KNIME + Spotfire
Blog: The Tibco Blog
TIBCO Spotfire and KNIME make great technology partners and are tightly integrated. KNIME adds additional power to the Spotfire platform by adding capabilities to Spotfire’s already powerful toolbox of data wrangling and advanced statistics. Spotfire adds visualization and data analysis capabilities to KNIME, enabling easy sharing of analytic applications for end users. Combining the products produces an overall solution that greatly exceeds the sum of its individual parts.
For those of you new to KNIME, it is a modern data analytics platform that allows users to perform sophisticated statistical analysis and data mining to analyze trends and predict results. Its visual workbench combines data access, data transformation, initial investigation, and data science capabilities.
In this blog, I will share the highlights from the KNIME Spring Summit in Berlin, along with a number of examples of how KNIME and Spotfire are integrated, with discussion of the benefits that the combination delivers.
The KNIME Spring Summit
The summit showcased to KNIME users what’s new in KNIME and how KNIME is enabling the citizen data scientist. That is, the business data scientist user. The summit was the largest yet at nearly 300 attendees from diverse industries.
Topics covered included data blending, guided analytics, scalability, big data, and cloud. Data blending is KNIME’s terminology for combining different types of data, for example, blending imaging data with text analytics. A number of interesting industry use cases were demonstrated, along with new functionality that makes data blending easier and more powerful than ever before.
Guided analytics was covered with the Workflow Coach. The Workflow Coach uses usage statistics collected via the KNIME community to recommend the most suitable nodes for your workflow. A simple example was shown live and a word cloud visualization was made from scratch in a few seconds. A second example built a predictive model using a decision tree learner and predictor and showed how KNIME is making it easy to use data science. It was likened to putting a business analyst in the driver’s seat—but wearing a seatbelt!
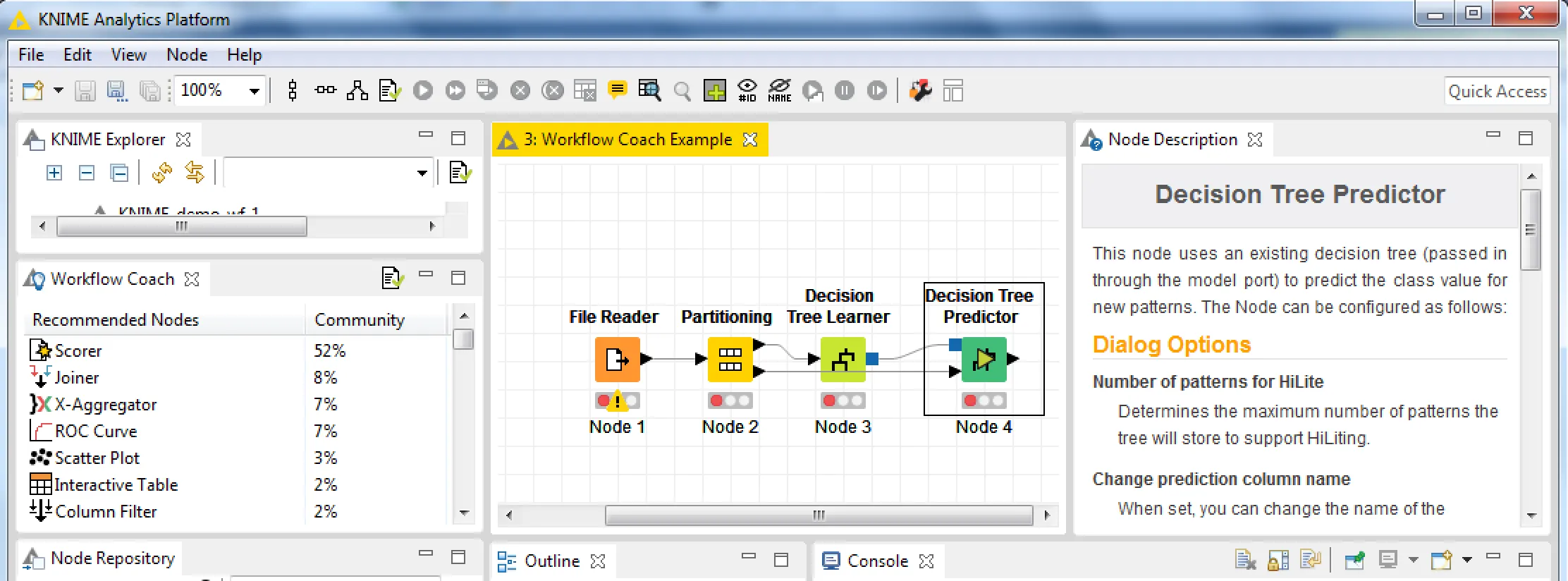
The screenshot shows the building of the decision tree model. The Decision Tree Predictor is selected and the Workflow Coach shows that the Scorer node is the next recommended node to be used.
The KNIME model factory was also demonstrated. It’s estimated that, in most organizations, a data scientist can maintain around four models concurrently, before becoming saturated with work. The KNIME model factory simplifies the mechanisms for publishing, monitoring, and automatically re-learning models when they become outdated. This frees up the data scientist to develop more models and to be much more productive than would otherwise be possible.
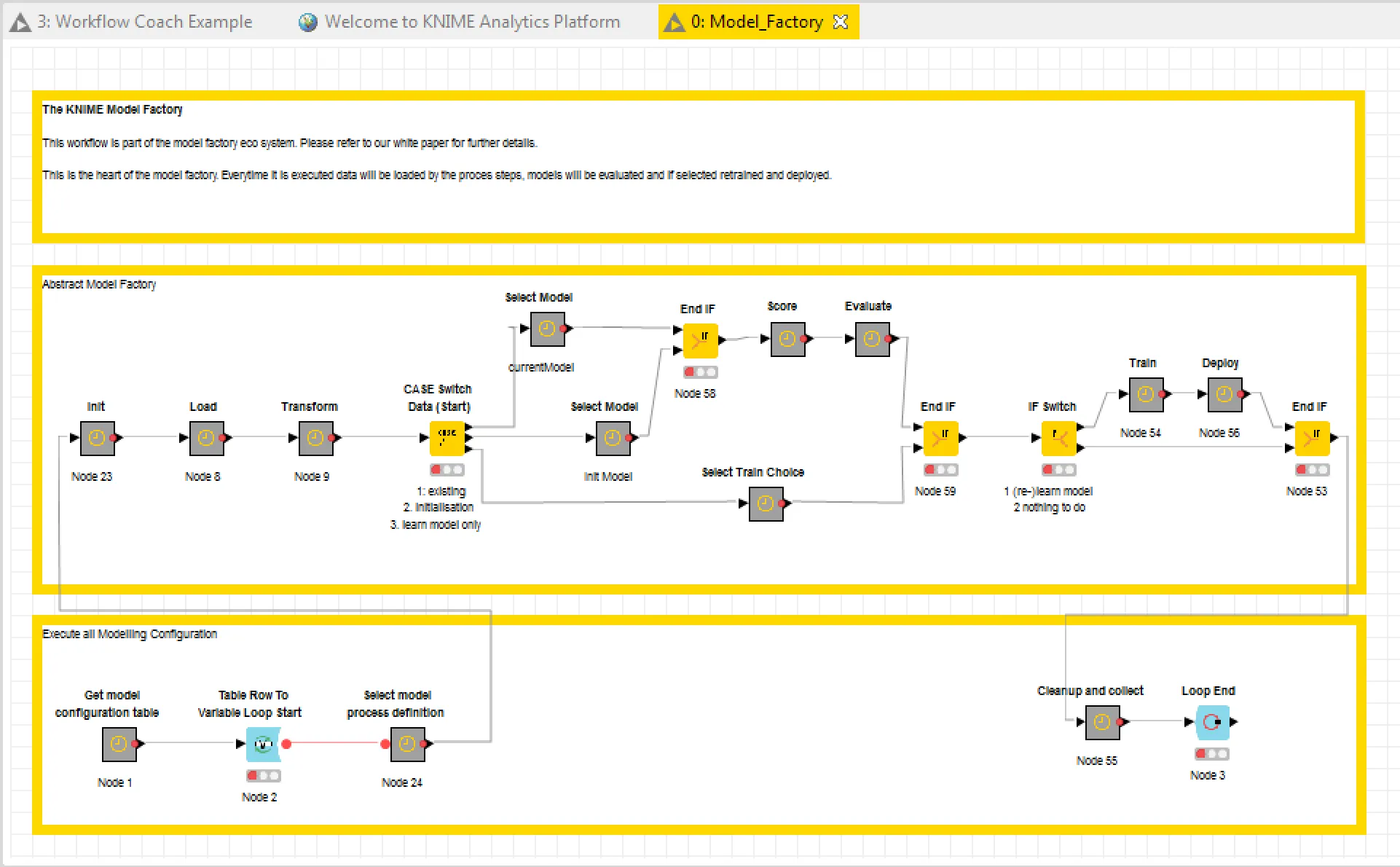
TIBCO Spotfire and KNIME integration
Now, I will introduce and explain some examples of how KNIME and Spotfire can be used together.
File reading and writing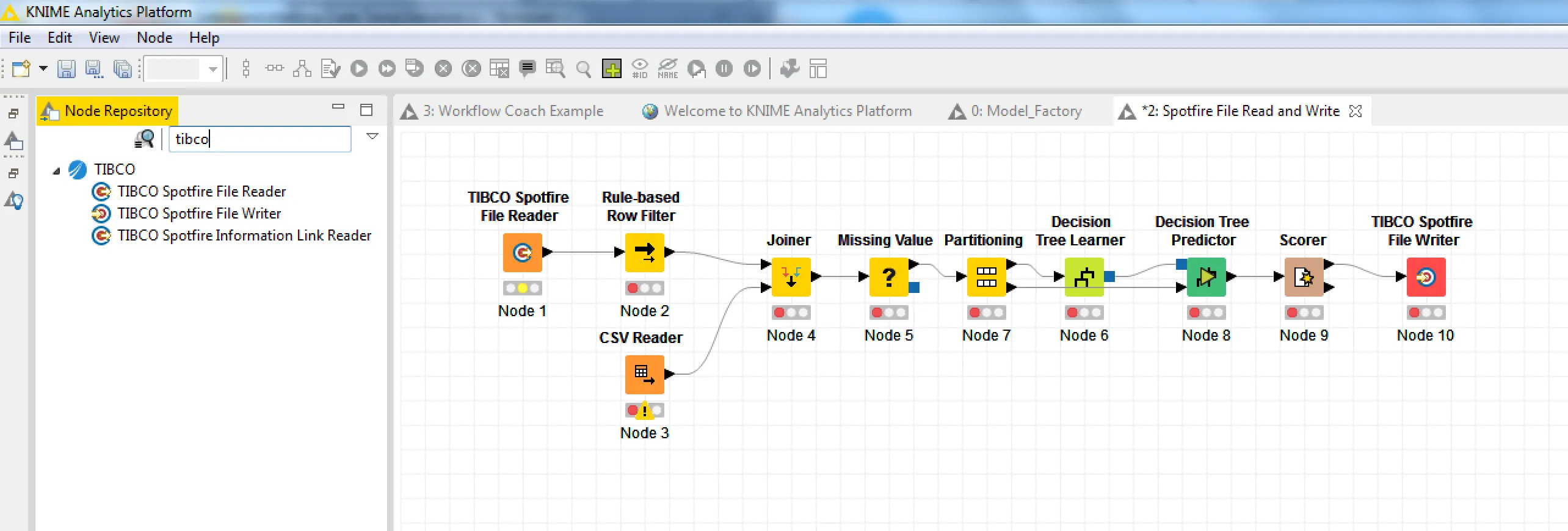
KNIME can be used to mash up data, perform ETL operations, and statistical analysis to prepare business data for analysis in Spotfire. Native Spotfire file read and write capability is enabled by way of reader and writer nodes. The nodes read or write files to/from a file system or to/from the Spotfire library—more on that later.
Native files? Yes! The advantage of native Spotfire files is that they don’t need importing into Spotfire, nor do they need importing into KNIME. SBDF (Spotfire Binary Data File) files have a lot of advantages over Excel or CSV or other flat files. In fact, some people use them for purposes other than Spotfire, like storing lab instrument data, for example. SBDF files are compressed and are strongly typed. This means that the columns have data types, unlike Excel or CSV. Each column is assigned a data type when the file is written: string, real, date/time, etc.
Reading and writing to and from the Spotfire library—putting the data in your hands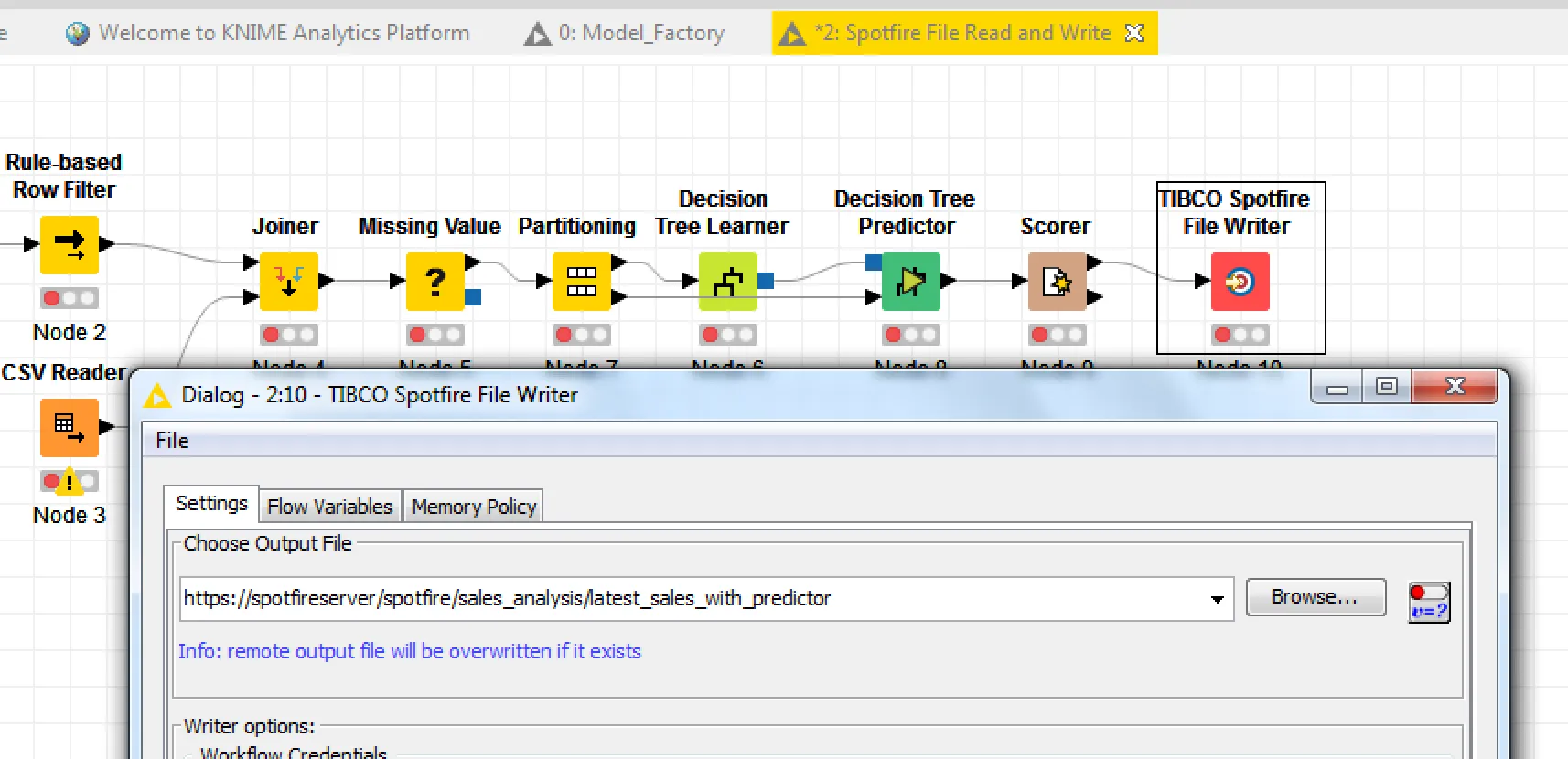
This is probably the most powerful part of the Spotfire and KNIME integration. Business users really love using KNIME to manipulate their data because they know their data best. Once they have developed a workflow to suit, they can write their data to the Spotfire library directly using the Spotfire file nodes. From there, everyone else in the organization can take advantage of the data and use it to build analyses or to further manipulate or augment the data in KNIME. The Spotfire library becomes a data sharing platform, enabling collaboration and rapid evolution of business analysis, without the need for a warehouse or database for every single use of data.
Data files can be loaded into a Spotfire file, or opened in Spotfire Business Author. KNIME can be run on a scheduled basis to keep files up to date, which means that analysis files will always have the latest data.
Information link reader
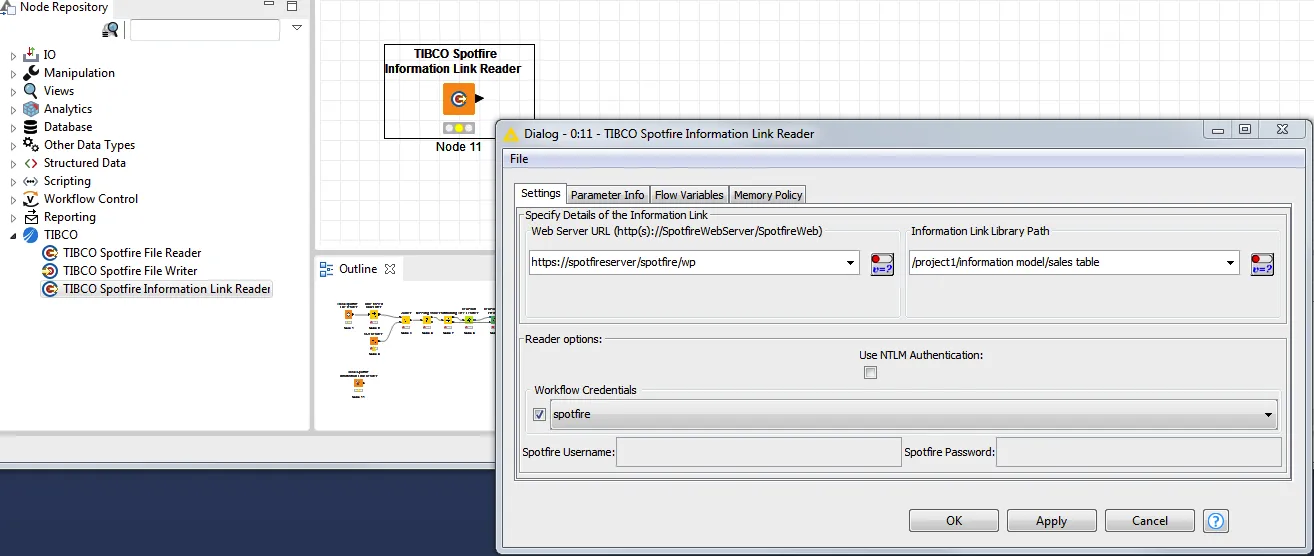
Spotfire’s information links are a database abstraction layer—they allow access to databases to be centrally controlled and managed, with controlled permissions, joining, querying, and stored procedure execution. Using the Spotfire KNIME information link reader, you can use the power of the information links from within a KNIME workflow to read data from your organization’s databases and use the data in a workflow.
Interactive KNIME from Spotfire
The KNIME/Spotfire connector, distributed by TIBCO’s partner EPAM (InfomatiX), allows Spotfire to interactively call a KNIME workflow. It can be used to send data and parameters to a workflow, which then returns data to Spotfire for further analysis, all with a click of a button, in a similar fashion to TIBCO Spotfire Statistics Services. This brings KNIME analytics capabilities to Spotfire.
Give Spotfire a try for free here. Want to learn more? Links to all topics discussed can be found on the TIBCO Community and the KNIME web pages:
https://community.tibco.com/wiki/knime
https://tech.knime.org/whats-new-in-knime-32#workflowcoach
https://www.knime.org/files/spring-summit2017/Model%20Process%20Management%20PRINT%20FINAL.pdf
https://www.knime.org/spring-summit2017
http://infomatix.net/spotfire-extensions/ix-knime-spotfire-integration/