
File Naming Conventions: How to Optimize Document Management
Blog: The Process Street Blog

It’s all too common to find yourself wading through your organization’s shared folders in search of the file you’ve been asked to review:
- PROJECT-PROPOSAL-NEW-v5.doc
- Project_proposal_2020_final+edits.doc
- THIS_is_the_final_proposal_(old-version).PDF
Why does this happen? Why can’t everyone just use proper file naming conventions? The reasons can be lack of proper internal policy or procedure for naming and organizing files, lack of any consideration for folder or information architecture, and just plain carelessness.
With a small amount of effort, you can establish proper file naming conventions and avoid this kind of document spaghetti. The more organized you can be with your internal information, the more efficient and effective you can be in your business goals.
Just imagine – seeing neat, intuitively named folders, knowing which folders contain the documents you’re looking for, and – take a seat – having confidence that the file you’re about to click on will be what you expect it to be.
In this Process Street article, we’ll cover:
File naming conventions: Best practices & tips

This section will consider some best practice conventions for file naming. Whether you’re a small organization or a large enterprise corporation, these principles should be relevant, because they’re designed to consider the needs and requirements of each case before administering any one solution.
- Establish your information architecture
- Readability: Humans vs Robots
- Wikipedia shows that being digital can broaden your categorization
Establish your information architecture
“Information architecture” is the way you organize your internal information, in terms of how you design the system that allows you to access and manage that information.
Websites are a great, pragmatic example of informational architecture – they’re quite literally formal systems of information organized into a navigable and interactable interface. Hyperlinks, site maps, and navbars all represent the architecture (the links between different pieces of information) of the websites you’re viewing.
Of course, we’re not necessarily talking about websites. Information architecture is a broad concept that can be applied to any kind of knowledge management. In any case, building solid information architecture will depend on a deep understanding of what information you have, and the most efficient and effective way to make sense of all of that.
What does “efficiency” or “effectiveness” mean for information management? You can start by considering who will need to access the information. Will there be multiple iterations of similar files, many files across different areas of the organization, multiple departments accessing the same area? This kind of thing.
Efficiency can be understood as the shortest time possible taken to access any given file. How many clicks is also a relevant metric. Is the folder structure unnecessarily complex, taking 10 clicks through empty category folders before reaching the destination file? Consider if more horizontal organization is a better option, with a couple of clicks to relevant files.
Effectiveness can be understood as whether or not the file naming conventions help or hinder the completion of daily tasks. How many different files do you have to open before you find what you’re looking for? Is the file naming convention intuitive, or do you need to spend extra time learning how to make sense of 010220_MA_P-01_Project_1_Draft.doc, when Marketing_Project_Proposal_June_v1.doc would do just fine?
Readability: Humans vs Robots
One of the most important questions you can ask is: Who are you organizing your files for? All said and done, who will actually be using this system of file naming conventions to navigate your library?
It may be that you’re organizing internal media files in a remote organization, or for a local intranet – in that case, you probably want the files to be human-readable. In that case, something like this might make sense:
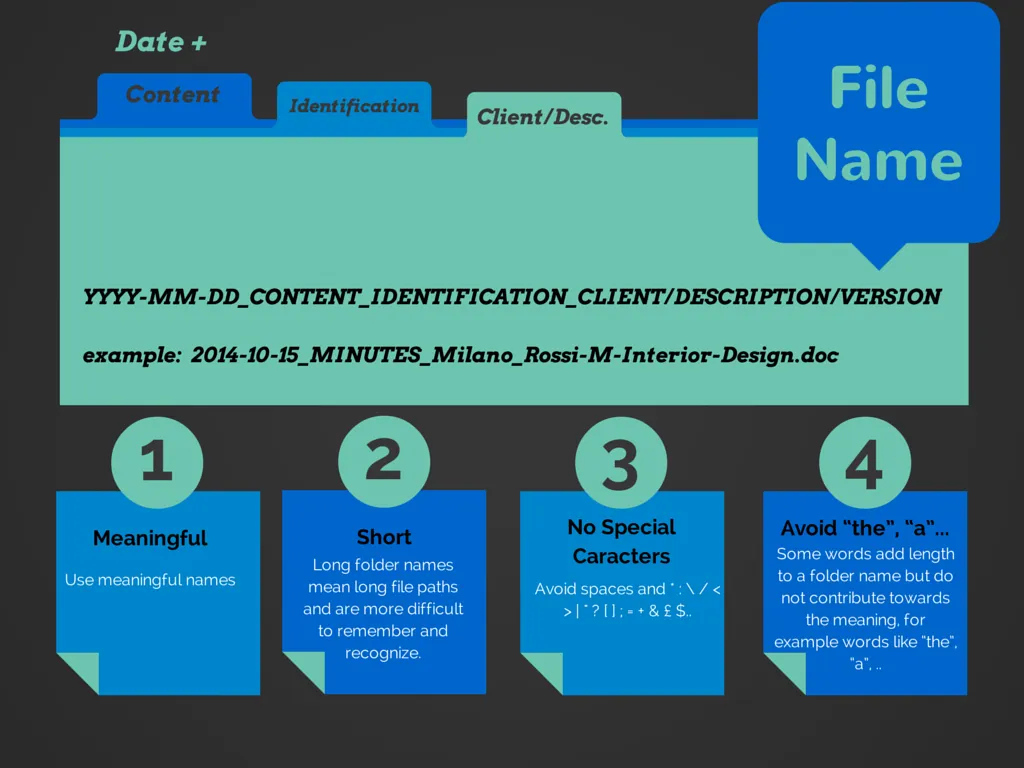
Keeping things short, meaningful, and removing unnecessary information will help people navigate your files with minimal effort.
On the other hand, perhaps you’re tasked with managing large batch files for automatic processing or robotic search, in which case, human readability might not be your primary concern (though it’s probably still useful, in the least for debugging and error-chasing purposes.)
Wikipedia shows that being digital can broaden your categorization
Wikipedia is one of the largest collaborative works of human knowledge on the planet in recorded history, but have you ever considered how that information is structured?
Let’s return to the idea of information architecture. In 1996 Richard Saul Wurman described information architecture as:
“the creating of systemic, structural, and orderly principles to make something work – the thoughtful making of either artifact, or idea, or policy that informs because it is clear.”
According to Noreen Whysel writing for the American Society for Information Science and Technology:
“Wurman coined the phrase information architecture in his 1976 program for the American Institute of Architects annual meeting. If we take Wurman as a start, then IA is a field of practice that is approaching its 40th anniversary. Unfortunately, this long history is not reflected in the world’s largest public encyclopedia.”
Whysel was part of the group proposing the WikiProject Information Architecture; an attempt to improve Wikipedia’s information architecture from top-down, starting with their high-level categories and moving down to the content on each individual page. The goal was to improve ease of use, navigation, and trust.
Wikipedia’s open-edit nature means there are a lot of ways you can unpack the categorization system. Check out the Wikipedia Contents page to see what I mean. Starting with language, the nested categories move from page types to broad subject areas, to many different sub-categories and sub-sub-categories going all the way down.
You can also browse Wikipedia using other categorization systems like Dewey Decimal, or by simply searching. In fact, Wikipedia itself states:
“There are two ways to look things up in Wikipedia: by searching or by browsing.”
What’s the lesson here? Wikipedia is demonstrating that it’s more effective to utilize a range of different categorization and search methods, and that search is perhaps one of the most user-friendly solutions for navigating huge, complex databases of information.
This is especially useful to acknowledge when considering best practices for file naming conventions. If your goal is to organize your files and documents so that they are easy to navigate, then it’s worth spending time with the file naming structure so that users can use consistent search terms to find exactly what they’re looking for.
The Dewey Decimal file naming convention
“Dewey Decimal” refers to a file naming convention named after a 19th century American librarian named Melvil Dewey. Originally, it was a method of organizing information (books) based on 10 main classes that attempted to cover… well, pretty much everything.
Who’s it for & what problem does it solve?
We should remember that the Dewey Decimal Classification (DDC) was first and foremost a system designed to be used in libraries. It was also originally designed to be organized by discipline, as opposed to topic. This has changed over the years, and many places, libraries and other such organizations, implement their own flavor of Dewey Decimal.
Still one of the most utilized book organization systems in the world, “Dewey Decimal” is in effect in over 200,000 libraries in 35 countries in the 21st century. So what can we learn from this naming convention?
The main problem Dewey Decimal solves is organizational. It helps arrange books in a way that allows anyone browsing to swiftly find what they’re looking for. For better or worse, the Dewey Decimal system is here to stay, and its longstanding legacy speaks to its efficacy as a file naming convention.
How does it work?
The best way to explain how the Dewey Decimal system works is by showing. Here’s a table organized using Dewey Decimal:
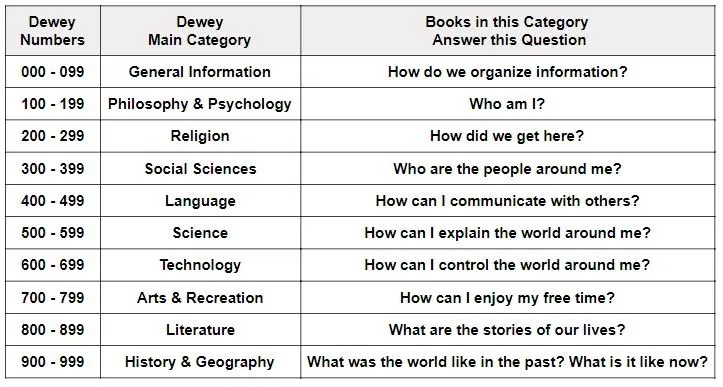
Notice on the left hand side, there are numbers from 000 to 999. This is the “decimal” element. Here we have:
- 10 main categories of topic
- 100 unique divisions per topic
- 1000 unique sections in total
Essentially, using numbers to divide main categories into smaller, more specific divisions and sections That’s the Dewey Decimal system in a nutshell.

Strictly speaking, you could take these sections and further subdivide with actual decimal points (many larger libraries do) like so: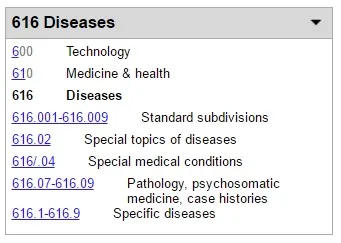
However, you should determine whether this is necessary or simply overkill, depending on your internal file and process library.
Adapting Dewey Decimal for your organization
One of the pitfalls of the original Dewey Decimal Classification as a library naming convention is the fact that it tends to reflect any biases in its organizational structure.
This is more a problem when the goal is objective organizational clarity, for example when deciding where certain poorly understood or novel subjects or areas of study should fall on a library shelf. It’s less of a problem when you just want to organize a set of files or processes for your internal organization.
In fact, bias can actually be helpful here. Different teams in an organization will have different biases towards organizational structure, including how core files and procedure documents are stored.
For example, the bias of the engineering team might be useful when deciding how the files and/or processes for that team should be organized.
Who better to manage and own the organization of forms, files, and recurring processes than the people who use them most?
You might not need a thousand-manifold Dewey Decimal structure to organize your internal files and processes. But you might be able to use the principles of DDC to improve your file naming conventions. If you can implement a simple, intuitive structure with numbered subdivisions of specific categories and functions, you’re one step closer to improving the searchability (and therefore the utility and actionability) of your internal file structure.
Process standardization vs process harmonization
Small businesses are in a great position to implement really solid file naming conventions and standardize their processes. When you focus on solving these problems early, before you grow and expand too large, you solve a simple problem before it grows wildly unmanageable.
As a SMB, you don’t have so many internal processes, so it’s easier to manage them all and get to the point where you have everything under control.
If you run a small business, you don’t need five different documented processes for storing documents or dealing with different projects and clients. Even if you manage two or three similar establishments like this, it’s easy to be sure that all of these use the same methods.
The challenge you face will come when you reach the point of having 1,000 different establishments in different countries, that need to follow different laws and regulations, or sell different products or services. This becomes a question of process standardization vs process harmonization.
Process standardization means making one process for one job and keeping it the same, no matter where you use it. Obviously, this won’t work if you need to work across different countries or navigate different regulations. Process harmonization, then, is about setting a standardized core, but allowing for subtle changes as and when to accommodate for different use cases and scenarios.
Standardization or Harmonization? You need Both is a paper by Albrecht Richen and Ansgar Steinhorst that delves into the relationship between these two terms.
McKinsey also published a more recent study, Getting Ruthless With Your Processes, which provides some interesting insights.
They found that of the 300 top executives surveyed, 85% believed that processes “help them share knowledge across divisions and regions”, with a key takeaway being that standardized processes help to improve performance across the board.
Another important takeaway is the demonstration that most companies are bad at managing their processes. One telling insight being that one company has 30 separate processes for the act of folding a seat on an oil rig!
What’s the point here? Companies should take process standardization more seriously, but they should also understand the difference and value between standardization and process harmonization.
McKinsey’s identified three challenges here:
- Processes for the sake of processes – too many processes for things that really don’t need processes, meaning wasted time and resources.
- Over-standardization – to the point where processes become so rigid and inflexible that they are rendered ineffective.
- Resistance to changing processes – Even if your goal is standardization, you should give employees space to attempt to make changes to and improve processes.
How can we apply these insights to the problem of file naming conventions, and more broadly, overcoming the challenges of information architecture?
McKinsey recommended three approaches:
- Build and maintain a process library – staff should have a central repository of all internal processes and procedures, with a clear file naming convention and informational structure. Once this is established as a clear initiative, it helps to establish an internal culture more observant of proper file naming conventions and knowledge management.
- Optimize your processes – either via standardization or harmonization. How you approach this practically will depend on your company. In any case, your goal is to improve the efficiency and effectiveness of your processes.
- Implement top-down changes – this helps establish clear best practices for knowledge management and will also help to build a more effective company culture around best practices. Consider establishing a process-focused team with members from different departments to meet regularly and discuss the best way to optimize processes in their respective teams. This approach helps facilitate both standardization and improvement.
How we organize internal processes at Process Street
We’ve gone over some common ways to organize files and folders, but it might be more useful to take a look at how we do things internally here at the marketing team.
It’s quite simple – we have a lot of internal processes, and we’re always adding new processes, as well as continuously improving old ones. So there are two main sections – Live (for finished, ready-to-use processes) and Staging (basically a sandbox for testing new processes).
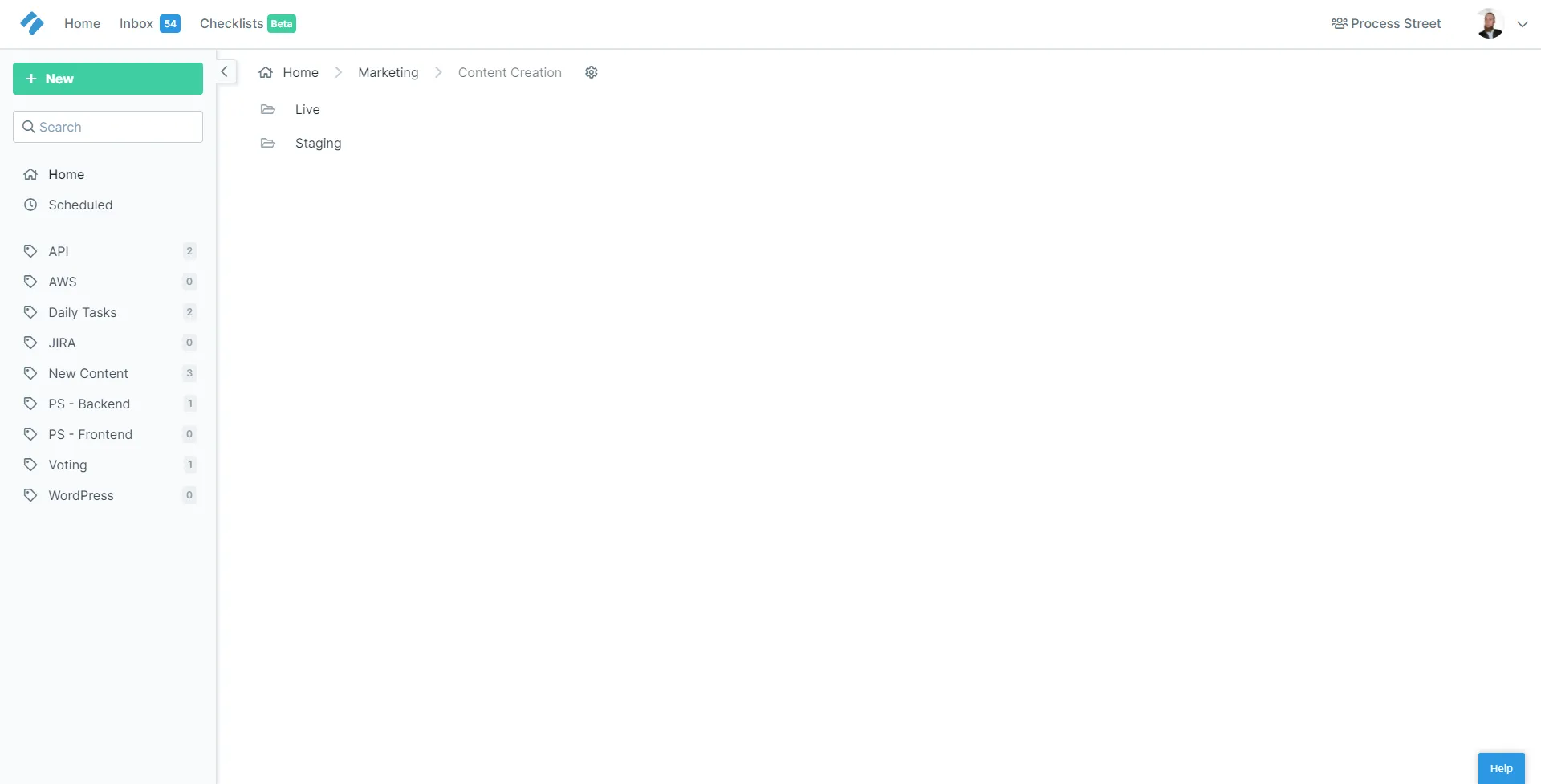
This is kind of borrowing from the software development framework, because we’re dealing with tools (processes) that are iterated on and often need lots of testing before they’re ready to go live. That’s pretty much where the comparison stops, though – so don’t get too bogged down on it.
In Staging, we segment the processes into the different types of marketing processes used for getting things done on the marketing team. It’s purely utilitarian, and designed to be easy to follow for any new members.
Inside of Staging, we have a few other folders:
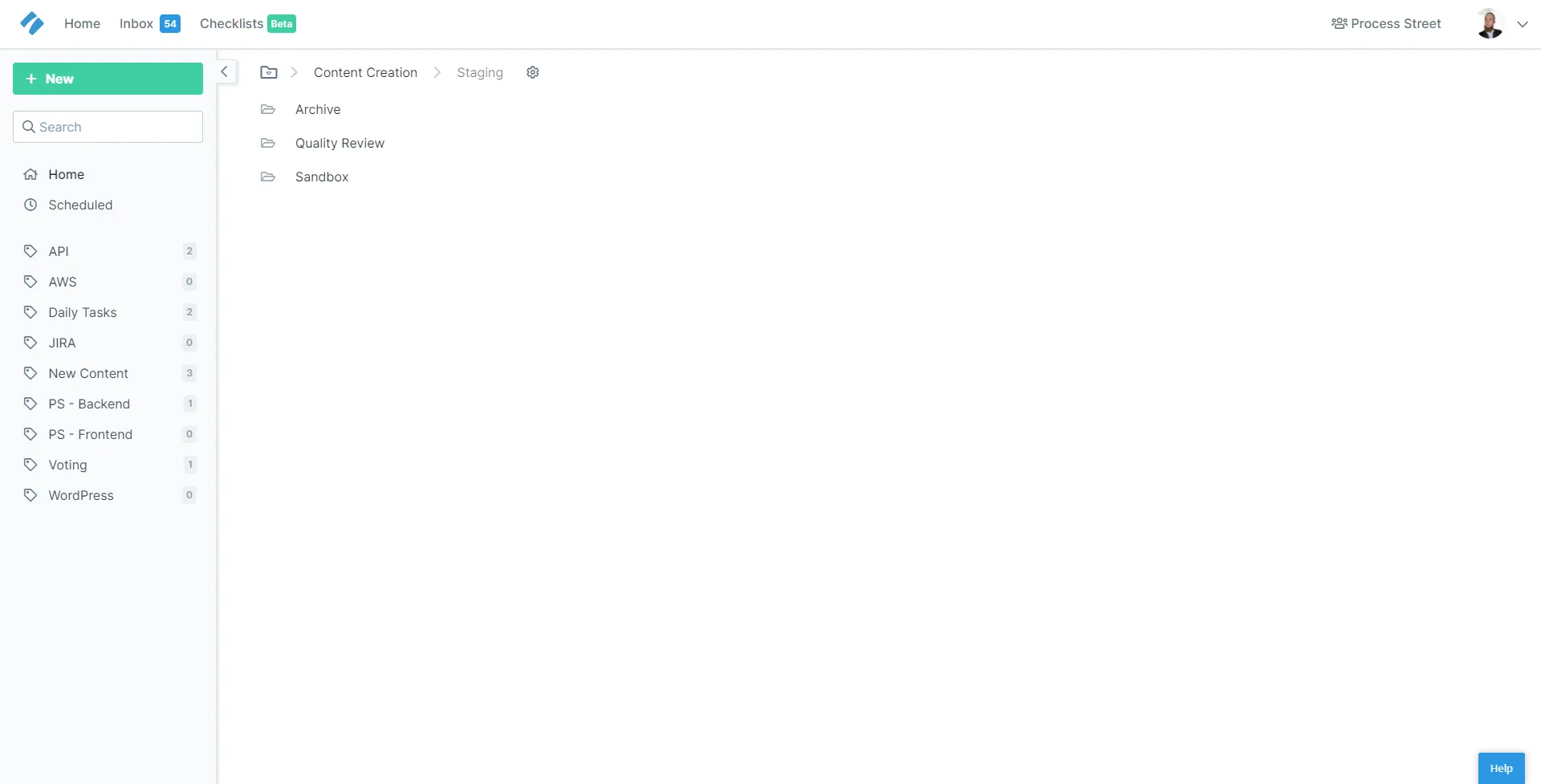
They’re all quite self-explanatory. Archive is for old processes we don’t need anymore (but still want to keep a record of), Quality Review is where processes go before they get moved into “Live”, after someone takes a proper look over them, and Sandbox is where each process begins its life, as a test or rough draft.
And that’s it! Nothing too complex. The thing about file naming conventions, is that you need to design the solution around your needs. Why over-complicate things if a simple, more elegant solution would work just fine?
You may also have a genuine need for a more in-depth solution like Dewey Decimal – be sure to consider what the best fit for you might be.
How to organize the perfect process library
Whether you’re creating a new process library from scratch or are just looking into how to better organize your files, our Process Library Checklist will walk you, step-by-step, through everything you need to make sure your system is organized and efficient from the start.
Take a look at our Process Library Checklist below:
As you can see, this is more than just your typical to-do list.
The checklist is superpowered by our workflow automation features like: conditional logic, role assignments, Approvals, and stop tasks!
It makes the daunting task of getting everything organized a lot more simple, right?
This Process Street checklist can be used to create a process library at any scale, whether it be, for example, for your company or for your personal computer at home.
Using this checklist will allow you to easily:
- Build an efficient and effective process library for your company;
- Streamline your recurring processes;
- Keep track of progress and recorded data with the help of features like the checklist dashboard.
To get an idea of how other companies are using Process Street to build their own process libraries, check out the video below from Mainline Autobody:
What kind of file naming conventions are you using? Tell us about your experiences (or horror stories) in the comments below!