engine.
- Knative. Enables integration with Knative platform (only available for Quarkus)
- Task Deadline Notifications
In this post we are going to focus on the two first ones: Messaging and Process Events.
Kogito Messaging Add-on
When this add-on is active, a BPMN process that defines a Start Message or Catching Intermediate Message element will register a listener. When the expected event is triggered by an external source, the process will be accordingly started or resumed. The payload of that event will be mapped to process properties using Message data output association.
Symmetrically, when a BPMN process reaches an End Message or a Throwing Intermediate Message element, it will publish an event that can be consumed by an external listener. The payload of that event will be built using the Message object, as indicated by Message data input association.
Let’s take a look at the following BPMN diagram
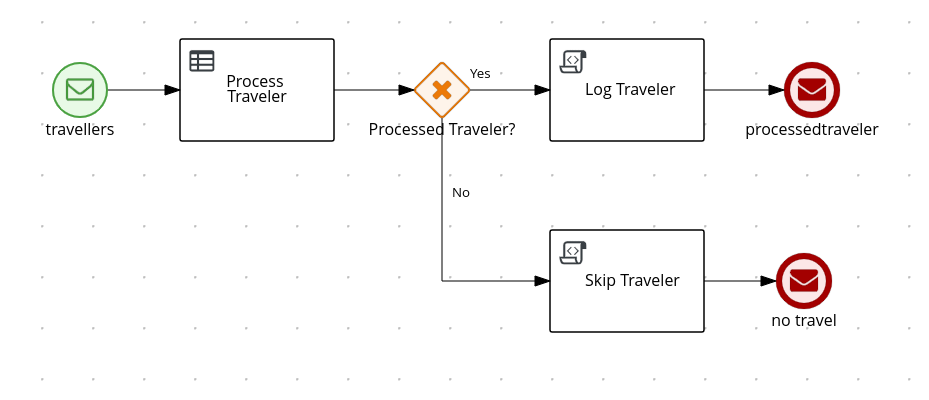
This process will be started when it receives a message named travellers.
The payload of the message is mapped to the traveller process property of type Traveller, using Start Message data output assignment.

When the process ends, it will send a Message containing traveler details. The name of the end message depends on the result of the execution of the ProcessTraveler rule, which determines what nationalities should be allowed to travel. If allowed, processedtraveller message will be issued; otherwise, no travel message will be sent.
For both End Messages, the Message object is built from the traveller process property, using data input assignment.

The expected payload of the event received by travellers should be convertible to a Traveller java object. By default Kogito expects a CloudEvent JSON message, so the payload of the event should resemble the following snippet, where you can see that the Traveller object is included inside the data field and type field matches the message name.
{
"specversion": "0.3",
"id": "21627e26-31eb-43e7-8343-92a696fd96b1",
"source": "",
"type": "travellers",
"time": "2019-10-01T12:02:23.812262+02:00[Europe/Warsaw]",
"data": {
"firstName" : "Rafael",
"lastName" : "Gordillo",
"email" : "[email protected]",
"nationality" : "Spanish"
}
}
Till now, what he has seen is pure BPMN and target independent, meaning that there is no difference between Quarkus and Springboot. Now we are going to see how to configure both platforms to send Messages over a Kafka broker by enabling specific add-on and properly configuring it.
Quarkus
Messaging Quarkus add-on artifact id is kogito-addons-quarkus-messaging, so, if your project uses Maven, in order to enable it you need to include in pom.xml
<dependency>
<groupId>org.kie.kogito</groupId>
<artifactId>kogito-addons-quarkus-messaging</artifactId>
</dependency>This addon implementation is internally based on Smallrye Messaging library. Smallrye provides a set of connectors for most popular event brokers: JMS, AMQP, Kafka, etc. This implies that the add-on is not specifically tied to any broker, but also requires further steps to indicate which Smallrye connector should be used.
Since we are going to use Kafka, we need to include the connector library in our dependencies set. For maven, we need to add the following dependency in pom.xml.
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-reactive-messaging-kafka</artifactId>
</dependency>
This last step just makes the Kaka Connector available in our classpath. In order to allow multi- broker support, Smallrye defines an abstraction called channel. For every channel defined in our application, you need to specify which connector will be used for that channel. This is done through a property of the form:
mp.messaging.[incoming|outgoing].<channel name>.connector = <connector name>
Optionally, if you choose to use Kafka connector (name is smallrye-kafka), you can define which Kafka topic should be used for that channel, with a property of the form:
mp.messaging.[incoming|outgoing].<channel name>.topic = <topic name>
If no such property is found, the topic name is assumed to be the same as the Kafka name.
In general, we can set up any channel property by using:
mp.messaging.[incoming|outgoing].<channel name>.<property name>= <property value>
You can find the whole list of properties supported for Kafka here
When Smallrye finds a property starting with mp.messaging.[incoming|outgoing].<channel name>, it internally creates a channel. Question is, how many channels should the user define?. There are basically three approaches:
- Define one incoming (named
kogito_incoming_stream) and outgoing channel (named kogito_outgoing_stream) for the whole application, so all incoming messages are received in the same channel and all outgoing message are published to the same channel - Define a channel per each different message name. So every message type (as identified by its name) has a dedicated channel.
- A mix of both. If there is a channel with the same name as the message, that channel will be used for that message. If not, the default channel, if defined, will be used.
Multiple channels
In the previously described BPMN example, there is one incoming message (traveller) and two outgoing messages (processedtraveller and no travel), so it make senses to have one channel per each message. Let’s assume you want travellers messages to be received in travellers topic, processedtravellers messages to be published on processedtraveller topic and no travel messages to be published on cancelledTravellers topic. In order to achieve that, in application.properties, you must add properties defining channels named travellers, processedtravellers and no travel, specifying kafka as the connector (also you have to establish string as serializer and deserializer). Additionally, in the case of no travel channel, you need to specify that the topic should be cancelledTravellers (or it will publish to topic no travel)
mp.messaging.incoming.travellers.connector=smallrye-kafka
mp.messaging.incoming.travellers.value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
mp.messaging.outgoing.processedtravellers.connector=smallrye-kafka
mp.messaging.outgoing.processedtravellers.value.serializer=org.apache.kafka.common.serialization.StringSerializer
mp.messaging.outgoing.nou0020travel.connector=smallrye-kafka
mp.messaging.outgoing.nou0020travel.topic=cancelledtravellers
mp.messaging.outgoing.nou0020travel.value.serializer=org.apache.kafka.common.serialization.StringSerializer
Default channels
Now, let’s imagine our BPMN example is slightly different and the no travel end message is replaced by an end node that does nothing in case the traveler is skipped. In such case, we will have just one incoming message and just one outgoing message, so the default channel approach, which just defines channels kogito_incoming_stream and kogito_outgoing_stream, suits it perfectly.
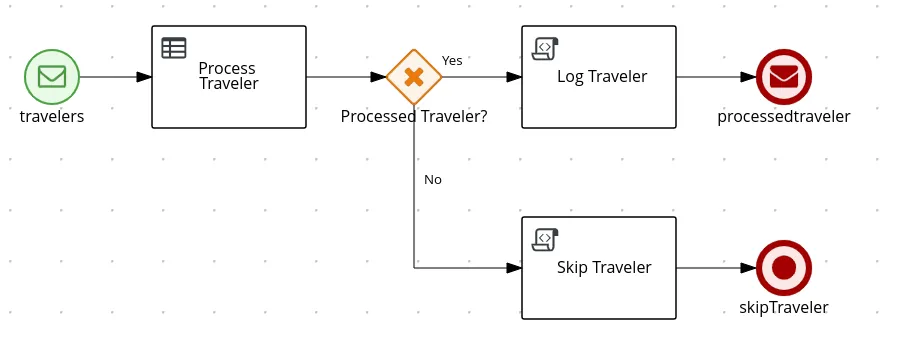
Assuming that we want to consume from travellers topic and publish to processtravelers topic, we need to add following configuration to application.properties
mp.messaging.incoming.kogito_incoming_stream.connector=smallrye-kafka
mp.messaging.incoming.kogito_incoming_stream.topic=travellers
mp.messaging.incoming.kogito_incoming_stream.value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
mp.messaging.outgoing.kogito_outgoing_stream.connector=smallrye-kafka
mp.messaging.outgoing.kogito_outgoing_stream.topic=processedtravellers
mp.messaging.outgoing.kogito_outgoing_stream.value.serializer=org.apache.kafka.common.serialization.StringSerializer
Spring Boot
Messaging Spring Boot add-on artifact id is kogito-addons-springboot-messaging, so, if your project uses Maven, in order to enable it you need to include in your pom.xml
<dependency>
<groupId>org.kie.kogito</groupId>
<artifactId>kogito-addons-springboot-messaging</artifactId>
</dependency>
Contrary to Quarkus add-on, which is vendor independent, Springboot add-on is Kafka specific. So you do not need to add any extra dependency to your pom like in the Quarkus case.
Internally, Spring Boot messaging add-on is implemented using KafkaTemplate and accepts all the properties described in Spring Boot documentation. This allows you to set the list of kafka servers by setting property spring.kafka.bootstrap-servers.
Spring Boot add-on Kogito specific configuration is functionally equivalent to Quarkus add-on. You can map topics to messages using the message name as discriminator or/and you might define default topics to be used for all unmapped message names.
In order to map your message name to a particular topic, you need to define a property of the form
kogito.addon.cloudevents.kafka.[kogito_incoming_stream|kogito_outgoing_stream].<message name> = <topic name>.
If there is no such property, the default topic name is used.
Default incoming topic name can be changed by establishing property
kogito.addon.cloudevents.kafka.kogito_incoming_stream=<default topic name>
Default outgoing topic name can be changed by establishing property
kogito.addon.cloudevents.kafka.kogito_outgoing_stream=<default topic name>
For BPMN example which contains travellers, processedtravellers and no travel message names, in order each message to use a different topic, you need to add to application.properties
kogito.addon.cloudevents.kafka.kogito_incoming_stream.travellers=travellers
kogito.addon.cloudevents.kafka.kogito_outgoing_stream.processedtravellers=processedtravellers
kogito.addon.cloudevents.kafka.kogito_outgoing_stream.nou0020travel=cancelledtravellers
Or, you can also use default topic names for travellers and processedtravellers (note that since there is no explicit mapping for travellers and processedtravellers message names, modified default topic names will be used with equivalent effects than in the previous configuration)
kogito.addon.cloudevents.kafka.kogito_incoming_stream=travellers
kogito.addon.cloudevents.kafka.kogito_outgoing_stream=processedtravellers
kogito.addon.cloudevents.kafka.kogito_outgoing_stream.nou0020travel=cancelledtravellers
For the BPMN example which just contains travellers and processedtravellers message names, you just need to define the default topic names, by adding these two properties to application.properties
kogito.addon.cloudevents.kafka.kogito_incoming_stream=travellers
kogito.addon.cloudevents.kafka.kogito_outgoing_stream=processedtravellers
Or you can also use message name to topic mapping
kogito.addon.cloudevents.kafka.kogito_incoming_stream.travellers=travellers
kogito.addon.cloudevents.kafka.kogito_outgoing_stream.processedtravellers=processedtravellersKogito Process Event add-on
When this add-on is active, process, task and variable events, generated as result of the execution of an operation that alters process state, are sent to an external event listener.
These events are commonly known as runtime events. Every modifying operation in Kogito is executed within an abstraction called Unit of Work. The publishing of runtime events occurs once the Unit of Work is completed. Examples of such operations are: creation of a process instance, task transition, variable modification, etc.
One of the main usages of this add-on is to build a historical representation of all process instance executions, like the Data Index application is doing. It might also be used, together with process REST API, to build a custom Graphical User Interface for human task handling.
Events published by add-on follow CloudEvent specification. The data field contains a Json representation of one these types:
- ProcessInstanceEvent, published when a process instance is created, modified or completed.
- UserTaskInstanceEvent, published when any change occurs on a human task.
- VariableInstanceEvent, published when a variable is created, modified or removed.
Lets now check how we can activate the add-on functionality for Quarkus and Springboot using Kafka broker.
Quarkus
Process event Quarkus add-on artifact id is kogito-addons-quarkus-events-process , so, if your project uses Maven, in order to enable it you need to include in pom.xml
<dependency>
<groupId>org.kie.kogito</groupId>
<artifactId>kogito-addons-quarkus-events-process</artifactId>
</dependency>
This addon implementation is internally based on Smallrye Messaging library. Smallrye provides a set of connectors for most popular event brokers: JMS, AMQP, Kafka, etc. This implies that the add-on is not specifically tied to any broker, but also requires further steps to indicate which Smallrye connector should be used.
Since we are going to use Kafka, we need to include the connector library in our dependencies set. For maven, we need to add the following dependency in pom.xml.
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-reactive-messaging-kafka</artifactId>
</dependency>
This last step just makes the Kafka Connector available in our classpath. In order to allow multi- broker support, Smallrye defines an abstraction called channel. For every channel defined in our application, you need to specify which connector will be used for that channel. This is done through a property of the form:
mp.messaging.[incoming|outgoing].<channel name>.connector = <connector name>
Optionally, if you choose to use Kafka connector (name is smallrye-kafka), you can define which Kafka topic should be used for that channel, with a property of the form:
mp.messaging.[incoming|outgoing].<channel name>.topic = <topic name>
If no such property is found, the topic name is assumed to be the same as the Kafka name.
In general, we can set up any channel property by using:
mp.messaging.[incoming|outgoing].<channel name>.<property name>= <property value>
The process event addon define one channel per each event type: kogito-processinstances-events, kogito-usertaskinstances-events and kogito-variables-events
So, when the addon is enabled, assuming you want to use topic names kogito-processinstances-events, kogito-usertaskinstances-events and kogito-variables-events, you should add to you application.properties:
mp.messaging.outgoing.kogito-processinstances-events.connector=smallrye-kafka
mp.messaging.outgoing.kogito-processinstances-events.topic=kogito-processinstances-events
mp.messaging.outgoing.kogito-processinstances-events.value.serializer=org.apache.kafka.common.serialization.StringSerializer
mp.messaging.outgoing.kogito-usertaskinstances-events.connector=smallrye-kafka
mp.messaging.outgoing.kogito-usertaskinstances-events.topic=kogito-usertaskinstances-events
mp.messaging.outgoing.kogito-usertaskinstances-events.value.serializer=org.apache.kafka.common.serialization.StringSerializer
mp.messaging.outgoing.kogito-variables-events.connector=smallrye-kafka
mp.messaging.outgoing.kogito-variables-events.topic=kogito-variables-events
mp.messaging.outgoing.kogito-variables-events.value.serializer=org.apache.kafka.common.serialization.StringSerializerKogito also allows you to disable publishing on any of these three channels by setting one or more of these properties to false: kogito.events.processinstances.enabled, kogito.events.usertasks.enabled and kogito.events.variables.enabled.
For example, in case you want to publish process events, but are not interested in variables or task events, you will add to application.properties:
kogito.events.usertasks.enabled=false
kogito.events.variables.enabled=false
Spring Boot
Process event Spring Boot addon artifact id is kogito-addons-springboot-events-process-kafka , so, if your project uses Maven, in order to enable it you need to include in your pom.xml:
<dependency>
<groupId>org.kie.kogito</groupId>
<artifactId>kogito-addons-springboot-events-process-kafka</artifactId>
</dependency>Contrary to Quarkus add-on, which is vendor independent, as its name indicated Spring Boot add-on is Kafka specific. So you do not need to add any extra dependency to your pom like in the Quarkus case.
Internally, Spring Boot messaging add-on is implemented using KafkaTemplate and accepts all the properties described in Spring Boot documentation. This allows you to set the list of kafka servers by setting property spring.kafka.bootstrap-servers.
Process event Spring Boot add-on uses three topics: kogito-processinstances-events, kogito-usertaskinstances-events and kogito-variables-events.
Kogito also allows you to disable publishing on any of these three channels by setting one or more of these properties to false: kogito.events.processinstances.enabled, kogito.events.usertasks.enabled and kogito.events.variables.enabled.
For example, in case you want to publish task events, but are not interested in variables or process events, you will add to application.properties
kogito.events.processinstances.enabled=false
kogito.events.variables.enabled=falseConclusion
We have seen how to configure messaging and process event add-ons to publish and consume Kafka records for Quarkus and Spring Boot. In upcoming post we will discuss how to change the payload format of Kafka record value from default JSON Cloud Event to Apache Avro.
The post Kogito Process Eventing Add-ons appeared first on KIE Community.