

How To Determine The Start and End Points For Your Process

This is the second article in our series on how to deal with incomplete cases in process mining. You can find an overview of all articles in the series here.
Once you start analyzing your data set for incomplete cases, you need to determine what the expected start and end points in your process are. Typically, you do this by looking at which activities appear to be the last step in the process (look at the dashed lines in your process map) and by using your domain knowledge about the process.
In the refund process, we have already identified one possible regular endpoint in the activity Order completed. But are there other regular end points as well? For example, by digging deeper in the data we find that there is another activity Cancelled that also appears as the last step in the process. From the name Cancelled we can guess what this step means (the processing of the refund order has been stopped). The question is whether we consider Cancelled a regular end point in the process, or whether we would rather remove cancelled cases from our process analysis?
The answer to this question depends on the questions that you want to answer in you process mining analysis. Furthermore, you typically need domain knowledge to definitively clarify how the process end points should be interpreted. It is fine for you as the process analyst to take some initial guesses, but it is critical that you document your assumptions along the way and verify them with a domain expert later on (see Data Validation Session).
If you have no idea at all which activities could be candidates for a start or end point in your process, there are two tricks you can try out to see if they help:
- Work from the process map and click on one of the dashed lines leading to the endpoint (see Figure 1). If the case frequency is the same as the end frequency (or very close) then this is a hint that the activity might be an end point in the process, because there is never anything happening afterwards. The same can be done with the start activities by clicking on the dashed lines leading from the start point.
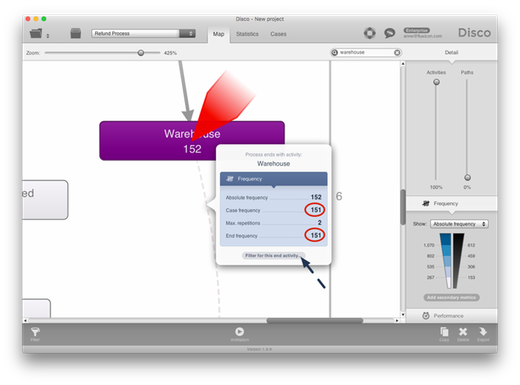
Figure 1: Click on the dashed line and press the Filter for this end activity… button to investigate the cases that end in a certain place.
To investigate some example cases with a particular end point in more detail, click on the shortcut Filter for this end activity and apply the pre-configured Endpoints filter that Disco has added.
a) If you should decide that this activity is a regular end point in the process, remove the filter again from the filter stack, apply the updated filter settings, and continue looking at the next dashed line in the process map.
b) If you should decide that cases that end with this activity are incomplete, invert the selection of the Endpoints filter and apply it to remove all cases that end there. Then, continue looking at the remaining data set and click on the next dashed line in the process map.
By gradually removing end points that you consider incomplete, more and more end points that are currently hidden due to the low Paths slider will appear until you have investigated all endpoints (keep pulling up the Paths slider until you have seen them all) and have decided which to keep and which to remove.
- The second trick only works if you have data covering a large enough timeframe compared to the case durations in your data set. But if you do, try to apply a Timeframe filter before investigating the start and end points as described above in the following way:
To investigate the process endpoints, add a Timeframe filter and cover the first half of the timeframe (see Figure 2). As a result, only cases where there has been no further activity for the latter half of the time of your data set remain. Therefore, the end activities that are revealed through the dashed lines leading to the end point in the process map are much more likely to be actual endpoints in the process. In a way, you can think of it as having excluded those cases that just performed some kind of intermediary step yesterday, or a few days before the end of the data set.
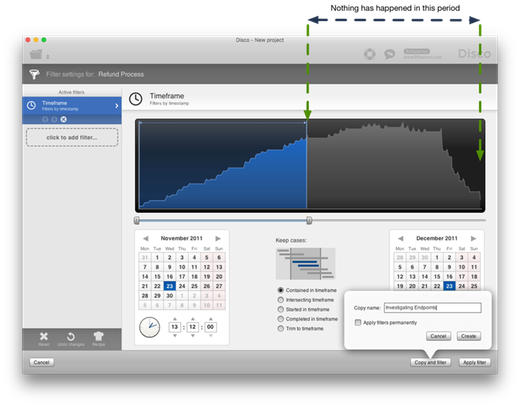
Figure 2: Filter for cases that have been inactive for a certain amount of time.
To investigate the process startpoints, you can do the same but configure the Timeframe filter in such a way that it covers only the latter half of the timeline. This way, start points that emerge only because cases have been started shortly before the start of the data set timeframe will be excluded.
Leave a Comment
You must be logged in to post a comment.






