Forgetting history: Why Ignorance Can Be Bliss
Blog: Flowable Blog
People keep telling us that we’ve got so many important features in Flowable and we don’t make enough noise about them. One of the challenges when you’re building cool tech with significant capabilities is that you think – well, the benefits are obvious, aren’t they? And of course they are if you’ve been in the business of evolving BPM technology for as long as we have.
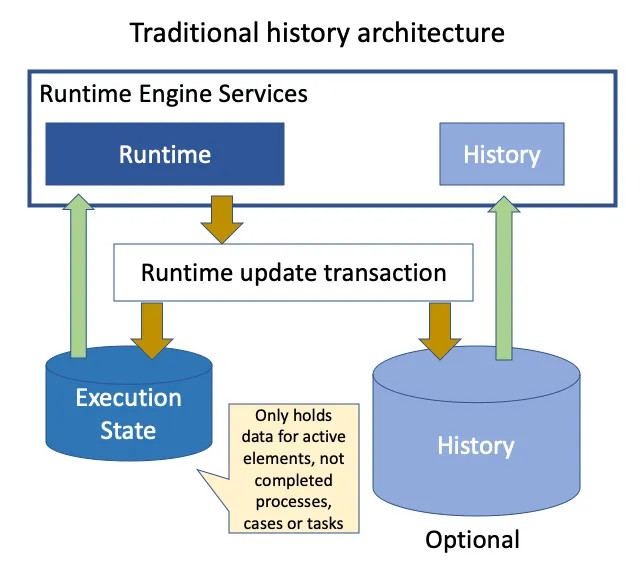
The work we did just over a year ago on how historic data is stored is a case in point. When we say “historic”, in the context of the family of BPM engines that Flowable comes from, this means anything that’s been completed. “Yes”, you say, “important stuff for analysing performance over time, or for audit purposes – we, know that, what’s the fuss?” Well, when we say anything that’s been completed, we mean anything, including the last task you just completed in the very active process that’s still running. [Pause for reflection]
That’s it. If you want to find anything about the previous state of a process or case that is still active and running, you have to use the history queries to lookup whatever’s been stashed in the history data store (typically a relational table).
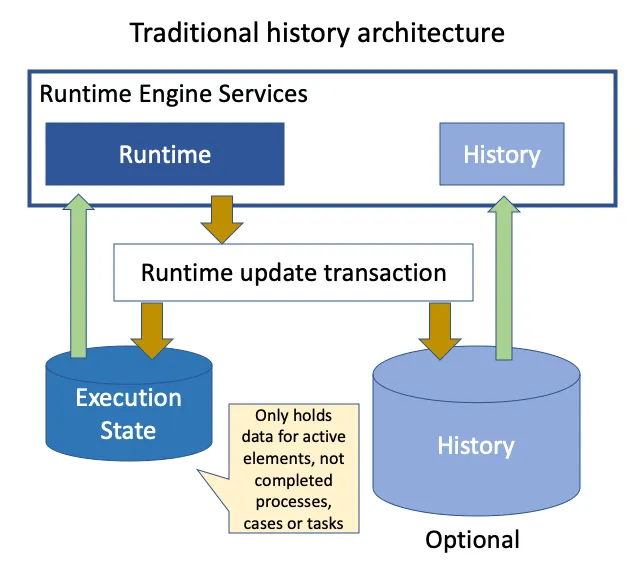
“Fine”, you say, “that’s what databases are built for.” Except it doesn’t work out that way in practice. In reality, you can create very significant volumes of data that need to be indexed to quickly find information about completed tasks in current running processes. Suddenly, database file size becomes a problem for most.
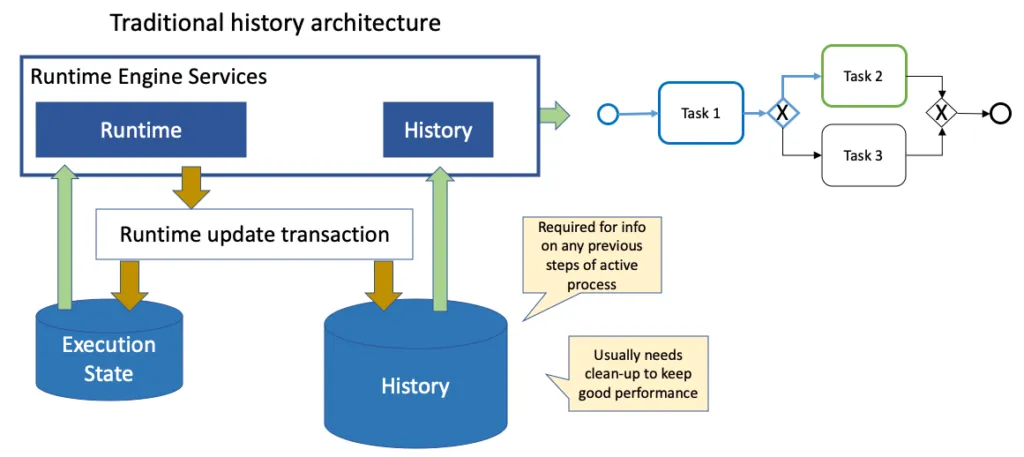
The way this has been solved to date has been to allow different levels of historic data to be retained, to limit the growth of the history data store by what data is kept, plus having periodic routines to prune the data: for example, anything over 3 months old can be removed. Trouble is, cleaning means doing complex queries and deletes in your history data store – again, what stores like relational DBs were built to do, but there’s always a cost and impact (stuff can be left dangling).
Flowable’s answer to this has been to add an intermediate table where the completed history of active processes is maintained and removed when processes and cases finally complete. Our Runtime APIs can access the “historic” data for active processes, no longer mixing APIs and data sources to be able to pass the information often needed by users and systems.
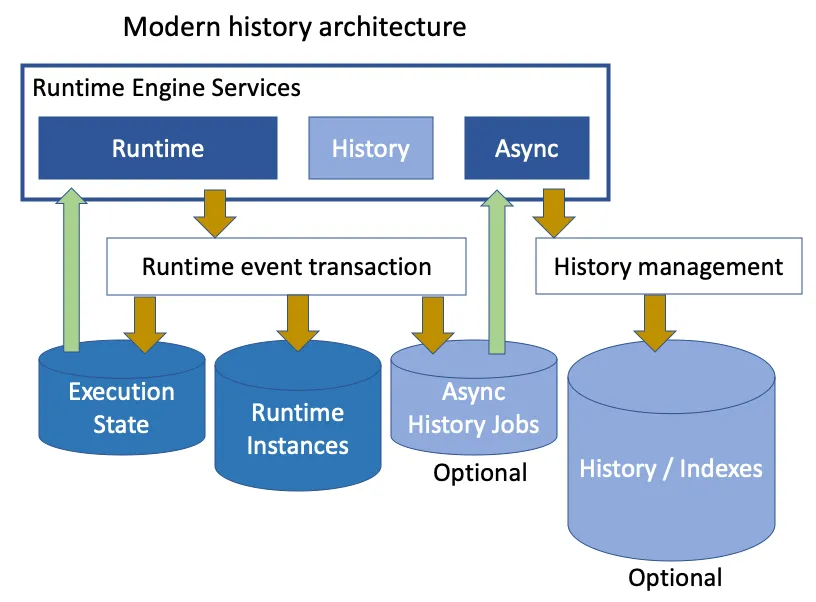
You can turn the history level completely off and still be able to display what happened earlier in a running process. No storing of data to be later pruned. You want your process runtime to be light, fast and agile? Well, now you really can, without loss of functionality.
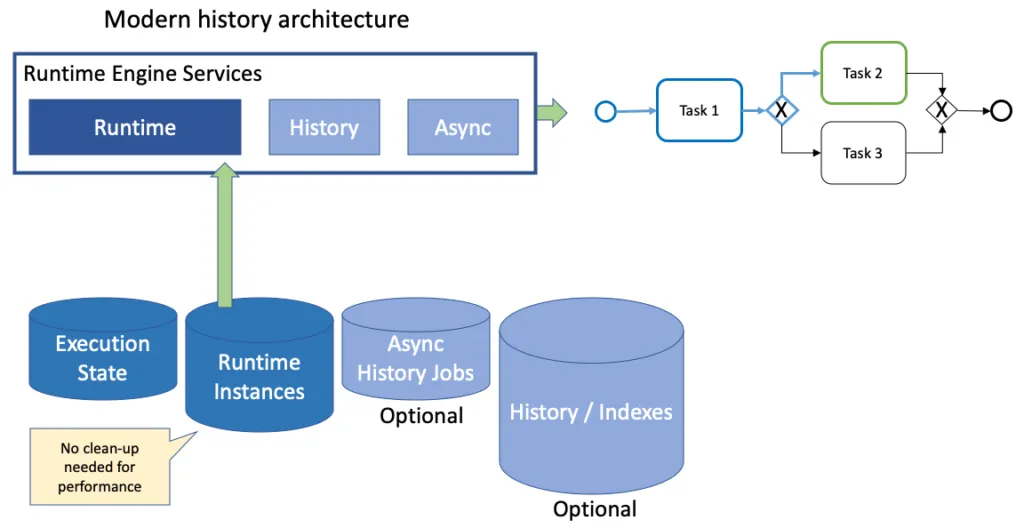
Of course, no history means no reporting and analytics or other services, such as Machine Learning, that exploit past data. Ah, have we mentioned Async History before? That’s a transactional event publishing framework that means you can still push out all the historic data you want without performance loss. We use it when we want to index process and case data for our analytics, for example.
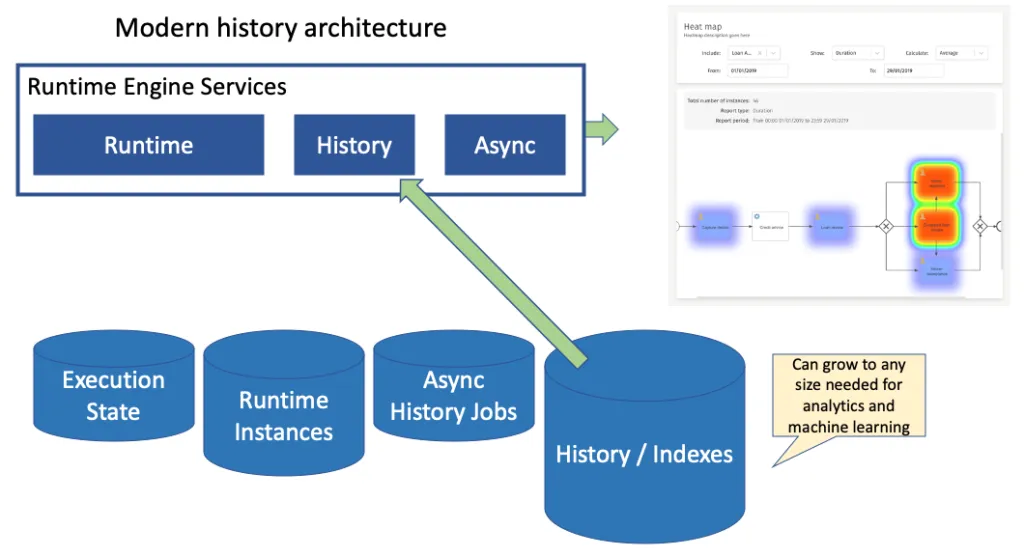
So, when you’re in your next infrastructure project, swimming in an event stream and need a process (or case) engine and its data to be lean and responsive, let Flowable pour all the history into that event stream and keep resources tightly focused on augmenting or orchestrating the flow of events. As Einstein is quoted as saying: “Never memorize something that you can look up.” Let another engine built for that purpose store, curate and empower your process and case history. Your process and case engines don’t need to be burdened by their history unless you want them to be.