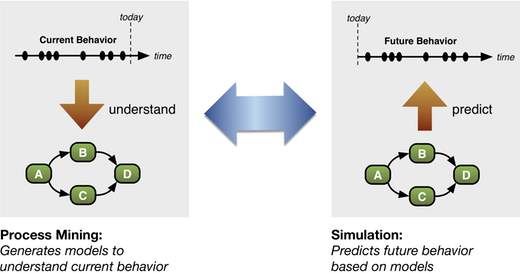

How Process Mining Compares To Simulation
Sometimes I see that people mix up process mining and simulation. So, what’s the difference?
Process Mining
Process mining is all about understanding the current ‘as-is’ processes. The IT systems record very detailed information about which activities are performed, when, and by whom. By leveraging these log data, fact-based models can be generated that show the actual process behavior from various angles1.
Simulation
Simulation is about playing out alternative ‘to-be’ scenarios. This is done based on a model, which is usually manually created. The model first reflects the current process and is then modified to estimate the eventual real effects of changes (e.g., redesign alternatives in the process) before they are actually implemented.
The difference
This reverse relationship between models and behavior leads to the fact that process mining does not suffer from two problems that simulation has:
-
The usefulness of simulation stands and falls with the validity of the model. This means that all relevant influences on the process behavior need to be known and captured. For simple and stable processes this can work, but for many complex processes it comes close to “modeling the world”.
In process mining, bottlenecks and problems do not need to be known in advance. They can be observed and investigated based on factual data. “Why is work always accumulating before activity X?” The root causes may lie in the incentive structure, people issues, overload, or the weather.
-
In simulation, everything needs to be captured in a single model. In addition to the requirement of being “complete” this adds to the complexity because it is always easier to model different aspects of a process in isolation instead of all the interdependencies.
In process mining, multiple models can be generated to gain insights into different perspectives of the process (process flow, organizational, data flow, and so on). These models can be separate and just as detailed as they need to be to better understand the problem.
Combining both?
In an old blog post Bruce Silver wrote about features in simulation tools that are essential to make good models. But another problem is to come up with all the information needed to populate the simulation model in the first place.
Simulation can greatly benefit from process mining because process mining can deliver the parameters needed to fill the model (actual process flows, execution times, waiting times, utilization levels, distribution of arriving new cases, etc.) based on factual information. This way, process mining can help to build more accurate and better simulation models.
However, modeling (and thus simulating) human behavior is hard2. Furthermore, in my view it is often not necessary to build a simulation model to estimate the impact of a process change.
Have you seen simulation working out or failing?
-
In process mining, an animation is a replay of past behavior as it actually happened (for example, as a means to communicate a detected bottleneck). This is not simulation. ↩︎
-
If you are interested in process mining and simulation, I recommend to take a look at this paper and chapter 8 and 9 in my dissertation for further reading. ↩︎
Leave a Comment
You must be logged in to post a comment.






