How to scale your Big Data solution with an industrialized approach
Blog: Capgemini CTO Blog
What has prompted this shift? And what key challenges must technology leaders address to ensure their industrialized Big Data truly yields dividends for the business?
From experimentation to industrialization
The potential for data to generate value is undeniable. Over the past few years, numerous minimal viable products (MVPs) and proofs of concept (POCs) have proved the positive impact of data centralization and use, whether to improve efficiency, find new business models, answer new regulatory constraints, or avoid disintermediation.
Now we’re moving into the next phase where the full value of data can only be realized if organizations implement their data use cases at scale. Of course, this requires huge investment and significant shifts at technological, organizational and cultural levels. This transformation has become a top priority for CxOs and notably CIOs.
So, the pressure is on the CIO to deliver business value at scale. After years of uncoordinated experimentation, by both business (MVPs) and IT (POCs), it’s time to standardize enterprise Big Data solutions. This means integrating specific solutions directly bought by the business (Dataiku, Thoughtspot, SAS) while creating the indispensable transversal data capabilities (ingestion, storage, processing and exposition) to deliver at scale. Indeed, research suggests that we are now on a Big Data transformation wave, with the market projected to grow from $17.1 billion in 2017 to $99.3 billion in 2022. (Source: Statista).
In taking this step from experimentation to industrialization, the first critical consideration for CIOs concerns architecture. More than ever, decisions taken on data architecture will either enable or limit value at scale. Those decisions will also be vital in accurately figuring out the data profiles and skills needed for both the design and implementation phases. Further, beyond the data profiles and skills needed, implementing a new data architecture has a significant impact on the whole Data Operating Model, including new Agile ways of working, for which it is an appropriate trigger.
Tackling the data architecture challenges
There is an exciting journey ahead for CIOs as they implement the architecture of tomorrow. One that’s able to support a large diversity of use cases in the next 5 to 10 years. Getting there, however, will not be without a number of challenges.
- Challenge 1: How to ensure the business delivers a mature vision of disruptive use cases for Big Data
The different needs and ambitions of enterprise business units are typically diverse. This can make it painful for CIOs to get the full picture of the disruptive Big Data use cases needed to support growth ambitions for the coming years. Yet, despite this fractured business vision, CIOs typically already have a good idea of the generic use cases for digital data capabilities (data visualization, reporting, data preparation, data science, etc.) so should quickly identify and build these in order to spend more time and brain power on understanding the core-business use cases that require specific capabilities.
- Challenge 2: Decide on the number of platforms to implement – and convince the business
CIOs often have to contend with lines of business expecting their own data platforms for faster go-to-market, and with an evolving information system, especially the applications/front-ends in order to answer new business and clients’ needs. But, of course, this contradicts IT’s focus on rationalization and cost containment. CIOs also know that giving each business unit a unique platform is an unachievable dream because it relies on too many compromises (data access, data diversity with structured/semi structured/unstructured data, performance, real time, time-to-market (TTM), delivery acceleration, etc).Nonetheless, while segmentation is unavoidable, CIOs need to propose a consistent segmentation. Thus, they must be pragmatic. They first need to unite business users around capabilities and service offer (file ingestion, API management, data catalog, key/value store …) instead of data solutions/technologies. Then use cases should be segmented amongst different data platforms, notably through the two axis of analytics platforms (Finance, Risk & Compliance, Marketing, etc.) vs transactional platforms (customer facing, e-commerce, etc.). Finally, fluid data exchanges between platforms (API, extract/load/transform) have to be anticipated to make them interoperable in order to avoid duplication and achieve a single version of truth.
- Challenge 3: Decide on the move-to-cloud strategy (and implementation solutions) for each platform
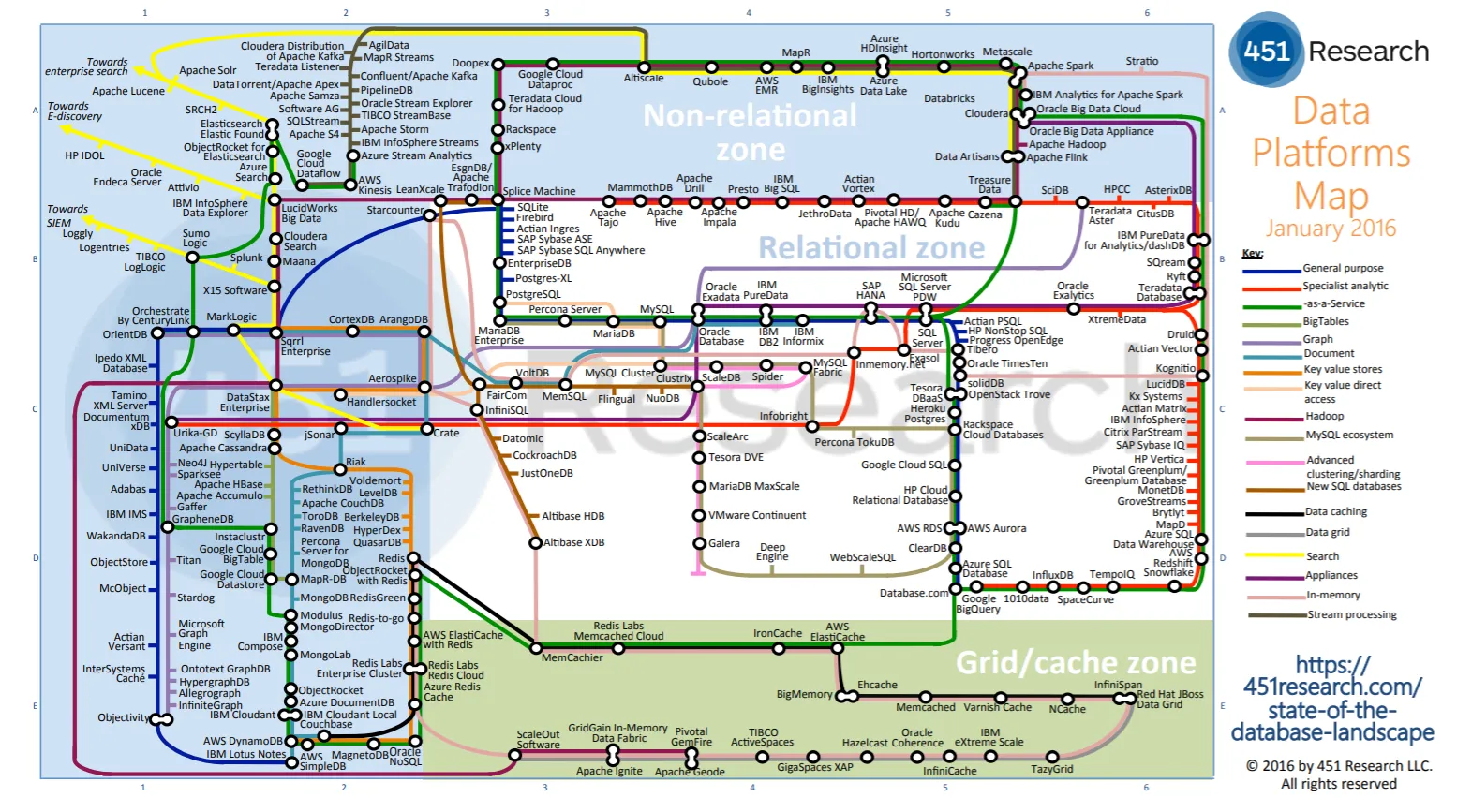
The Big Data solution landscape is fast moving and not yet consolidated. How does today’s CIO navigate the jungle of solutions and definitions of consistent service – with more than 300 solutions currently available?
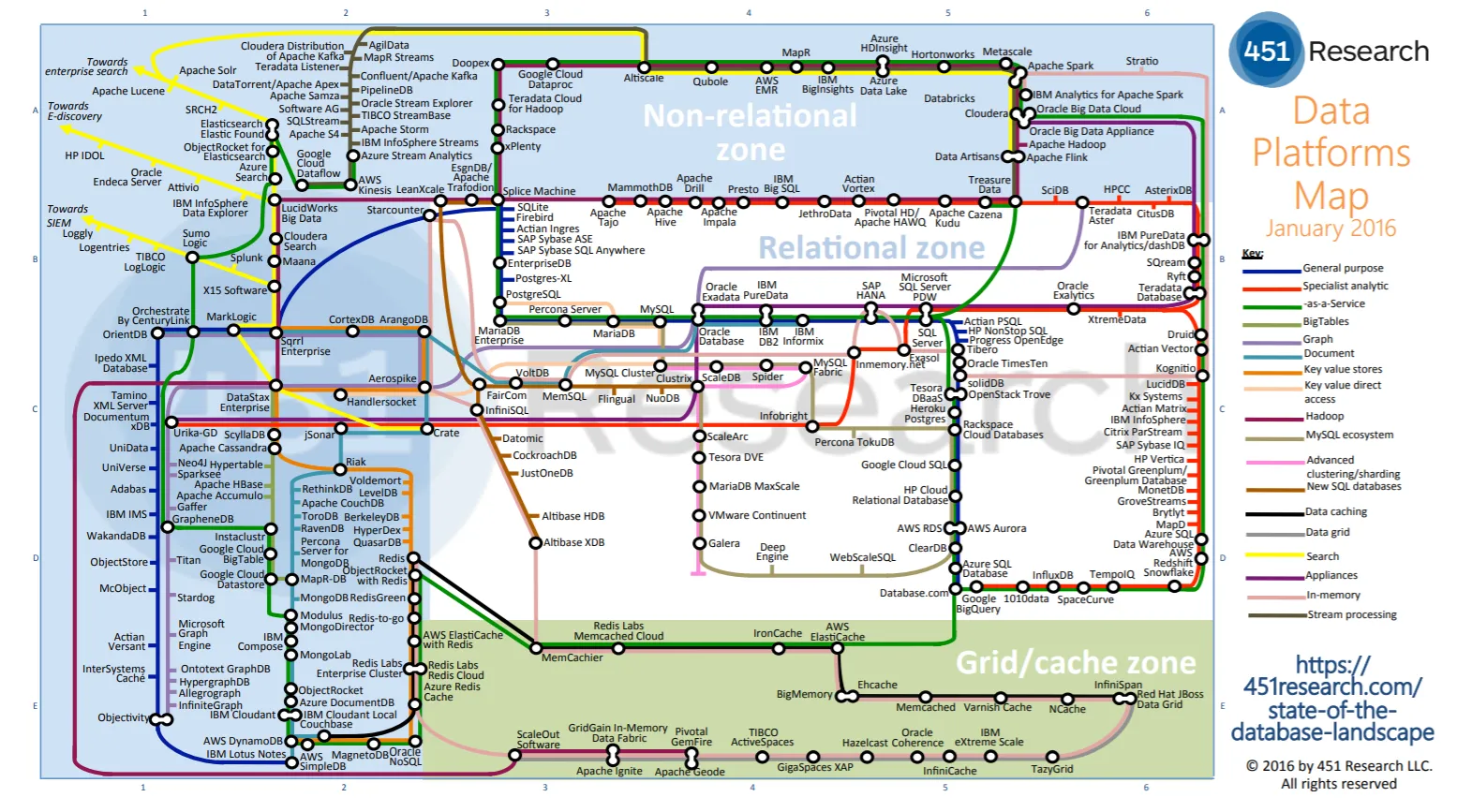
In the event of a move to cloud, the choice of the cloud provider will invariably condition the available solutions and can significantly accelerate solution TTM. If opting to remain with an on-premise data solution, then a different set of questions must be answered. These will include whether to go for a data lake or a data warehouse, or to choose the coexistence of both relational and non-relational data landscapes? Another question might concern the extent of specific developments vs packaged solutions. In this instance, a CIO might leverage a packaged solution to accelerate adoption. There will, of course, be certain use cases that are not supported by a packaged solution, or instances when this approach ends up being more costly in the long term. This is when a solution tailored specifically to the use case may prove the best option in terms of cost and efficacy.
At one time, Hadoop was the de rigueur open source data storage and applications choice. But it has had its glory days and is no longer the only option for Big Data. Several Big Data editors, cloud providers and open source solutions can now provide best-of-breed solutions – Snowflake is a good example of this combination. Here, different key criteria must be taken into account to shape the solution choice:
- Non-functional requirements, such as data volumes to ingest/process and expected response-time, entail specific performance levers to implement – extract load transform (ELT) approach instead of extract transform load (ETL), multi parallel processing in memory, optimized data before exposition, etc.
- Data variety conditions storage solutions (SQL vs non SQL)
- Elasticity constraints (e.g. punctual high consuming data processing) will strongly determine the necessity or not to move to cloud.
- Challenge 4: Educate the business on real time and micro-batch options to contain cost
Business units often ask for real-time data with no idea of the consequences in terms of architecture and costs. It is up to the CIO to educate business users on the alternatives, such as micro-batch processing supported by messaging systems that can achieve near real-time performance at a far lower cost. This will see the CIO (or data/IT team leaders) helping the business to assess if there is a true need for real-time data interaction. If there is, this can lead to a need to master complex solutions like Kafka , which are expensive due to the volume of dedicated sets of servers (clusters) on which virtual machines can be provided, and often to a move to cloud. Again, it is all down to the use cases and IT must work with the business units to ascertain if they really do need the to go down the more expensive route, perhaps if they are live streaming or need real-time interaction with customers, or if their expectations can be met by micro-batch processing.
Looking ahead
With no unique or obvious Big Data solution, choosing the right one for your organization is clearly not a straightforward task. That’s why experimenting in parallel with industrialization is a must: it allows the business to continuously find future disruptive use cases (MVPs) and IT to continuously align the data architecture (POC) with best-in-class IT standards. Experimenting first is a practical approach to assessing what the different technologies can do for you, such as streaming and storage, before choosing to scale up through industrialization. One way to keep down the cost of this experimentation is, of course, to leverage cloud where you only pay for the resources you use.
Find out more about our Inventive IT approach to Big Data here.
Authors
 Olivier Adriaens
Olivier Adriaens
Director
Capgemini Invent
 Ludovic Alonzi
Ludovic Alonzi
Senior Manager
Capgemini Invent
 Arnaud Rover
Arnaud Rover
Manager
Capgemini Invent