
How Machine Learning Can Improve the Quality of Your Master Data
Blog: The Tibco Blog
You’ve probably heard a lot about how artificial intelligence (AI) and machine learning (ML) can improve your business. But what about improving your master data management (MDM) program? In a recent webinar, Amit Verma, Data Scientist and Solutions Architect at TIBCO, and Conrad Chuang, Senior Director Product Marketing at TIBCO, demoed some of the ways that ML can be useful in MDM to help improve the quality of your master data and speed up your data governance workflows.
Inductive Matching Use Case
Since there are many ways that ML can improve any MDM program, let’s look at one use case where ML capabilities can exceed those of traditional techniques, matching. Matching is a commonly used technique in MDM to decrease the number of duplicate records in your data set. Essentially, any data set is plagued with duplicate records due to mistaken double entries, misspellings, merged databases, etc. Matching is the process of finding those records that are close enough to be the same but hard to put together. If they do match, they can be merged, if not, they stay separate. It’s a great way to ensure your database is clean and accurate.
To contrast with the newer ML technique, here is how traditional matching is performed:
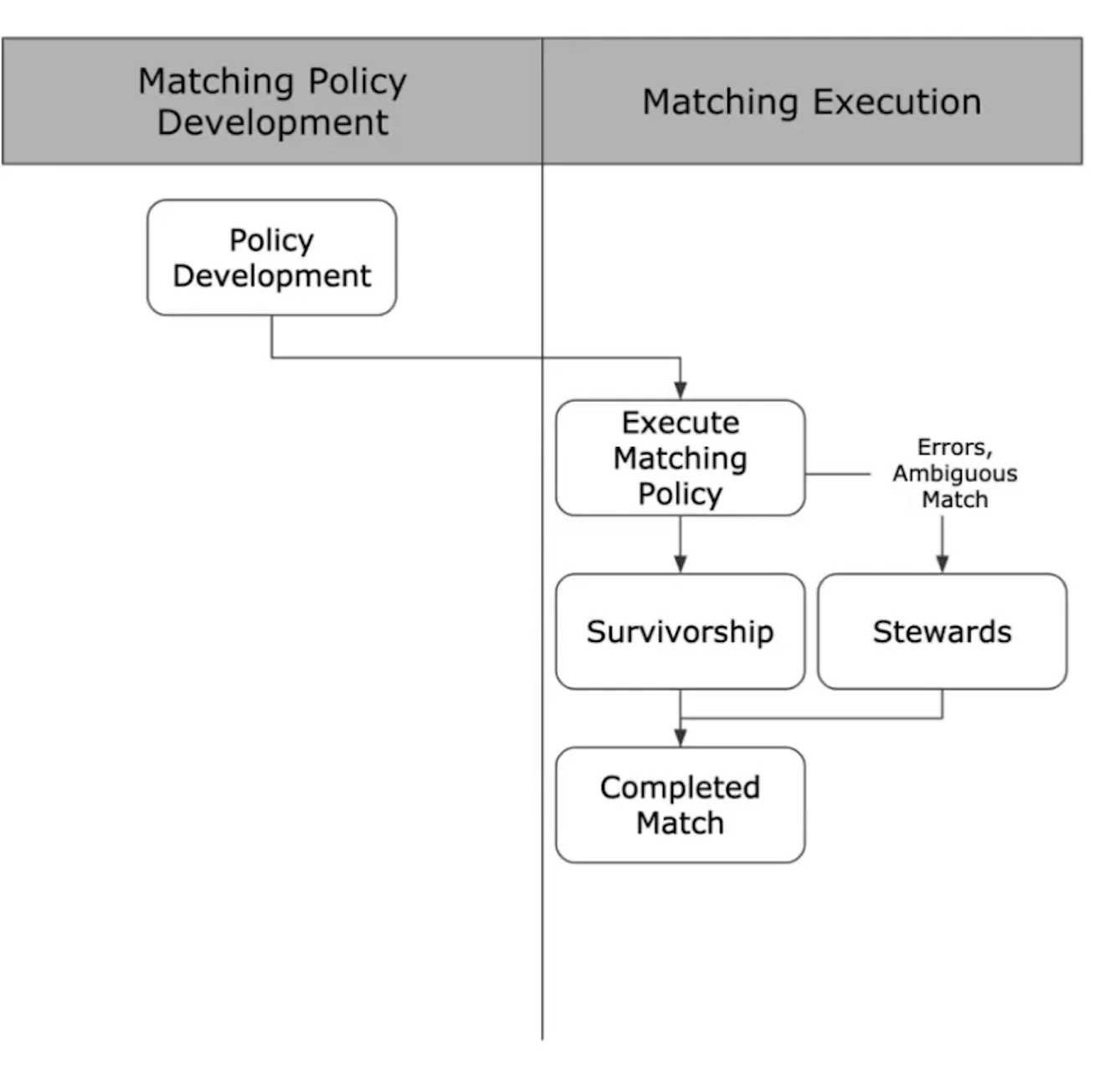
Traditional matching follows this path:
- Policies are developed and deployed
- Policies are executed
- Stewardship and survivorship policies drive merges and address errors
- Over time, the policies are adjusted
Challenges with Traditional Matching
With traditional matching, we profile the data, we examine the info, we develop a policy, we then put the policy into production, the systems execute the policy and over time, we adjust based on changing levels of quality of the data. While this is effective in certain circumstances, the first major issue is that it is based on an extrapolation of the data. When going this route, it’s just not feasible to profile the full data, so we extrapolate. And some of the extrapolations are based on assumptions. Therefore, we are not looking into the data fully. We are matching based on the features that the tool can offer and partly based on the implementation, the consultants, and the experience of the implementers, based on a period of time. For instance, if you built your data set 20 years ago, you may not have considered a mobile phone an important piece of information and therefore, did not include that in your policy. That would be a mistake in today’s world where mobile phone numbers have become proxy identifiers for many people.
Inductive Matching with ML
With ML, you let the model decide which features to use for mapping. Here’s how it works:
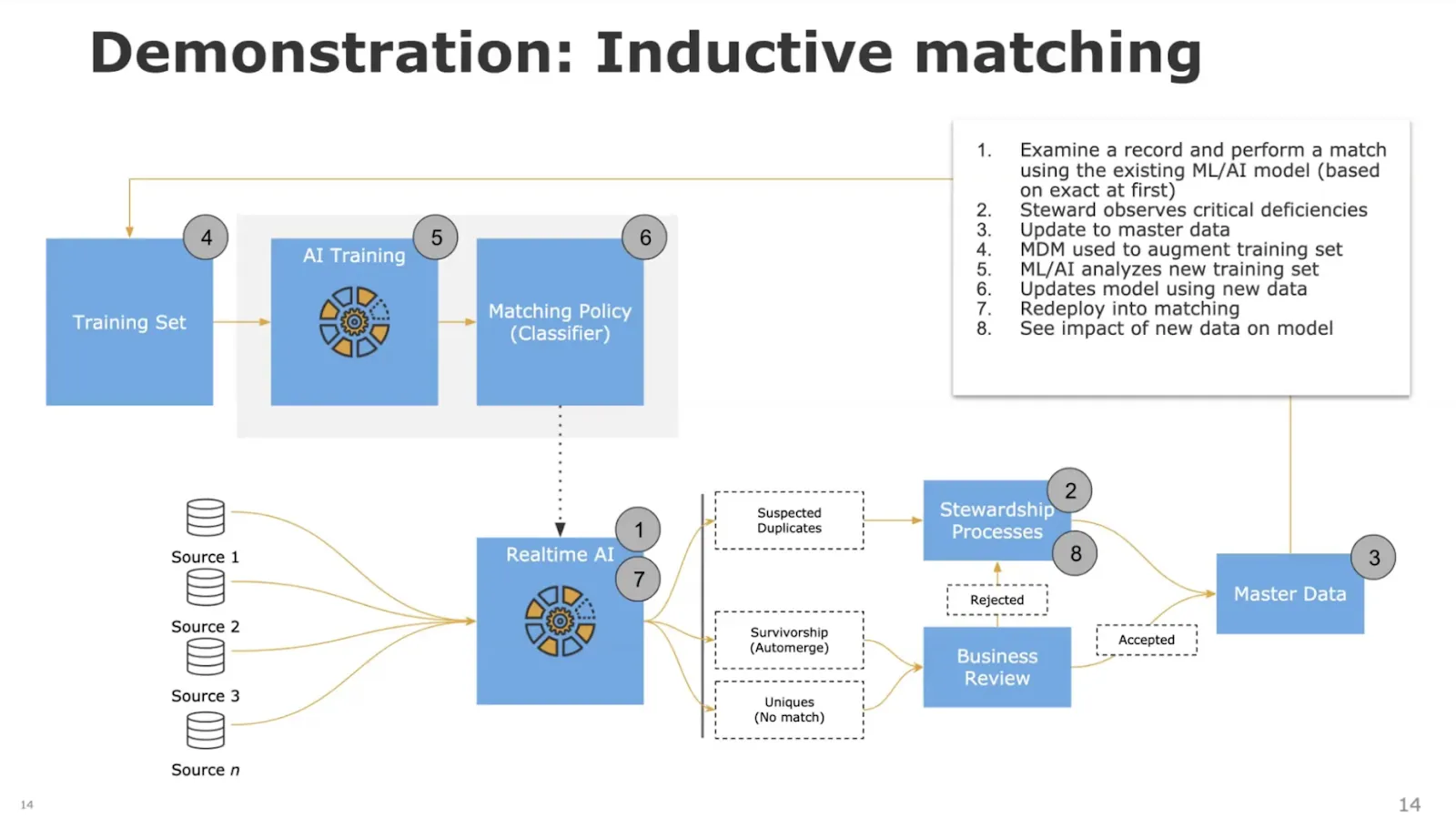
Instead of the user choosing which particular field or attribute is important or not, you let the model decide for you. When you run all those features against the model using the ML method, the model will say what it’s seeing in the current status of the training data and decide which features make more sense depending on what the data is showing. As a result, you have a more dynamic model as opposed to something a bit more static. It can be faster and more accurate to use ML.
And this is just one of the ways that ML is the better way to go in your MDM programs. In the webinar, watch the speakers walk you through other benefits that ML can bring to your MDM program.