How to Operationalize Your Data Science with Model Ops
Blog: The Tibco Blog
Just as you wouldn’t train athletes and not have them compete, the same can be said about data science & machine learning (ML). You wouldn’t spend all this time and money on creating ML models without putting them into production, would you? You need your models infused into the business so they can help make crucial decisions.
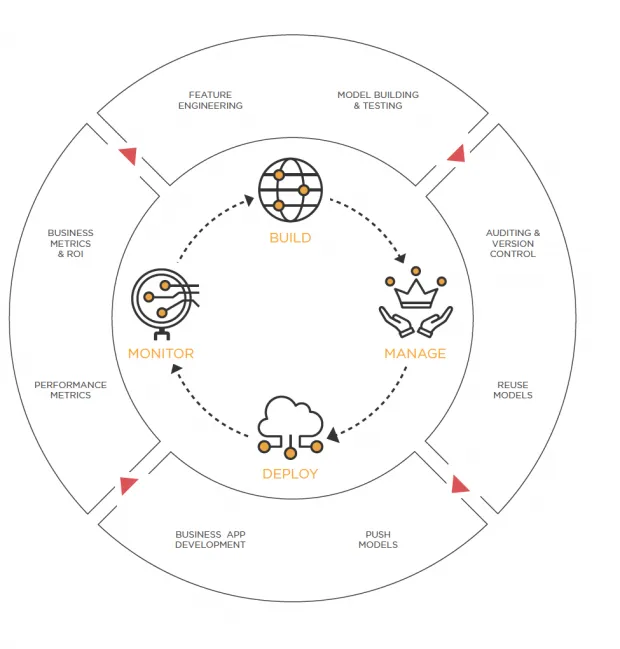
Model Operations, or Model Ops, is the answer. Model Ops is the process of operationalizing data science by getting data science models into production and then managing them. The four main steps in the Model Ops process — build, manage, deploy/integrate, and monitor — form a repeatable cycle that you can leverage to reuse your models as software artifacts. Model Ops (aka ML Ops) ensures that models continue to deliver value to the organization. They also provide critical insights for managing the potential risks of model-based decision making, even as underlying business and technical conditions change.
Model Ops is a cross-functional, collaborative, continuous process that focuses on managing machine learning models to make them reusable and highly available via a repeatable deployment process. What’s more, Model Ops encompasses various management aspects, such as model versioning, auditing, monitoring, and refreshing to ensure they are still delivering positive business value as conditions change.
Organizations need to realize the value of data science and machine learning models holistically, rather than as simply a process of developing models. While data science and ML processes are focused on building models, Model Ops focuses on operationalizing the entire data science pipeline within a business system. Model Ops requires orchestration and coordination of many different personas within an organization including data engineers, data scientists, business users, IT operations, and app developers.
In fact, many organizations have a dedicated Model Ops Engineer to facilitate this process. ML models that are people-facing must be unbiased, fair, and explainable; that is what the public demands and regulatory agencies and bodies increasingly require. For such applications, the ML Ops lifecycle must be designed to enable transparency and explainability when it comes to various risks.
The four-step approach to Model Ops
In order to solve common pain points when it comes to model operationalization — such as the long delay between initiating a data science project and deploying the model — companies are taking a four-step approach: build, manage, deploy/integrate, and monitor.
Build
Data scientists use languages like Python and R, as well as commercial applications, to create analytics pipelines. They use innovative ML algorithms, they build predictive models, and they engineer new features that better represent the business problem and boost the predictive power of the model. When building predictive models, data scientists need to consider both how the data is structured in production environments. Similarly, for feature engineering, data scientists need to make sure that any new features that are created can be created fast enough in real-time production environments.
Manage
Models have a life cycle that is best managed from a central repository where their provenance, versioning, approval, testing, deployment, and eventual replacement can be tracked. Besides the metadata associated with model artifacts, the management platform and the repository should track accuracy metrics as well as dependencies between models and data sets.
Deploy/Integrate
A data science pipeline is taken from its original development environment and expressed in a form that can be executed independently and integrated into business applications. In the end, you need to be able to deploy the pipeline in a format/language that is appropriate to the target runtime environment.
Monitor
After a model has been deployed, it is monitored for the accuracy of its predictions and impact on the business. The model needs to remain accurate even as the underlying data changes. This takes into account input from a human expert, or automatically, through ongoing retraining and champion-challenger loops with approval by a human, for example.
Realize the value of data science through Model Ops
By utilizing this four-step approach, organizations can realize the value of data science through Model Ops. It ensures that the best model gets embedded into a business system and that the model remains current. And companies that practice this have a big competitive advantage over those that consistently fail to operationalize models, and who fail to prioritize action over mere insight. Organizations can move beyond merely building models to truly operationalizing their data science usage.
Learn more about how to operationalize your data science by downloading this ebook.