DMN: What’s a Hit Policy?
Blog: Method & Style (Bruce Silver)
Newcomers to the Decision Model and Notation (DMN) standard may be put off by the notion of a decision table’s “hit policy.” What the heck is that? It sounds technical. Add to that the idea that the modeler is supposed to select the “best” one. Too complicated!
Well, it’s actually not. Here is what’s going on.
Each row in a decision table is a rule. The columns represent inputs and, at the end, one (or occasionally more than one) output. Each input cell in a rule represents a true/false condition for the input: Does it match a particular value, fall into a specified range, etc.? (A hyphen in the cell means the input is irrelevant in this rule; the cell value is true by default.) If all input cells for the rule evaluate to true, the rule is said to match, and the output cell value is selected as the decision table output. OK, we all get that.
Hit policy comes into play when more than one rule matches. In that case the rules are said to overlap, but that’s not necessarily an error. Sometimes it’s easier to create decision tables with rule overlap, and those tables rely on the hit policy to select the proper output value. There are 5 different hit policies that select a single output value, plus a few more that create a list of output values. The 5 are:
- Unique (U): Only one rule may match. Overlapping rules represent an error.
- Any (A): Rules may overlap, but only if their output values are the same. Overlapping rules with different output values mean the table is inconsistent, an error.
- Priority (P): Overlapping rules may have different output values. The hit policy selects the one with the highest priority, which is determined by the order of allowed values in the table output column heading. A P table that omits allowed output values is an error.
- First (F): Overlapping rules may have different output values. The hit policy selects the first matching rule. Many experts deprecate F tables because they violate the principle that the order of rules in a table should not affect the result. Anything you can do with F tables you can do with P tables instead.
- Collect with aggregation (C+, C>, C<, C#): Except for C#, the rules must have numeric output values. Hit policy C means collect the values of all matching rules; the aggregation code tells you how to combine them. C+ means take their sum, C> means select the maximum value, C< means the minimum value, and C# means report the count of matching rules.
Modelers need to understand the relative advantages and disadvantages of U, A, and P tables. While some experts tend to recommend always using a particular one of these, they each have their place. Compare the two decision tables below, which perform a loan prequalification prior to obtaining the credit score. The output value is “Need credit score” if the loan-to-value (LTV) ratio is less than or equal to 80%, the Affordability Category is “Medium” or “High”, and the Borrower Risk Category is “Low” or “Medium”. Any other combination of input values results in “Decline”.
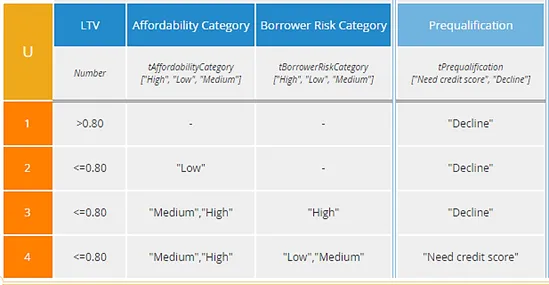
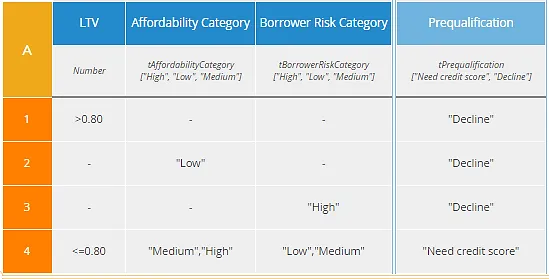
The U table has the advantage that any combination of input values matches exactly one rule, so the resulting output is always crystal clear. But the A table below it is not only simpler to construct, but has the advantage, in this case, of isolating each reason for declining the loan in a separate rule. A loan application with LTV>80%, low affordability, and high borrower risk will actually match all of the first three rules, but they all have the same output value, “Decline.”
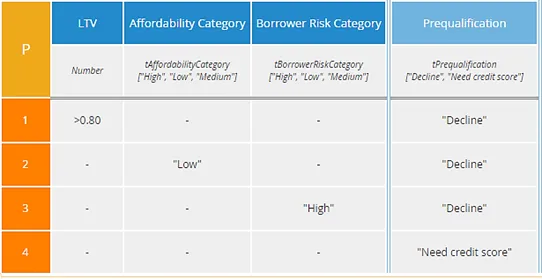
The P table above is similar to the A table, and even simpler, because rule 4 has all inputs hyphen, meaning this rule always matches. Such an “else” rule, with all inputs hyphen, is fine as long as its output value – here “Need credit score” – is the lowest priority. That means it must be listed last in the allowed output values in the column heading… which it is. In decision tables, simpler is usually better, and so P tables of this sort are often the best choice. But there is another form of P table I call P2, which is even simpler.
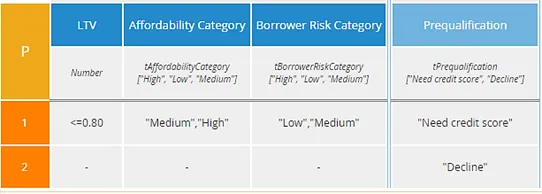
The P2 table has only two rules, including an “else” rule. Notice in this one “Decline” is the lowest priority, unlike the first P table. P2 is in a sense the simplest, but it does not isolate each reason for decline in a separate rule. In most tables with two possible output values, I would probably favor the first P table – call it P1 – over the others, but a case could be made for each of them.
When there are more than two possible output values, P tables can be misleading to untrained users. This is a point often made by Jan Vanthienen, a noted decision table expert. For example, he might ask, in the P table below, when is the output value “Referred”?
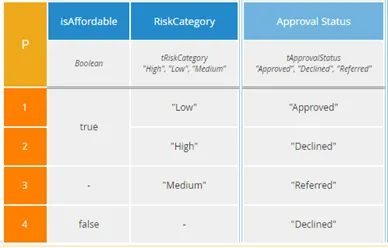
If you said, when RiskCategory is “Medium” that would be incorrect. The correct answer is more obvious from the equivalent U table below: When isAffordable is true and RiskCategory is “Medium”.
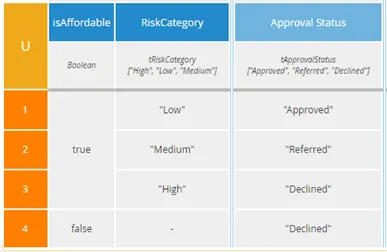
The issue with the P table comes about when a rule whose output value is not the lowest priority includes a hyphen cell. Here rule 4, output value “Declined”, has a hyphen in RiskCategory, so its value has higher priority than rule 2 when RiskCategory is “Medium” (and isAffordable is false).
Want to learn all the ins and outs of DMN? DMN Method and Style training, including lots of exercises, quizzes, and post-class certification, is available now, web/on-demand. Click here to get started.
The post DMN: What’s a Hit Policy? appeared first on Method and Style.