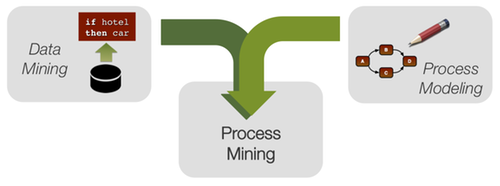

How Process Mining Compares to Data Mining
You may remember that, in my last post I have sketched the differences between process mining and business intelligence. Another way to position process mining is to compare it to data mining. There are lots of data mining tools that are used to support business decisions in specific areas (for example: which products should be placed together in the supermarket, or: where you should send your marketing flyer), but they do not work well for processes.
At the same time, organizations spend lots of money on modeling processes. Because the process modeling is done manually, these models are quickly becoming outdated and out of touch with reality – and so they often they end up as dead piles of paper that have no value.

In my opinion, process mining technology combines the strengths of both data mining and process modeling: By automatically creating process models based on existing IT log data, process mining yields live models that are connected to the business and can be updated easily at any point in time.
Huge amounts of data
Process mining has more in common with data mining than just the “mining” part: Just like data mining, process mining takes on the challenge to process large volumes of data that simply cannot be evaluated by hand anymore.
Enterprise IT systems collect more and more data about the business processes they support. These data usually reflect very closely what happened in “the real world” and can be a great source of insight for understanding and improving the business.
Process perspective
Unlike data mining, process mining focuses on the process perspective: It includes the temporal aspect and looks at a single process execution as a sequence of activities that have been performed.
Most data mining techniques extract abstract patterns in the form of, for example, rules or decision trees. In contrast, process mining creates complete process models, and then uses them to precisely highlight where the bottlenecks are.
Also exceptions are important
In data mining, generalization is very important to avoid what is called “overfitting the data”. This means that one wants to strip away all the examples that do not match the general rule.
In process mining, generalization is also necessary to deal with complex processes and understand the main process flows. However, understanding the exceptions is often important to discover inefficiencies and points of improvement.
Focus on discovery
In data mining, models are often trained to make predictions about future similar instances in the same space. Quite a few data mining and machine learning methods operate as a “black box” that spills out predictions without the possibility to trace back the “why”.
Because today’s business processes are so complex, accurate predictions are often unrealistic. The gained knowledge and deeper insights from the discovered patterns and processes help to deal with the complexity, which is where the true value is.
So, while process mining and data mining have a lot in common, there are also fundamental differences in what they do, and where they can be useful. Is there anything that I missed? Let me know in the comments.
Leave a Comment
You must be logged in to post a comment.






