Keynote from Google Research on Building Knowlege Bases at #ICWE2016

- largest share of the content comes from DOM structured documents
- then textual content
- then annotated content
- and a small share from web tables
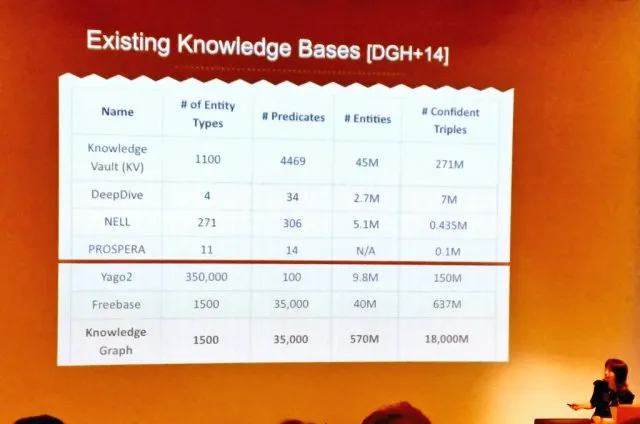
Knowledge Vault is a matrix based approach to knowledge building, with rows = entities and columns= attributes.

- triple identification
- entity linkage
- predicate linkage
- source data
Besides general purpose KBs, Google built lightweight vertical knowledge bases (more than 100 available now).
When extracting knowledge, the ingredients are: datasource, extractor approach, the data items themselves, facts and their probability of truth.

Several models can be used for extracting knowledge. Two extremes of the spectrum are:
- Single-truth model. Every fact has only one truth. We trust the value of the highest number of datasources.
- Multilaeyer model. separates source quality from extractor quality and data errors from extraction errors. One can build a knowledge-based trust model, defining trustworthiness of web pages. One can compare this measure with respect to page rank of web pages:

In general, the challenge is to move from individual information and data points, to integrated and connected knowledge. Building the right edges is really hard though.
Overall, a lot of ingredients influence the correctness of knowledge: temporal aspects, data source correctness, capability of extraction and validation, and so on–
In summary: Plenty of research challenges to be addressed, both by the datascience and modeling communities!
To keep updated on my activities you can subscribe to the RSS feed of my blog or follow my twitter account (@MarcoBrambi).
