Handling Asynchronous Operations with Flowable – Part 2: Components & Configuration
Blog: Flowable Blog
Welcome to the second post of the series on the Flowable Async Executor. In the first part of the series , we described the basic concepts: what asynchronous jobs and timers are; and why they’re useful when building BPMN and CMMN models. In the last section, we also gave a high-level diagram of the new architecture of the Async Executor.
In this part, we’ll look at the various subcomponents that together constitute what we call the Async Executor. We were tempted to use this post to already share the benchmark results, but we realized that:
- To understand the results properly, knowledge of the subcomponents is needed, as they are expressed against a certain set of configuration settings. Even changing parameters for certain subcomponents slightly can lead to very different results. As such, getting these interacting subcomponents defined is important to understand how you can squeeze out the highest performance for your setup.
- On the Flowable forum, we sometimes get questions on how to tweak the various settings of the Async Executor. So we thought it would be a good idea to talk about the settings for each subcomponent and the impact of changes to them.
High-level Components
As we’ve established in the first post of this series, from a high-level point of view the Async Executor has the following elements:
- Acquisition: The Async Executor needs to pick up new asynchronous jobs or timers (when their due date is passed)
- Execution: Once acquired, jobs obviously need to be executed.
- Persistence: All jobs need to be persisted, and should only be removed if the underlying work has been fully completed. If no Async Executor instance is active when a job/timer gets created, it should still be persisted and picked up when an instance comes online.
- Error Handling: Jobs can fail when executing, such as when calling an external service, but so too can the acquisition element. Jobs need to be retried automatically on failure. When jobs keep failing, they are automatically transformed to a ‘deadletter’ job (a similar concept as in message queues).
These elements also need to work in a multi-node setup. Jobs that are acquired on one instance shouldn’t be picked up on other instances. If a job gets acquired on an instance, but the underlying server crashes for whatever reason, that job needs to be automatically picked up by another Flowable Async Executor.
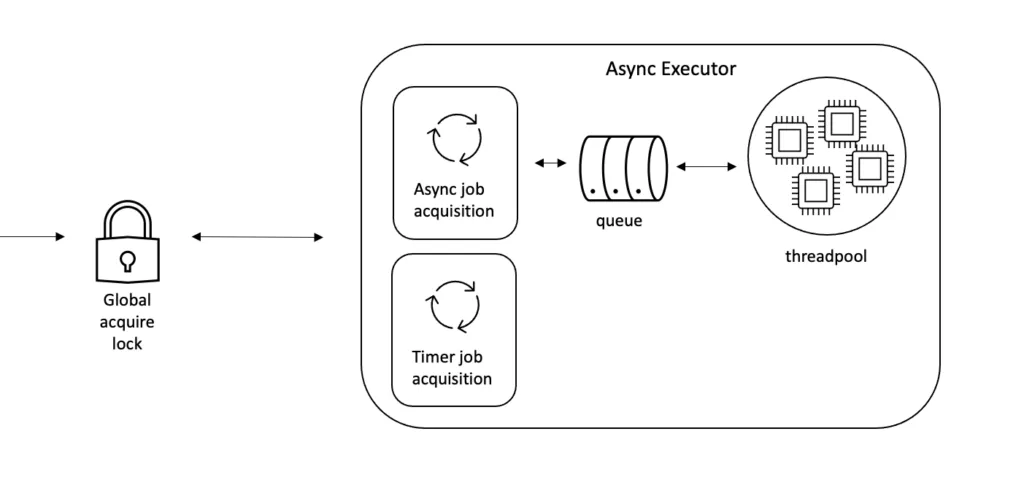
The following diagram shows the first-class subcomponents that are involved in fulfilling these requirements. Of course, none of the low-level implementation details, like data storage, data passing or transformation are shown here. Naturally, as the source code of Flowable is open, you can go and discover this yourself. No secrets here!

Let’s have a look at each of these subcomponents from left to right. For each of these, we’ll also describe how they can be configured. We’ll do it in an environment-agnostic way and describe the setting conceptually, as the actual way of making settings and even the property names depends on your environment (Spring Boot, standalone, Flowable Enterprise, and so on).
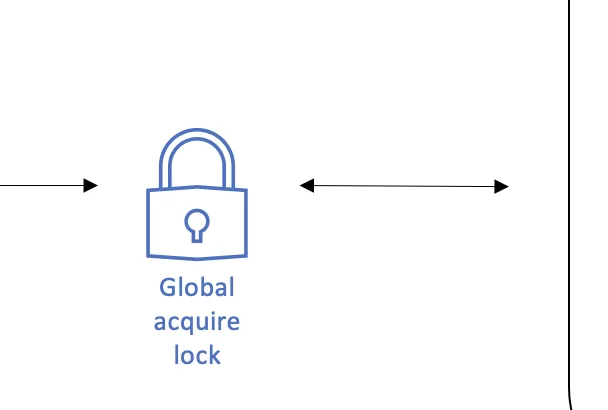
The Global Acquire Lock
The Global Acquire Lock is a specific implementation of Flowable’s LockManager interface. This interface lives in the common module and is used by various engines when locking is needed. The Async Executor uses it to guarantee that only one Async Executor instance at a time can acquire jobs/timers. This functionality is brand new and will be part of Flowable 6.7.0 and is one of the reasons we could improve the performance of Flowable.
There are three main reasons why this implementation is superior to the old one. We’ll dive into the details in parts three and four, but let’s already discuss them here briefly.
First of all, when only one Async Executor instance at a time is acquiring jobs, these jobs can be treated in bulk (instead of one-by-one with an optimistic lock check as was the case before), because we simply don’t need to worry about concurrent access. All of our previous benchmarks proved that limiting the network traffic was always the best way to improve performance. Doing things in bulk updates rather than separate operations helps a lot when it comes to Flowable’s performance.
Secondly, and probably equally important, is that this allows for a larger number of jobs to be fetched in one acquire cycle. Previously, while it was possible to set the amount of jobs fetched in one acquire cycle (and thus one network call) to be a large value (say, 100), because multiple nodes could be acquiring at the same time, the chance of collisions was high. This collision rate would even rise when adding more Async Executor instances, actually having a negative impact on the throughput. In extreme, worst-case-scenarios, we actually witnessed that the Async Executor would barely get any jobs through the acquire phase, which meant that only a fraction of the jobs reached the execution phase.
Third, but not least, our experiments showed that one of the major problems with high-scale handling of jobs was database table concurrency. Databases can handle a lot of concurrency – it’s one of their fundamental raisons d’être – but it stops at a certain point. When pushing over that limit of concurrency, the database response times will detoriate quickly, even leading to ‘deadlock’ exceptions on certain database systems (even if they’re not really deadlocks technically, but a way the database tries to alleviate pressure on its tables.). The Global Acquire Lock decreases table concurrency drastically, leading to better performance in general.
Configuring the Global Acquire Lock typically isn’t necessary. It is enabled with “global-acquire-lock-enabled=true” (depending on your environment).
Generally, the only thing that may need a change is how long an Async Executor waits to try and get the global lock again, having tried it before and not getting it. By default, it’s 1 second. By making this lower, it will increase throughput slightly, but could stress your database. By setting it higher, there may be longer delays in processing the jobs, which might be completely fine for your workload, and puts less pressure on the database.
Note that the Global Acquire Lock can be disabled. In this case, the Async Executor will use the old implementation.
Async Job & Timer Acquisition
Moving to the right of the diagram, we get to the acquisition of jobs.
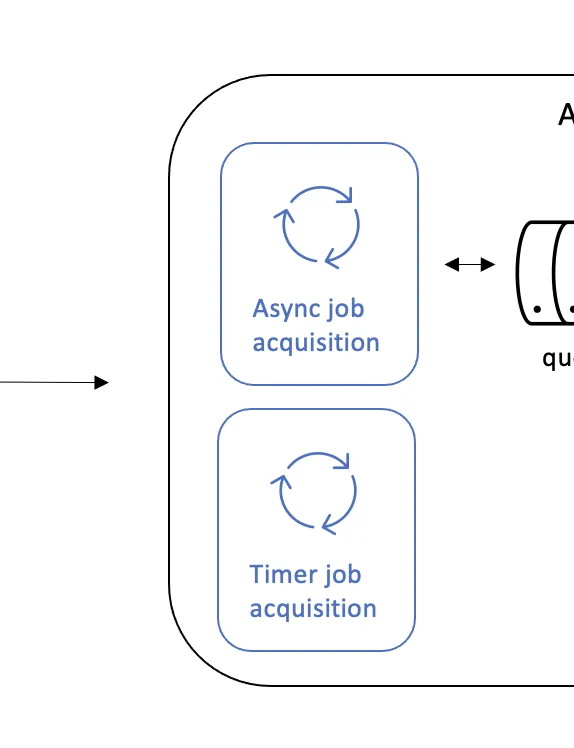
The main purpose of the logic involved in acquiring jobs is to make sure that the execution threads (see below) are never without new work to take on. There is a standalone thread for each specific job type – typically async job / timer, but this can be different, as with Async History – that fetches pages of jobs in one go.
Database transactions play an important role here. Acquisition happens in a first transaction, followed by taking ownership in a second transaction. When an instance ‘takes ownership’, it writes its own ID to that specific job row in the database table. This is, by the way, the part we can do in one go (in bulk) thanks to the Global Acquire Lock. When a job is owned by an Async Executor instance, no other instance will be able to acquire it. There’s a timeout on that ownership, too.
The amount of jobs retrieved in one acquire cycle can be configured with the following settings (again, the actual property name can be different, so check the documentation for your environment):
- max-async-jobs-due-per-acquisition=512
- max-timer-jobs-per-acquisition=512
Thanks to the Global Acquire Lock, these values can be high (hundreds of jobs in one go) without any problem.
The time a job is owned before it is deemed lost and able to be picked up by another Async Executor instance (such as due to a server crash) can be configured with following settings:
- timer-lock-time-in-millis=3600000
- async-job-lock-time-in-millis=3600000
The acquire threads will continuously fetch pages of new async/timer jobs. However, when no results are returned in a cycle, the acquire threads wait as there is no need to keep fetching new data at this point. The settings for this are:
- default-async-job-acquire-wait-time-in-millis=10000
- default-timer-job-acquire-wait-time-in-millis=10000
Another situation where the acquire threads wait is when the queue is full (see next section). This allows the threads to catch up before new jobs are added to the queue. The setting for this is:
- default-queue-size-full-wait-time=5000
Timers, when they have been acquired, are transformed into async jobs. This transformation happens by a separate threadpool. This is a new feature and actually speeds up timer throughput dramatically. The maximum size of this threadpool can be configured with the following setting:
- nove-timer-executor-pool-size=4
Internal Queue
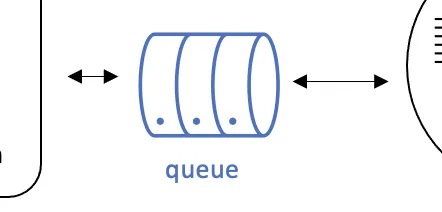
The internal queue (in-memory) is a simple, but important, component on which the acquire threads put jobs until the execution threads can execute them.
The only configuration option is its size:
- queue-capacity=2048
Setting this to a large enough value is crucial to avoid the situation when execution threads would be starved for work. Do take into account that changing the queue capacity can mean that changes to the ownership time of jobs are also needed. Jobs that are in the queue too long would otherwise be acquired by other instances, as they are deemed stuck. In a normal functioning system, this should not be a problem.
If you’re using Flowable Control, the queue capacity can be checked visually:
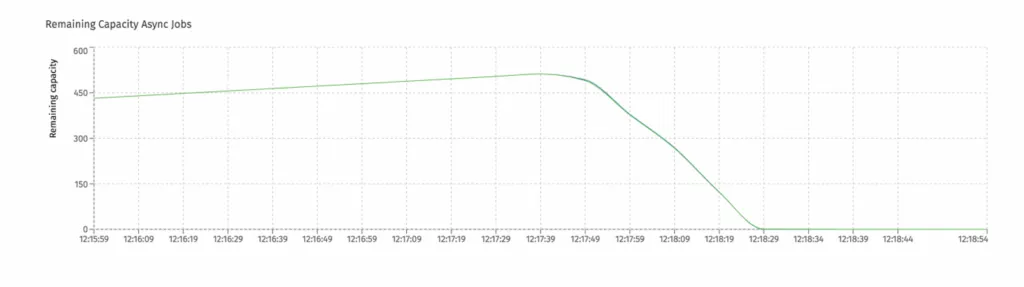
When the queue is full, jobs get rejected. This means that the ownership is removed and another instance can now pick them up. In Flowable Control, this can be also seen in the following chart:

One spike is typically not a problem, but if this pattern continues, it implies the settings need some tweaking:

Execution Threadpool
The last component on the far right of the diagram is the threadpool responsible for the execution of the job/timer. This is where the external service gets invoked; the steps after the timer get executed in the process instance; and so on.
If you have lots of jobs, adding more threads here is typically the way to go. Note that the threadpool is configured in such a way in Flowable that it will scale down the number of threads when they aren’t needed. The number of threads are configured with following settings:
- thread-pool.core-pool-size=32
- thread-pool.max-pool-size=32
Typically, you want these values to be the same (Flowable will downscale the threads, don’t worry). Note that adding threads to a modern operating system and hardware is not a problem. Almost always, logic is I/O bound and gives the CPU plenty of opportunity to cycle between processes/threads. For example, doing many asynchronous HTTP service tasks is not a problem, as that involves a lot of waiting for I/O and thus is an excellent candidate for being executed on a large threadpool.
Default Settings
As part of the improved Flowable Async Executor implementation, we also made sure the default settings are good enough by default. This means that with these settings, you’ll see an acceptable job throughput. However, if you want to scale up, adding threads is the first step, which typically needs a larger queue size setting then, too. Then, it’s a matter of adjusting the acquire size (depending on the type of jobs you have). Flowable Control has charts built-in that display all of these live. Check out our Flowable trial if you want to learn more.
Conclusion
In this post, we’ve looked at the various subcomponents that encompass the Flowable Async Executor. We’ve also started to shed some light on the improvements that have been made with the new Global Acquire Lock approach and the beneficial side-effects it brings.
As usual, all of this can be seen and dissected by yourself by checking the Flowable source code. Open code and transparency has been a driver for Flowable since the beginning … and we’re very proud of that.
This also means that we’re now all set up and ready for the next post: the actual benchmark results! Stay tuned for that very soon.