
How Process Mining Compares to Complex Event Processing

Complex Event Processing (CEP) is a topic that has gained more and more interest over the past years. The core idea is that huge event streams are correlated and analyzed on the fly, for example, to detect fraud patterns or monitor stock prices.
On the website of the popular open-source CEP engine Esper, they nicely explain the difference of complex event processing compared to a database:
The Esper engine works a bit like a database turned upside-down. Instead of storing the data and running queries against stored data, the Esper engine allows applications to store queries and run the data through. Response from the Esper engine is real-time when conditions occur that match queries. The execution model is thus continuous rather then only when a query is submitted.
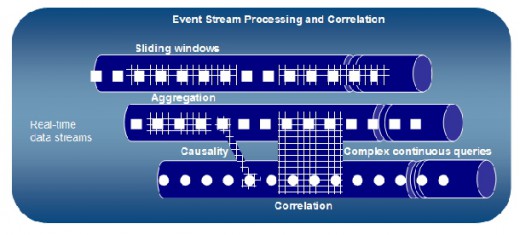
Based on a set of preconditions and matching criteria, event actions (such as a fraud warning) can be triggered while analyzing chunks of streaming data (see ‘sliding windows’ in picture above). These matching statements can be very complex and also analyze temporal aspects (for example, combined with “followed by” conditions).
So, how does CEP compare to Process Mining?
In my view, they are mostly complementary and can be combined: CEP can be used for correlating low-level events from streams that otherwise might not even be stored1—in order to form meaningful events as input for process mining purposes. I see correlation needs in two dimensions:
-
Process mining generates process models from event data, but these events need to be correlated into so-called process instances. That is, traces or event sequences belonging to one execution of the process must be identified within unordered, interleaved event streams.
-
In process mining, the events within the process instances need to have a relation to actual business activities to produce business-level process models. So, if the events are too low-level, correlation can help to yield higher-level events that represent actual activities of interest2.
Do you agree with this positioning? Has anyone already experience with combining Process Mining and CEP technology? In which environments do you see benefits for such a CEP / Process Mining combination?
-
To enable the post analysis of events produced by a CEP engine for process mining techniques, these events need to be stored. If you are interested in this, here is a research paper on event data warehousing. Thanks to Szabolcs for pointing me to it! ↩︎
-
This problem is also addressed by process mining research towards activity mining. See for example this research paper for an activity mining approach ↩︎
Leave a Comment
You must be logged in to post a comment.






