

How to Reduce Waste with Process Mining
This post originally appeared as a guest article in the July 2011 issue of BPTrends. You can read the original article here.
Human perception is skewed, and especially our memory can be unreliable1. This subjectivity makes it difficult to draw a complete and accurate picture of a business process when defining the As-is state of how things are done.
Computers are very good at doing complex things that can be automated. Why not use them to make sense of all the process data that have been collected by the IT systems in the company? Read on to learn how Process Mining can complement your process analysis efforts by bringing facts into the conversation.
Limitations of Manual Process Analysis
Business process improvement projects typically start with the analysis of the current As-Is situation (see Figure 1 below). Of course the goal is to arrive at a better process (in terms of quality, efficiency, etc.), and actually bringing about the change is often the hardest part. However, without an accurate picture of the As-is process it is as if you are starting a journey without knowing where you are and without an effective measure of your progress.
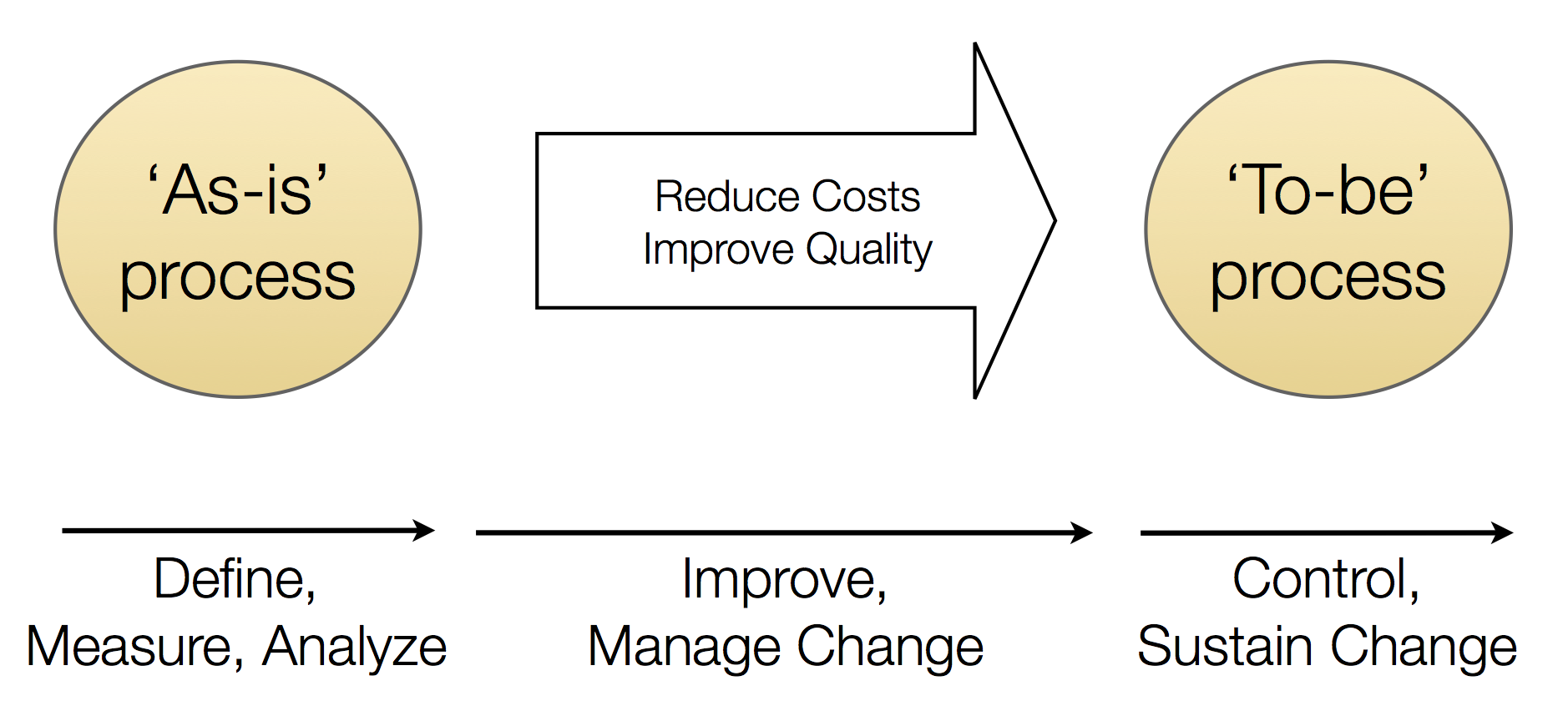
Figure 1: Process Improvement
Today, the As-is process is usually mapped out manually by workshops, interviews, observation and Walk-throughs. Some of the challenges are:
Processes are invisible
When you enter a factory floor you can see who and what is working. In an office you see people interacting with their computers, but its not clear what they are working on. Previously, a pile of paper on the desk indicated the backlog. In the IT-based information processes today it is a little harder to find out what is actually happening.
Reality is different than people think
People may say their actual process matches the description while in reality the workflow is different. Managers can have low visibility into this mismatch. Furthermore, everyone only sees a part of the process with little knowledge about what happens before and after. As a consequence, inefficiencies often emerge at the boundaries of functional units.
People have different opinions about where the problem is
Because everyone has a subjective view on what is happing, people often have different opinions about where the problem is. For example, there may be a perceptional bias on the sunny day scenario and on the exceptions. This parallax leads to a lot of wasteful discussions that could be avoided if there was a way to cross check the current thinking with factual data.
Leveraging IT Data with Process Mining
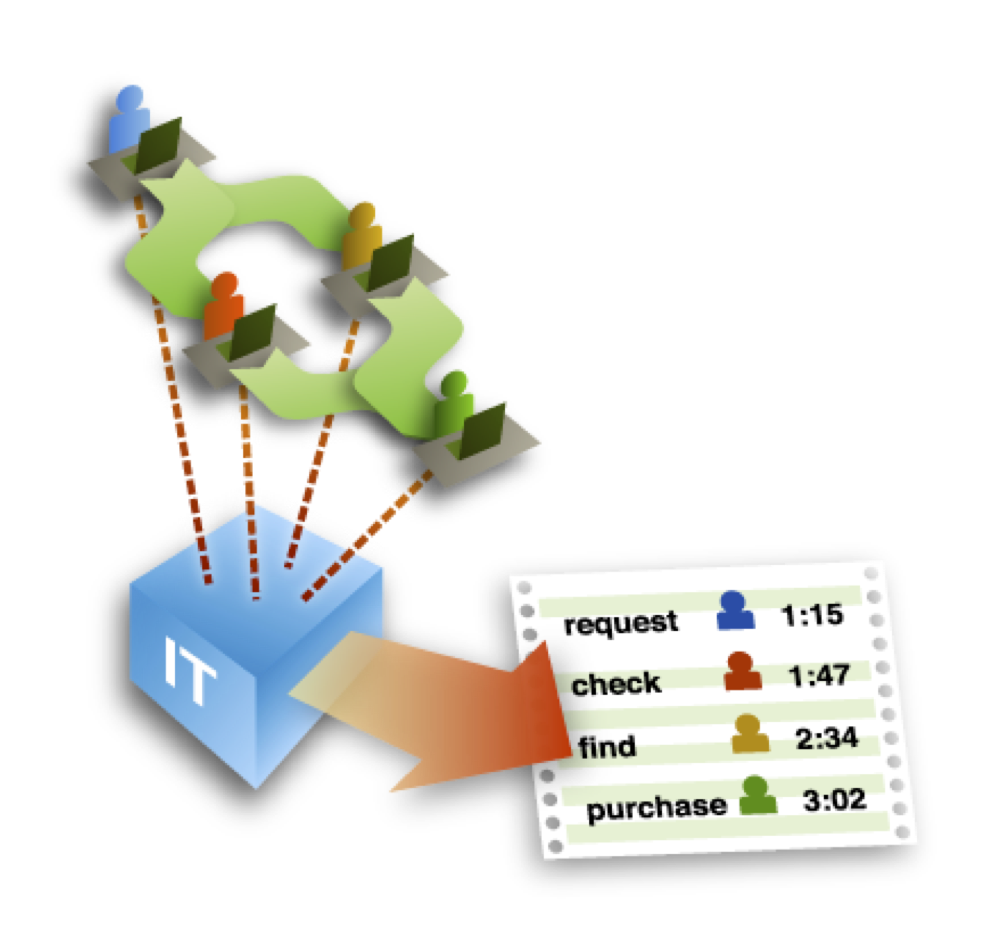
Figure 2: IT systems record very detailed information about who does what and when
IT systems such as ERP, CRM, and many other platforms support the execution of business processes today. While doing that they record very detailed information about the activities that are performed, who does them, and when (see Figure 2).

Figure 3: Process mining uses existing IT log data to automatically discover a model of the actual process flows
Process mining uses these log data to automatically discover graphical models of the actual process flows (see Figure 3). The process models can then be further enhanced by computing performance metrics, integrating an organizational perspective, and so on.
While these automatically discovered models might not cover your whole business process (for example, manual steps will be not visible in the data), they provide a valuable complement to the human work in the As-is analysis efforts.
By using process mining you can bring facts into the conversation. For example, you may show a picture of the mined process in a workshop and ask: Here is what the data seems to be saying, how does this match with your perspective and experience?
Three Examples of Waste
To make it more concrete, I want to give three examples of how process mining can be used to discover waste in a business process. Hidden factory (originally coined in an article in the Harvard Business Review2 in 1985) has become a synonym for things that actually happen in the process, but are not part of the expected process map. Hidden process steps effectively contribute to process errors and process delays. The hidden factory also accounts for wasted time in the process as well as for potentially duplicating work or tasks that are formally addressed elsewhere in the process. The main problem is that these issues are not visible and, therefore, cannot be managed properly.
Here is how process mining can help to discover hidden factory issues:
1. Hidden Activities
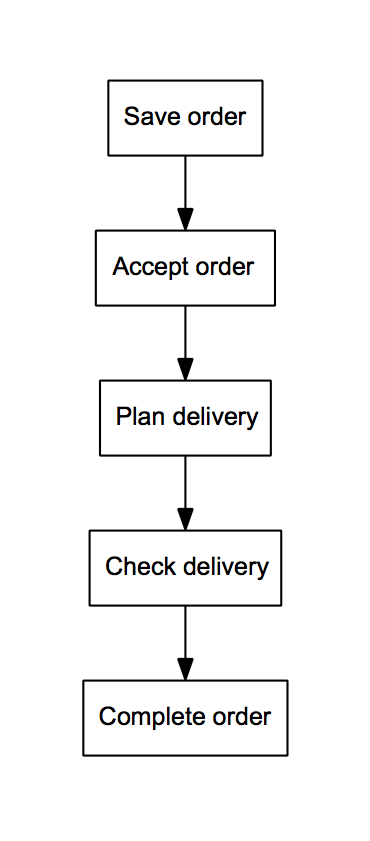
Figure 4: Planned process (Goal: 3 days)
Figure 4 shows the documented workflow for a simplified customer order process. The process seems straightforward, just a sequence of steps, and should be completed within three days. In reality, however, the process is more complex (see Figure 5) and takes six days on average, sometimes much longer.

Figure 5: Actual process (6 – up to 26 days)
The process visualization in Figure 5 was automatically generated without any a priori process description just based on the IT logs collected in the customer service platform.
One can see in Figure 5 that in fact more activities take place than are documented in Figure 4. In particular the hidden process step Request missing information seems to be relevant because very late in the process missing information is requested from the customer, which has delayed the completion of customer orders in 99 out of 364 cases.
In this example, ensuring that all relevant information is captured upfront when saving the order would greatly improve the process efficiency. Only by discovering hidden activities, can one gauge their necessity and contribution to the value created in the process.
Process mining can reveal hidden process steps. Furthermore, the frequency of how often each activity has been performed can be determined objectively and based on a large sample size: For example, millions of activities recorded over a whole year can be analyzed automatically.
2. Idle Times
Often, cases sit inactive between process steps for an unnecessarily long time. From a process efficiency point of view this is waste that should be eliminated.
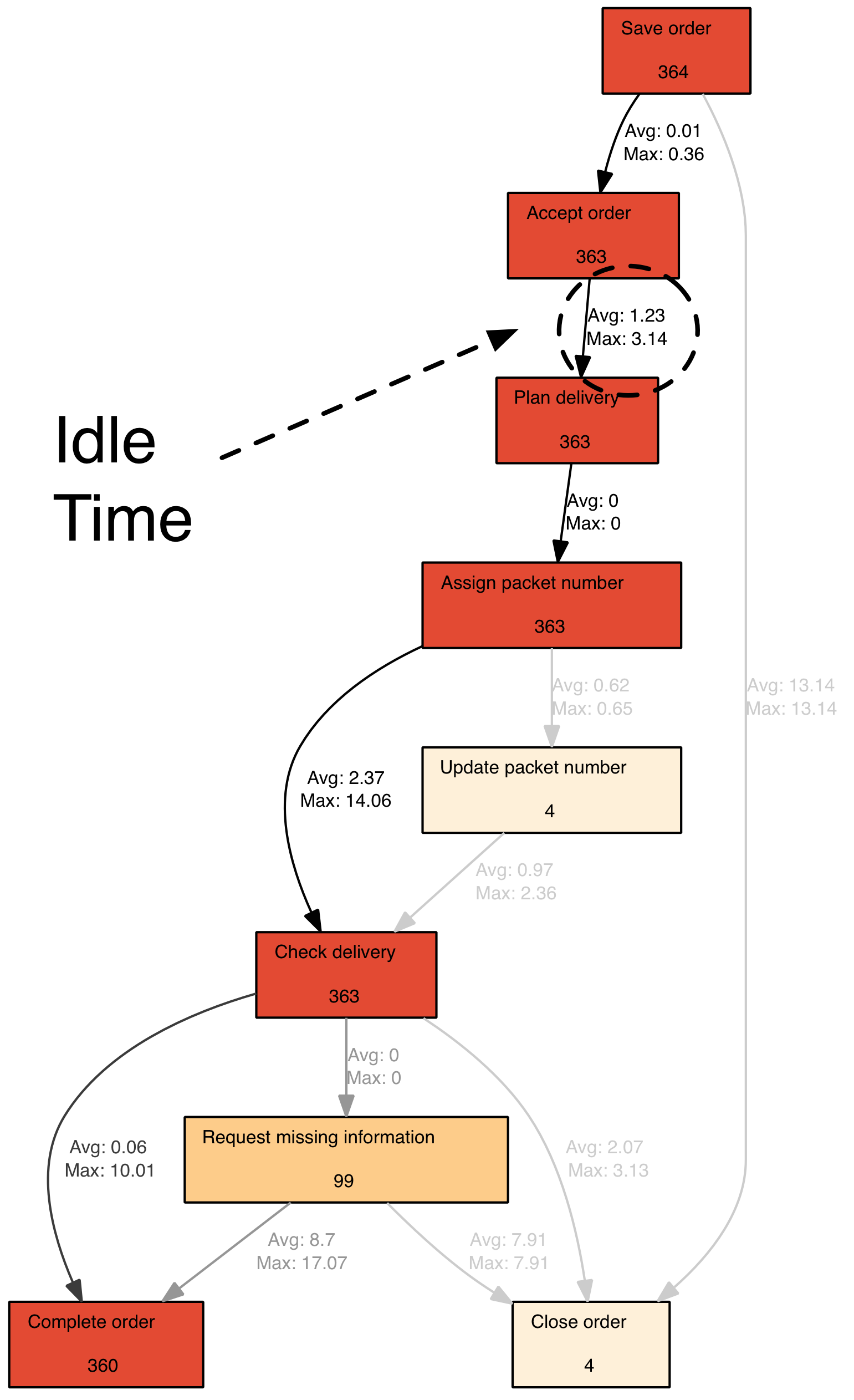
Figure 6: Long idle times can be located and further investigated (colors show frequency)
Figure 6 depicts the discovered process flow from Figure 5 with an indication of the idle time between activities (in days) at the arcs.
Because the log data in the IT systems usually carry timestamps, process mining can be used to find out how long each activity takes and where exactly most of the time is lost in the process.
3. Duplication and Variation
Usually, processes are thought of as straightforward sequences, but in reality there is much more variation. Streamlining processes by reducing variation is one way to make them more efficient and predictable.
Figure 7 shows another example from a call center process, where requests are either handled directly in the front office, or passed on to the back office or an external specialist if they are more involved.

Figure 7: Different degrees of variation in the process: The front office process has just one variant (Registered Completed) while the specialist process has a total of 38 different execution variants
One can see from the discovered process flow that in the front office requests are directly completed. In the back office there are some intermediate steps and loop-backs. However, if external specialists are involved then the process looks almost chaotic. If we were to dig deeper in the data, we would find out that some requests go to different specialists up to seven times.
Where Process Mining Fits
We have seen that besides hidden activities and idle times also the real process flows and thus their variation can be analyzed using process mining. But in which phase of your process improvement project can process mining be applied best?

Figure 8: Project phases: Where process mining fits into your process improvement project
In my view, the three main use cases are: (a) as a pre-scan to help focus subsequent efforts, (b) as a validation means to cross check the current thinking with actual data, and (c) to verify that the improvement initiative has had the desired effect (see Figure 8).
Which use case do you see as the most relevant for yourself? I would love to hear your opinions and experiences.
-
For an example of how memory can be unreliable watch this beautifully animated story of a couple re-membering the same event (This American Life: Animation from Season 2) ↩︎
-
J.G. Miller and T.E. Vollmann. The Hidden Factory. Harvard Business Review, 1985. ↩︎
Leave a Comment
You must be logged in to post a comment.






