
Kogito, ergo Rules — Part 2: An All-Encompassing Execution Model for Rules
Blog: Drools & jBPM Blog

This is the second post of a series of updates on the Kogito initiative and our efforts to bring Drools to the cloud. In this post we delve into the details of rule units and show you why we are excited about them.
An All-Encompassing Execution Model for Rules
If you’ve been carefully scrutinising the Drools manual looking for new features at every recent release, you may have noticed that the term rule unit has been sitting there for a while, as an extremely experimental feature. In short, a rule unit is both a module for rules and a unit of execution—the reason why we are not calling them modules is to avoid confusion with JVM modules. In Kogito, we are revisiting and expanding upon our original prototype.
A rule unit collects a set of rules together with the description of the working memory such rules act upon. The description of the working memory is written as a regular Java class, with DataSource fields. Each data source represents a typed partition of the working memory, and different types of data sources exist, with different features. For instance, in the following example we used an append-only data source, called data stream.
Rules of a given rule unit are collected in DRL files with the unitdeclaration
Each rule in a unit has visibility over all the data sources that have been declared in the corresponding class. In fact, the class and the collection of DRL files of a unit form a whole: you can think of such a whole as of one single classwhere fields are globals that are scoped to the current unit, and methods are rules. In fact, the use of fields supersedes the use of DRL globals.
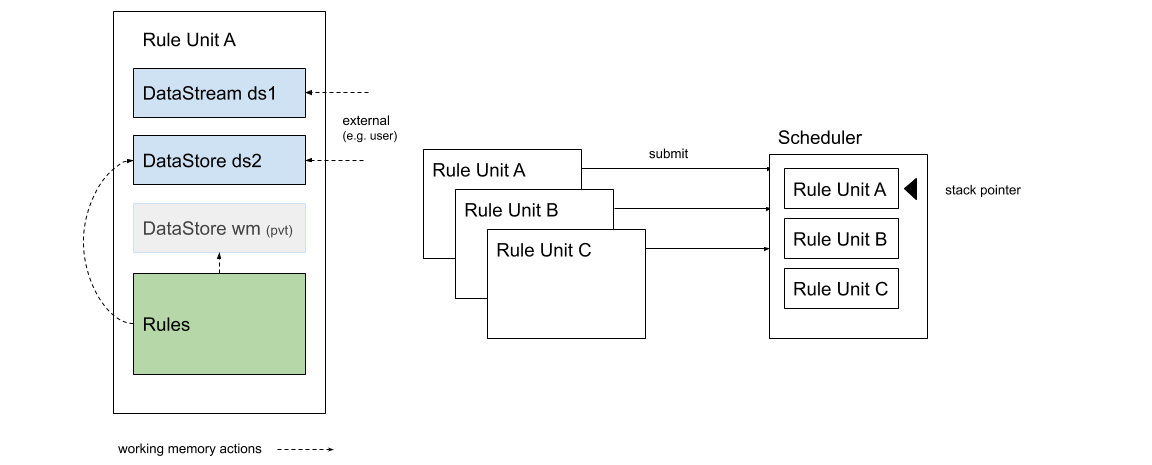
A rule unit is submitted for execution to a scheduler. Rule units may decide to yield their execution to other rule units, effectively putting them into execution. For instance:
But rule units may be also put in a long-running state. In this case, other rule units may be run concurrently at the same time; because DataSources can be shared across units, units can be coordinated by exchanging messages.
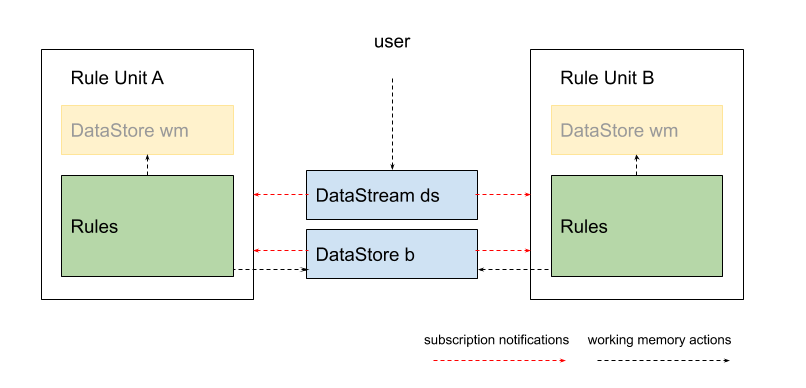
Consider the following example:
In a certain way, rule units behave as “actors” exchanging messages. However, in a very distinctive way, rule units allow for much more complex chains of executions, that are proper to rule-based reasoning. For instance, consider this example from Akka's manual:
As you can see, pattern matches in Akka are strictly over single messages. This is unsurprising, because actors process one message at a time. In a rule engine, we are allowed to write several rules, reacting upon the entire state of the working memory at the execution time: this significantly departs from a pure actor model design, but at the same time gives a great deal of flexibility in the way you may write the business logic of your application.
Data Sources
It is worth to spend a few words on data sources as well. The data source construct can be seen as both a partition and an abstraction over the traditional working memory. Different kinds of data sources will be available: full-featured data stores may support to add, remove and update values, allowing for more traditional operations over the working memory; while the more constrained append-only data streams would be easier to integrate with external data sources and data sinks, such as Camel connectors; such constraints would be also valuable to enable more advanced use cases, such as parallel, thread-safe execution and persisted shared channel (e.g.: Kafka) across nodes of an OpenShift cluster, realizing a fully distributed rule engine.Kogito: ergo Cloud
The parallel and distributed use cases are intriguing, but we need to get there with baby steps.However, this does not mean that the first steps won't be as exciting in their own way.
For Kogitowe want to stress the cloud-native, stateless use case, where control flow is externalized using processes and, with the power of Quarkuswe can compile this into super-fast native binaries. This is why in the next few weeks we will complete and release rule units for automated REST service implementation.
In this use case, the typed, Java-based declaration of a rule unit is automatically mapped to the signature of a REST endpoint. POSTing to the endpoint implies instantiating the unit, inserting data into the data sources, firing rules, returning the response payload. The response is computed using a user-provided query. For instance, consider this example:
Users may post events using the auto-generated /monitoring-serviceendpoint.
the reply will be the result of the query. In our case:
Cloudy with a Chance of Rules
We have presented our vision for the next generation of our rule engine in Kogito and beyond. The stateless use case is only the first step towards what we think will be a truly innovative take on rule engines. In the following months we will work on delivering better support for scheduling and deploying units in parallel (local) and distributed (on Openshift), so stay tuned for more. In the meantime, we do want to hear from you about the direction we are taking.
The future of Drools is cloudy… and bright!