DMN as a Decision Modeling Language
Blog: Method & Style (Bruce Silver)
This post is a transcript of my keynote at RuleML/DecisionCamp on July 8, 2016.

I was surprised to be invited to speak here about DMN, because the inventors of DMN are here in the room but I am not one of them. While they were off inventing DMN, I was working in the related area of business process management, most recently focused on business process modeling using BPMN.
But that background is relevant to my talk today because DMN, the new decision modeling standard from the Object Management Group (OMG), is now attempting to replicate the success of BPMN. Whether DMN succeeds or fails in that attempt, I believe, depends on whether implementers heed the lessons of the BPMN experience. OMG measures the success of its standards by breadth of adoption, and by that measure BPMN has been very successful, widely adopted by both business users – notoriously averse to standards of any kind – and technical users. Acceptance by business was, from the start, always an explicit goal of BPMN, as it is now for DMN.

What I really meant to call this talk is “DMN as a Business-Friendly, Tool-Independent, and Fully Executable Decision Modeling Language.” Because these define DMN’s fundamental promise: First, business users, this language is for you; second, it works the same in any DMN tool; third, and most important: what you model is what you execute. That is a powerful promise, because it lets business people themselves define and maintain the decision logic that drives their critical operations, in contrast to traditional practice in which they are limited to writing requirements for programmers who have no direct knowledge of the business. And this promise is disruptive. If DMN is able to fulfill it, it will change both the practice of decision management and the competitive landscape of decision management software.

Fulfilling the promise requires implementation of all 3 of DMN’s key attributes – business-friendliness, tool-independence, and executability. And that in turn requires adoption of a standard expression language. DMN defines one, called FEEL, that is both business friendly and rich enough to handle real-world decision logic, along with a tabular decision logic format called boxed expressions. Surprisingly, however, DMN tools are not required to implement them. While FEEL and boxed expressions are essential to DMN’s promise, the struggle over their implementation continues, and is central to my story today.

So my talk has 3 parts. Part 1, The Promise, gives a little background on DMN and its promise, and what realizing that promise will entail. Part 2, How the language works, explains how DMN models defined entirely through diagrams and tables can be executable. And Part 3, Meeting the Implementation Challenge, discusses the difficulties that 3 months ago made it look unlikely that DMN would ever deliver on its promise, and ends with recent developments that suggest that DMN is not only likely to achieve its promise after all, but will begin to do so this year.
Three months ago, when I began thinking about this talk, it seemed unlikely that DMN would ever fulfill its promise, because even the objective of full business-empowerment was not widely shared by its key implementers, those active in the DMN task force in OMG.

Maybe, they said, DMN should simply provide a model-driven way to generate business requirements. Programmers would then translate those requirements into a tool-specific rule language for execution. That is much better than the current practice of text-based requirements documents, and it would make DMN implementation much easier. Others said, we can do more than that. Business should be able to model the decision logic, not just the requirements, and test it for completeness and consistency. But a business-friendly decision modeling language must be limited, they said, to simple things, like decision tables that select from an enumerated list, and simple arithmetic expressions. But that’s it. For anything more, you need to exit the standard and go back to writing requirements for programmers.
In fact the DMN spec itself, recognizing this diversity of opinion about the objectives, formally blesses the idea of partial implementation, defining 3 levels of DMN conformance. Conformance Level 3 embodies the full promise, the disruptive vision, including model-driven decision requirements, business-friendly decision logic definition, and support for FEEL, a tool-independent executable expression language. It provides all 3 legs of a strong stable platform…

Level 2 says, yeah, all of that… except the strong part. Because we don’t think business users are ready for FEEL. So we’ll just use a tiny subset of FEEL, called Simple FEEL or S-FEEL. It’s limited to decision tables that select from enumerated values and can do simple arithmetic. If your logic needs more, leave that to the programmers. Because we don’t think business users want to deal with that kind of logic. So Level 2 is also a stable platform, but a weak one. It won’t hold much weight. If you want to carry any weight, you will need to exit the standard language and let the programmers do it.

And Level 1 says, actually business users don’t want to even think about decision tables and other kinds of decision logic at all. They just need a better way, a model-driven way, to define business requirements for the programmers. Level 1 is business-friendly and tool-independent, but the logic is not precisely defined, so it cannot be tested. So this is like a 2-legged stool. Long-term, we know how that goes.

And there is also another level, call it Level 2a, which was not anticipated by the DMN spec, in which the tool provides advanced FEEL-like expressions – but uses the tool’s own language. So it’s business-friendly, executable, but not tool-independent. That’s actually another 2-legged stool, and not so different from what the commercial decision management suite vendors already offer.

I say fulfilling the promise seemed unlikely because, among those vendors active in the DMN task force, only one seemed to have any interest in implementing Level 3. It was just too hard, and besides, Level 1 and 2 already offered a big improvement over current decision management practice. It was not just that partial implementation was a faster way to get a tool to market. Vendors were arguing that generating requirements for implementation in some other engine-specific rule language was a viable long-term strategy. I found that consensus deeply disappointing, because the lesson of BPMN over the past decade is that in the long run, that approach doesn’t work. The promise that works is What You Model is What You Execute.
And then, suddenly, things started to change. In April, at bpmNEXT, my own annual BPM technology conference, Oracle demonstrated for the first time in public a Level 3 implementation including FEEL and boxed expressions. One vendor told me recently that seeing that for the first time made them understand how those things worked in a tool, and the light bulb suddenly turned on. Then Trisotech demonstrated their DMN editor that can draw full Level 3 boxed expressions, and promised complete Level 3 execution in a few months. Even Sapiens Decision, known for their own modeling language called The Decision Model (TDM), flashed a bit of DMN and suggested they were working on full DMN. And the Workflow Management Coalition, another BPM standards organization, proposed an initiative to help all DMN vendors with tools, test suites, and code for Level 3 implementation.
The wheels were suddenly turning! Here at this conference you are seeing another step forward since April. And after this event, I believe other tool vendors may begin to question their original partial implementation strategy, which only works when no one is doing the real thing.

To understand DMN’s promise, we need take a closer look at the problem it is intended to solve. A decision model describes the logic of a business decision in terms of a set of rules acting on the decision inputs. Given specific values for the inputs, the decision logic determines an output value, the outcome of the decision. That’s all it does. Some wish it went farther. For example, Jacob Feldman is always saying DMN should allow you to define constraints on the inputs and then find the input set, and possibly the ruleset, that, given some goal metric, generates the optimum output value. Now that’s a really interesting problem, but that’s not what DMN tries to do. DMN just says, given a particular set of input values, what is the output value? I admit that is kind of pedestrian, but in fact it is the logic that determines whether your mortgage is approved, the price you pay for insurance, and whether you get that business class upgrade. So decision modeling comes down to defining the inputs and the decision rules, and their dependencies on other inputs and rules.

Decision management for many years was called business rule management. The change in terminology, and DMN’s strong association with that change, signifies a break from the traditional practice of business rule management, which asked the business to start by hunting down and harvesting all the rules buried in application code, in policy manuals, processes, and in the heads of subject matter experts, so they might be centrally managed and executed on a business rule engine. The harvested rules are written down in the form of text-based business requirements, which are given to programmers for translation into a rule language specific to a particular business rule engine. But text-based business requirements are notoriously vague and internally inconsistent, resulting in user acceptance problems, and so the cycle repeats. And that’s not the only problem. Over time, in decision-intensive businesses like financial services, the organization will accumulate thousands of rules, so simply managing them, refactoring them to deal with changing business requirements becomes extremely difficult.

Hopefully you see some of the problems here:
- If the goal is implementing decision logic, harvesting business rules is not an efficient way to start. Most of the harvested rules are not relevant to the decision of interest.
- Text-based business requirements documents lack the ability to ensure rules are complete and consistent.
- Tool-specific rule languages create vendor lock-in and higher cost of maintenance, support, and training.
- Translating business requirements into program code means Long development cycles and high project failure rates that work against today’s key imperative, business agility.
A decade ago, a new idea called decision management began to challenge this traditional practice. James Taylor’s Decision Management Manifesto introduced the “Decisions First” mantra, attacking the practice of starting by harvesting all the rules. Instead, he said, business users should start by understanding the decisions they want to make and the information they require. The rules follow naturally from that.
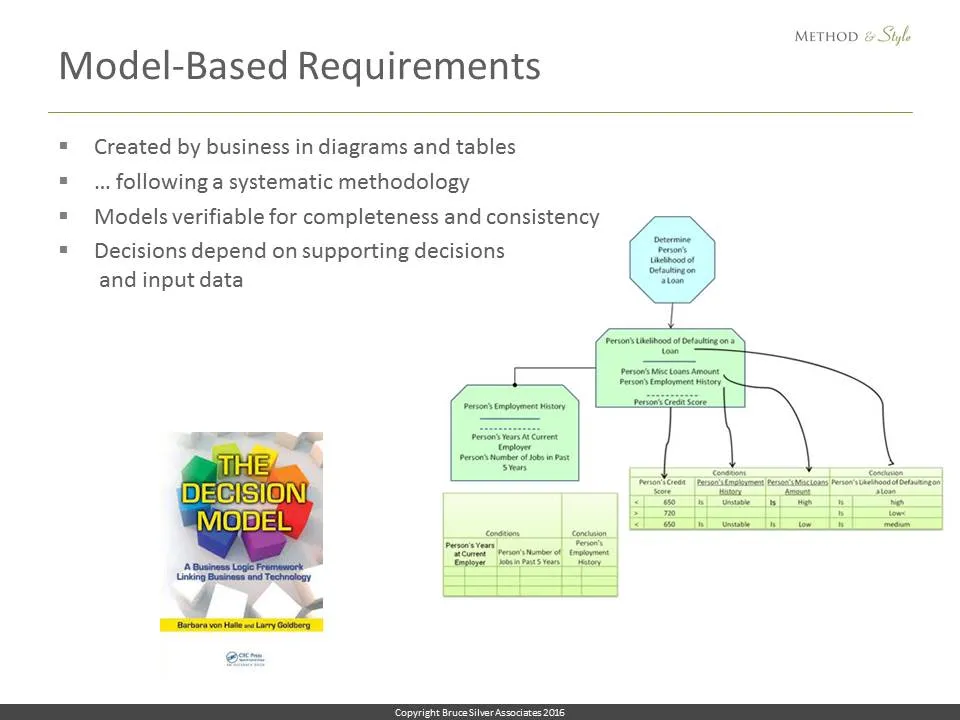
Then Barb von Halle and Larry Goldberg of KPI, now Sapiens Decision, introduced a business-oriented, but rigorous and systematic, approach to decision management that replaced text-based business requirements with decision models based on a strict set of formats, principles and guardrails, verifiable for completeness and consistency, and more easily maintained. This discipline, called The Decision Model or TDM, emphasized the fact that business users, given proper tools and methodology, are indeed capable of defining and managing complex decision logic themselves, even in large-scale production environments, and this approach proved successful in dramatically improving business agility.
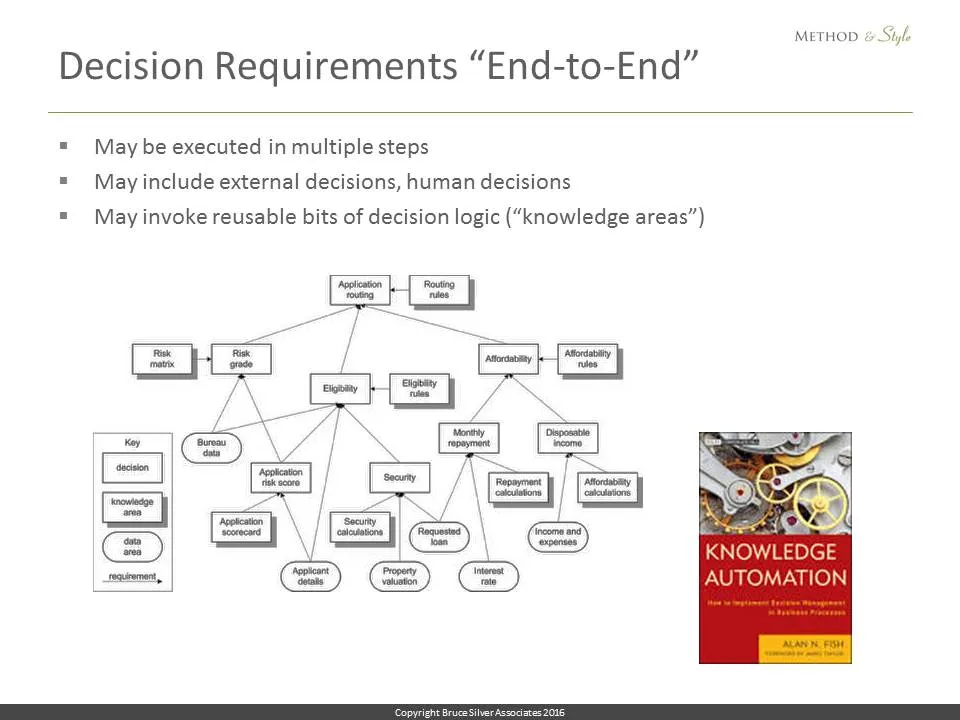
TDM diagrams focused on the logic of individual decisions, or what DMN would call an individual decision service. In his book Knowledge Automation, Alan Fish of FICO introduced the notion of end-to-end decision requirements diagrams (DRDs) representing business decisions executed in multiple steps, including external decisions and human decisions.
Ideas like these were successful in improving the cycle time and success rate of decision management projects. But none of them addressed the proprietary, tool-specific nature of decision modeling. That requires a standard language, independent of any tool vendor or consulting company. Thus was born DMN.
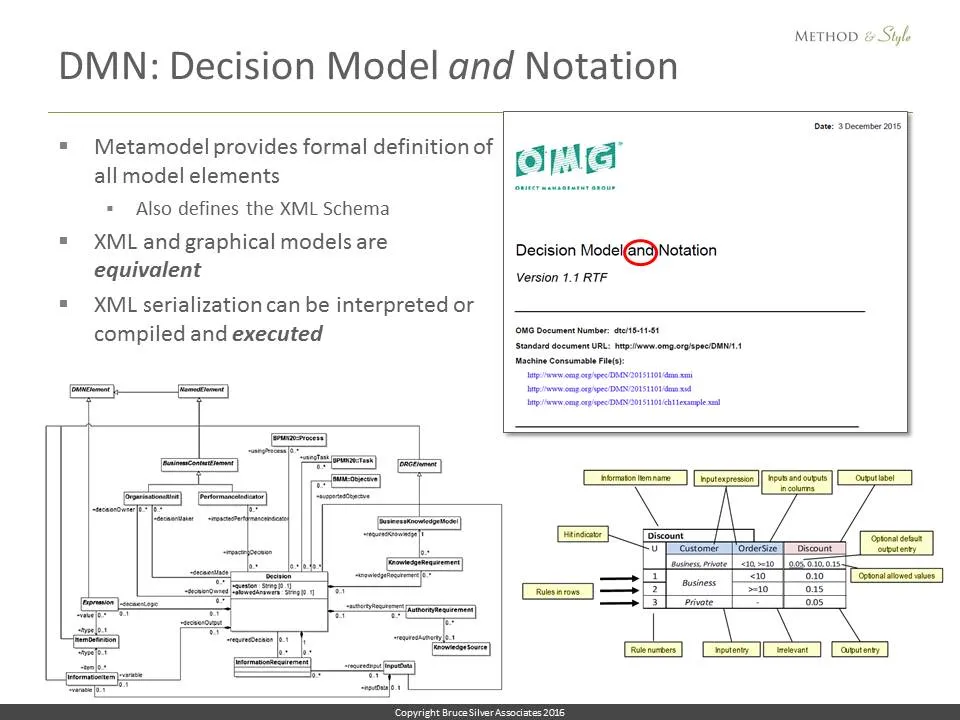
DMN stands for Decision Model and Notation. The “and” is an OMG thing. It means that in addition to a graphical notation, DMN provides a formal metamodel that precisely defines the diagram elements, their attributes and behavior, and a schema for xml serialization, so that the model is not just an outline of the decision logic but a complete executable form of it.

Think about this for a minute. You have a decision model, a diagram of end-to-end decision logic, composed of multiple decision nodes, each with some tabular definition of its rules… And this model not only communicates the logic visually to the business but is actually executable on a DMN engine! All the logic defined visually through diagrams and tables is captured in computable form, as XML. The visual decision model and its XML serialization are equivalent. You can generate one format from the other.
The XML representation of those diagrams and tables can be executed on a decision engine. So… like BPMN, DMN embodies the dream of a common language shared by business and IT. The decision logic, end to end, even if it requires multiple steps, can be defined by the business people themselves. Because that logic is model-based, it is verifiable for completeness and consistency at design-time. And here is the best part: the meaning of the diagrams and tables does not depend on the tool that created it. It’s defined in a spec. The formats and syntax of the language are both tool-independent and executable. Provide it with values for the inputs, and the engine can determine the value of any decision node in the DRD. For high volume production, of course, you could also map the DMN XML to the rule language of a commercial rule engine.

Now.. you can have all the diagrams and tables you want, but to make them executable and tool-independent, the text in those diagrams and tables requires a defined syntax, i.e., a standard expression language.
Now we’re getting to the heart of the matter. Because that expression language needs to be both business-friendly and at the same time rich enough to handle real-world decision logic. The original DMN task force struggled with this. Some were against any formal expression language. Some wanted their own rule language. In the end, Gary Hallmark of Oracle won the day with his contribution, a brand new expression language called FEEL, and a tabular format for assembling those expressions into something like program statements, called boxed expressions.

So DMN, as defined by the spec, is really 5 things rolled into one:
- Decision Requirements Diagrams
- Standard formats for decision tables
- A standard expression language, FEEL
- Standardized tabular formats for all decision logic, called boxed expressions
- XML serialization based on a formal metamodel

But partial implementation, Conformance Levels 1 and 2, don’t require all 5. Conformance Level 1 says you just need #1 on this list, the DRDs.

Conformance Level 2 means DRDs and decision tables conforming to S-FEEL S-FEEL is very simple, just basic arithmetic expressions and comparison tests. It can’t do string manipulation or date-time arithmetic or table queries, but its logic can be verified for completeness and consistency, and has the possibility of being mapped to tool-specific rule languages for more advanced decision logic. So It’s a lot better than Level 1 but still not the real deal.

Conformance Level 3 is the real deal. But there is a complication. DMN does not require FEEL as the expression language; it’s just the default. Technically a tool could use Java or something else. That’s allowed. But… conformance level 3 is specified in terms of FEEL only. If a tool implements some other language, the meaning of the model is no longer tool-independent.

I mentioned at the beginning that I’ve seen that movie before, with BPMN. BPMN was originally just a diagramming notation, not executable. Around 2005, BPM vendors like IBM, Oracle, and SAP thought that was OK because BPMN models could be translated into a similar process execution language called BPEL. By 2008 it was clear that customers did not agree. Even though BPMN and BPEL were similar, the languages were not the same. Certain things you could draw in BPMN you couldn’t execute in BPEL, and vice versa. The whole magic of BPMN’s promise to the business – that what you model is what you execute – proved false, and it was the beginning of the end for BPEL in BPM. So IBM, Oracle, and SAP rushed to develop BPMN 2.0, which unified the diagramming notation with execution.
And that worked. With BPMN 2.0, what you model is what you execute. It transformed the BPM software industry. IBM for example, the number 1 vendor in that space, essentially walked away from its own BPEL based offering in favor of tiny BPMN-based acquisition. Suddenly you had startups offering new BPMN tools, new open source implementations. BPMN 2.0 utterly changed the industry landscape.
Now DMN is trying to do in one step what it took BPMN almost a decade to accomplish. Is that too much too fast? Maybe so. Long term, however, I am convinced that the need to translate DMN models into some other language for execution is not viable.

Some vendors possibly fear that if DMN Level 3 runtimes are widespread, they will be commoditized out of business before the market gets off the ground. I disagree, because even Level 3 leaves a lot of business value outside the scope of the standard. DMN does not include any of these elements of a so-called “whole product”:
- A graphical interface for modeling data
- a business glossary
- A way to incorporate constraint rules
- Anything to do with methodology, or governance
- Anything to do with testing and analysis
- Anything to do with execution, access to physical data, fault handling, or performance optimization
Real DMN tools are going to compete, and succeed or fail, based on those things, even if an open source executable FEEL library becomes freely available.

With that as background, let’s see how DMN as a language works…

First, what is a decision? As we said, it’s determination of an output fact value from a given set of input fact values, where a fact, in DMN terminology, is a variable with a specified domain of allowed values. In DMN, each decision is comprised of a variable that holds its output value, and a value-expression that contains the logic that determines that value. DMN’s value expressions are based on decision rules: if condition1 is true and condition2 is true, then the output value is X. Decision rules are a class of business rules, but not all business rules are decision rules. For example, constraint rules are not decision rules.
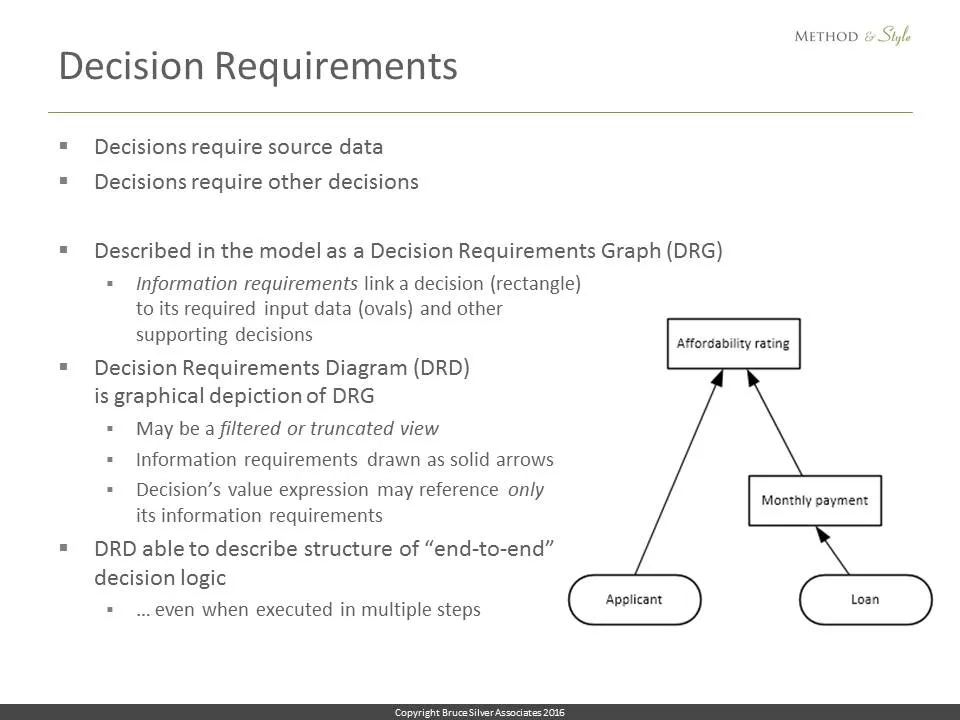
Decision requirements. Going all the way back to the decision management manifesto, we know that decisions require information in the form of source data and supporting decisions. DMN describes these dependencies in the form of a Decision Requirements Graph or DRG, the complete network of all supporting decisions and input data required by any decision node. The visualization of a Decision Requirements Graph, is called a Decision Requirements Diagram or DRD. Rectangles in the DRD are decision nodes, ovals are input data. The value expression for any decision node may only reference other DRD nodes directly connected by information requirements, the solid arrows. So the decision Affordability rating here only depends on the variables Applicant and Monthly payment.
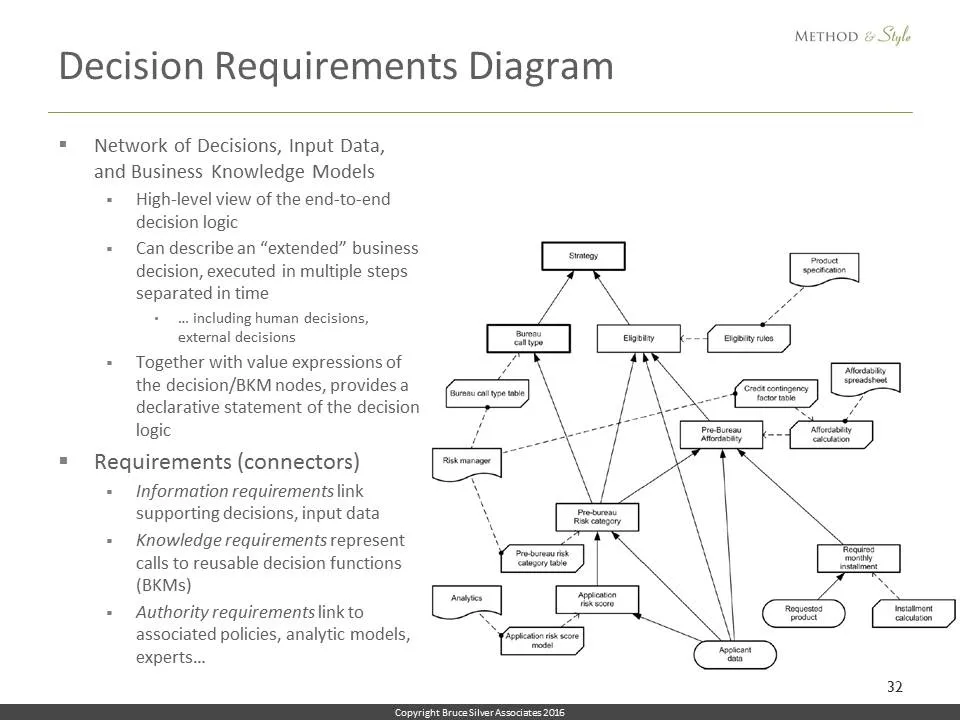
A DRD can show additional information. The rectangles with clipped corners, called business knowledge models or BKMs, represent reusable bits of decision logic invoked as functions by one or more decision nodes. The wavy bottom shapes called knowledge sources are effectively annotations describing the basis for the logic, such as policies or analytical models.
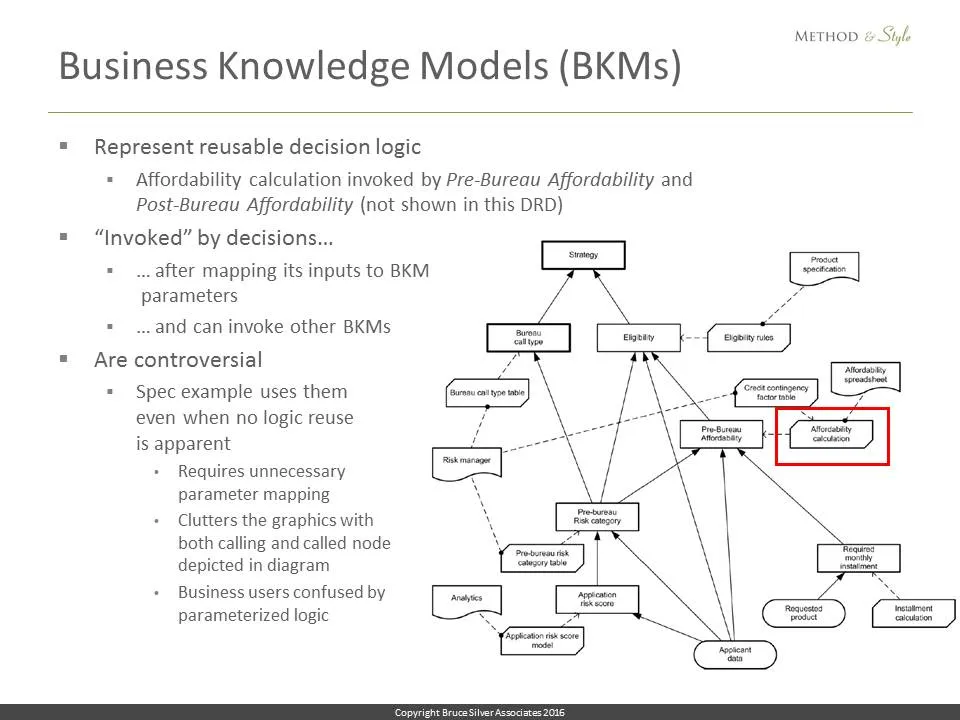
BKMs, it turns out, are somewhat controversial. The way they are represented in the diagram, displaying both the calling decision and the called BKM, is not popular with implementers, and many tools do not support them at all. The spec, however, requires a BKM for reusable or iterated decision logic.
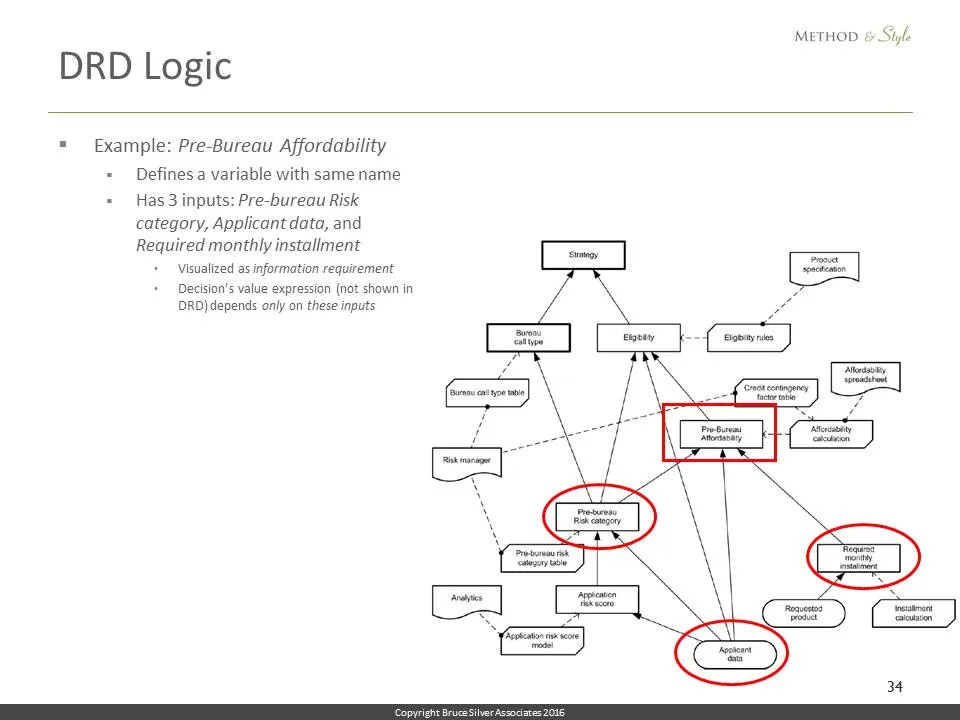
This example illustrates the mechanics of a DRD. Let’s look at the decision Pre-Bureau Affordability. It defines a variable of the same name. It has 3 inputs: Pre-bureau Risk category, Applicant data, and Required monthly installment, so its value expression can depend only on those 3 variables.
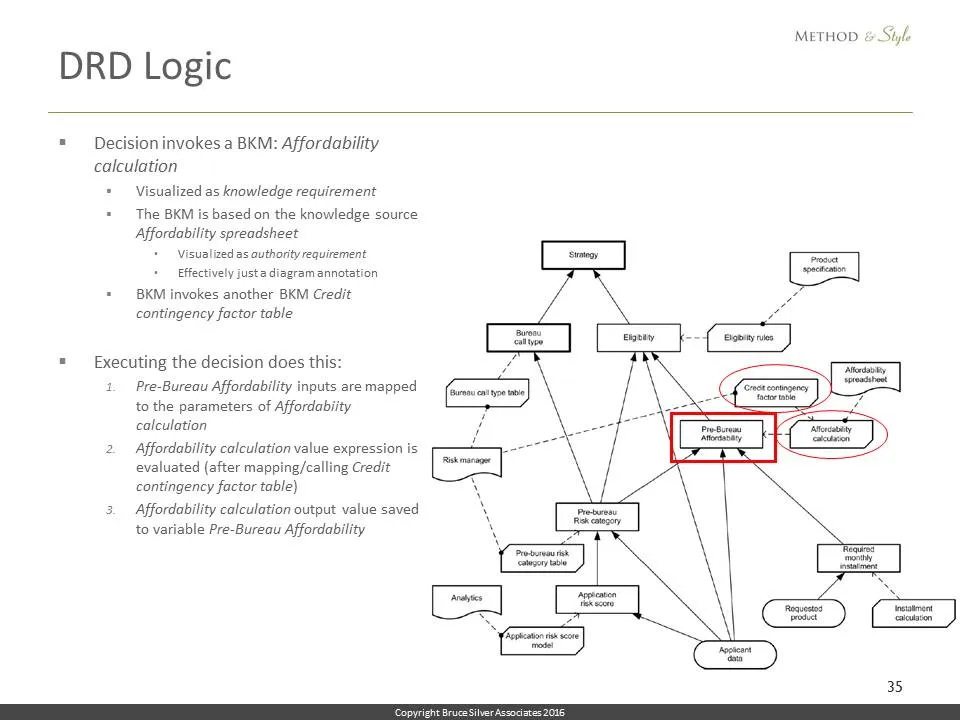
The decision invokes a reusable function, the BKM called Affordability calculation, as indicated by the dashed connector. So when the decision Pre-Bureau Affordability executes, first it maps its inputs into the parameters of Affordability calculation, which invokes in turn the BKM Credit contingency factor table. The output value of the BKM Affordability calculation becomes the output value of the decision Pre-bureau Affordability. The explanation is tedious, but all of this is implied simply by the dashed arrows, the knowledge requirement connectors.
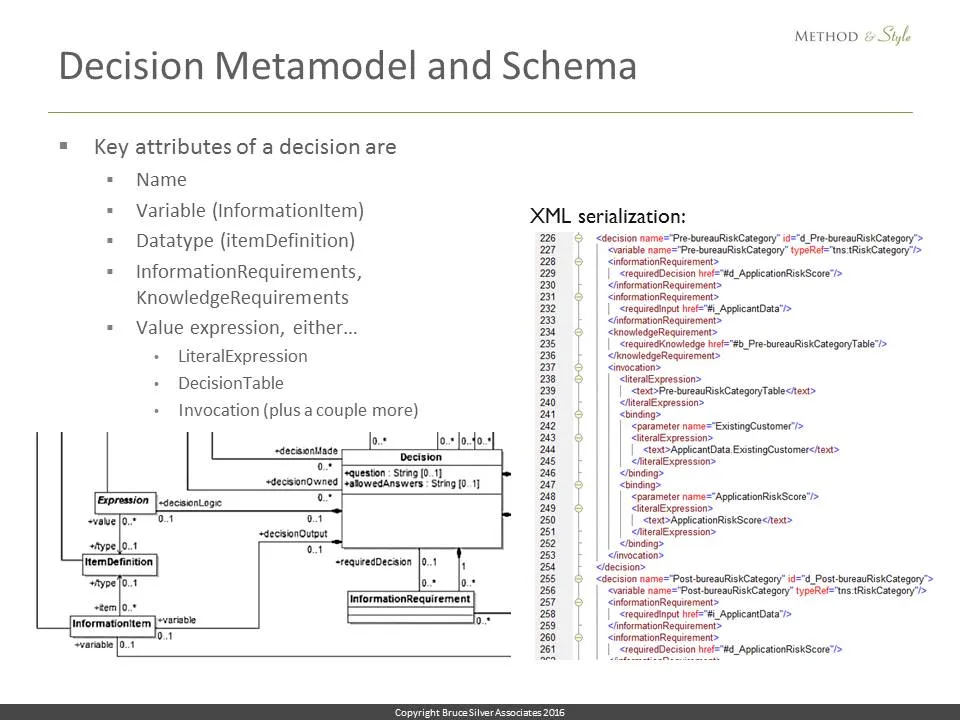
On the left here you see a fragment of the metamodel for a decision, a UML class diagram, showing the links to its information requirements, its value expression, and its associated variable. On the right you see the XML serialization of a particular decision, in which the xml elements correspond to those defined by the metamodel.

The most common format for a decision’s value expression is a decision table, for which DMN allows a variety of layouts. This one is the default, called rules-as-rows, where the columns represent decision inputs and outputs. The heading row defines their names and allowed values, and the rows below that define the rules. Each input cell in a rule, called an input entry, when concatenated with the input heading defines a Boolean condition. If all conditions in a rule are true, the rule is said to match and the expression in the output column is selected as the decision table output value. There may be multiple output columns, as you see here. The hit policy code in the top left specifies what to do if multiple rules match. Except for a couple of semi-deprecated hit policies, decision tables are fully declarative; neither the order of rules nor the order of inputs changes the result.

Decision tables and other forms of decision logic contain expressions. To be both executable and tool-independent, DMN requires a standard expression language for those: That is FEEL, which was settled on after long and contentious debate. Languages like UEL were rejected as not business-friendly. There were some who advocated using the Excel formula language – by definition, business-oriented – but in the end DMN invented its own language.
So far, DMN vendors have been slow to implement FEEL. Often they say it is not business-friendly. Is that the case? Consider this decision rule, in natural language, for the decision ApprovalStatus:
If Risk is “Low” or “Medium” and PTI<0.3 then “Approved” else “Declined”
Here it is in Excel formula syntax:
=IF(AND(OR(Risk="Medium",Risk="Low"),PTI<0.3),"Approved","Declined")
Here it is in FEEL:
if Risk in ["Low", "Medium"] and PTI <0.3 then "Approved" else "Declined"
Now you tell me, which is more business-friendly!
One reason why FEEL has not been readily adopted is parsing it is difficult, since variable names may contain spaces. Making FEEL easier to implement is a current topic in the DMN 1.2 task force, and there is inherent tension between ease of implementation and business-friendly syntax. (By the way, the business-friendly syntax side is winning.) In spite of this, we will see commercial FEEL implementations in 2016, which is good news, because FEEL implementation is critical to DMN’s long-term success.

Like other languages, FEEL is formally defined as a set of grammar rules. You see a snippet of that here.
FEEL is a strongly typed language, with a small number of base types, from which DMN can define any number of custom types, including complex types using a dot notation. The name Customer.Age means the component Age of the variable named Customer.
FEEL has a rich set of built-in functions, effectively a subset of the XPATH built-in functions, and modelers can define and invoke custom functions as well. It includes filter expressions for table queries and joins. For example, Order.item[price<100] selects from the table variable Order all child elements item for which the attribute price is less than 100. It can perform sorting, if..then..else logic, and iteration. So you don’t need to exit to SQL for queries or to BPMN for iteration, since these are already built into FEEL. But the richness of the language is undoubtedly a barrier to its implementation.

But FEEL is just an expression language. It does not have statements that create variables and assign values to them. Of course, you need those things for execution, so where do they come from? Actually, they are defined graphically, in the DRDs and in tabular structures called boxed expressions. Aside from decision tables, most boxed expressions are basically 2-column tables. The first column names a variable; the second column is its value expression, typically just a FEEL expression but possibly a nested invocation or decision table. Theoretically a boxed expression could have unlimited levels of nesting.
Here, at the top you see a simple boxed expression for an invocation, mapping the decision inputs to the called BKM parameters. Below the first row of the table, which names the BKM, each row contains the name of a BKM parameter in the left column, and its mapping expression in the right column.
The bottom diagram is a boxed expression for the BKM Installment calculation. It has 3 rows, called a context. The first 2 rows define local variables – here Monthly Fee and Monthly Repayment – and their associated value expressions. The last row of the context, without a variable, holds the final result. The formats of a boxed invocation, boxed context, and other forms of boxed expression are similar, and are defined by the DMN standard. Like FEEL, however, so far few tools have chosen to implement boxed expressions.

So let’s recap…
DMN includes 5 key elements: DRDs, decision tables, xml serialization, FEEL, and boxed expressions. To realize the promise – visual description of the decision logic using diagrams and tables, tool independence, and executability, what you see is what you execute – you need all 5. Partial implementation means giving up on one or more of those goals. It means DMN is no longer a complete decision modeling language, but more of a framework for requirements gathering. Complete implementation, on the other hand, has this very interesting property, which is that the end to end decision logic has 2 equivalent representations: Graphical, as a set of diagrams and tables, OR… Serialized as XML. You don’t need both to completely specify the model. Either one will do, since you can generate each from the other. One is visual, great for shared communication. The other, the XML serialization, is directly executable.

Implementing DMN Level 3 requires drawing boxed expressions, including contexts that nest invocations and other contexts. And it requires parsing, validating, and executing FEEL. If these things were easy, we’d have lots of tools doing them already. They are not.

I have been using the term executable, but that doesn’t mean a modeling tool must include a production DMN runtime engine. What I mean is that at design time, given values for all the input data, the tool can display the resulting output for any node in the DRD. Modelers need that for verifying the decision logic they are defining. So we’re talking about test data, logical data, not physical data extracted in mass quantities from real production systems and databases. If you need to handle large datasets in production, or execute the decision logic very fast, you still may want to map the DMN model to the rule language of a commercial business rule engine.

So… You have an end-to-end decision model created graphically as a DRD, with the value expression of each decision node and BKM defined graphically as a boxed expression. In those boxed expressions, all the literal expressions use FEEL. Now the xml serialization of that model can be executed.
You start by providing values for all of the inputData elements. The goal is to generate values for all of the decision elements in the DRD. DRD logic is inferential; there is no particular order of execution specified. You can do it in a forward chaining manner or backward chaining or something in between.
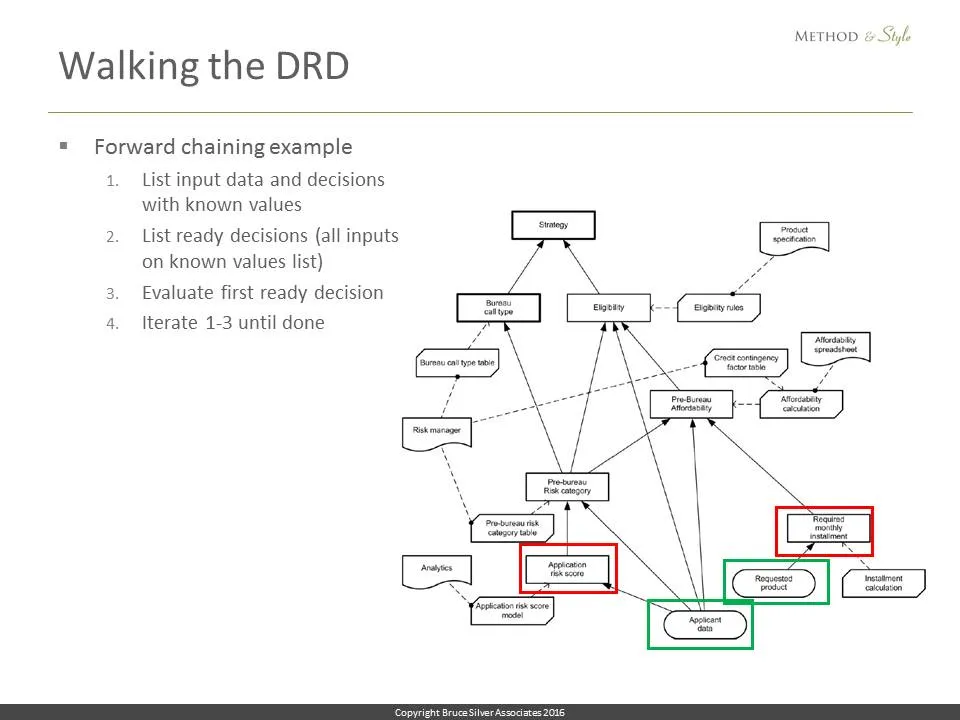
Actually, walking the DRD is the easy part. Here is how it might be done with forward chaining. First, generate a list of all elements with known values. To start, that would be the inputData, outlined here in green, Applicant data and Requested product. Then generate a list of all decisions ready for evaluation, meaning all their information requirements are in the known list. Those are the nodes outlined in red, Application risk score and Required monthly installment. Then pick one of the ready nodes, and evaluate it.
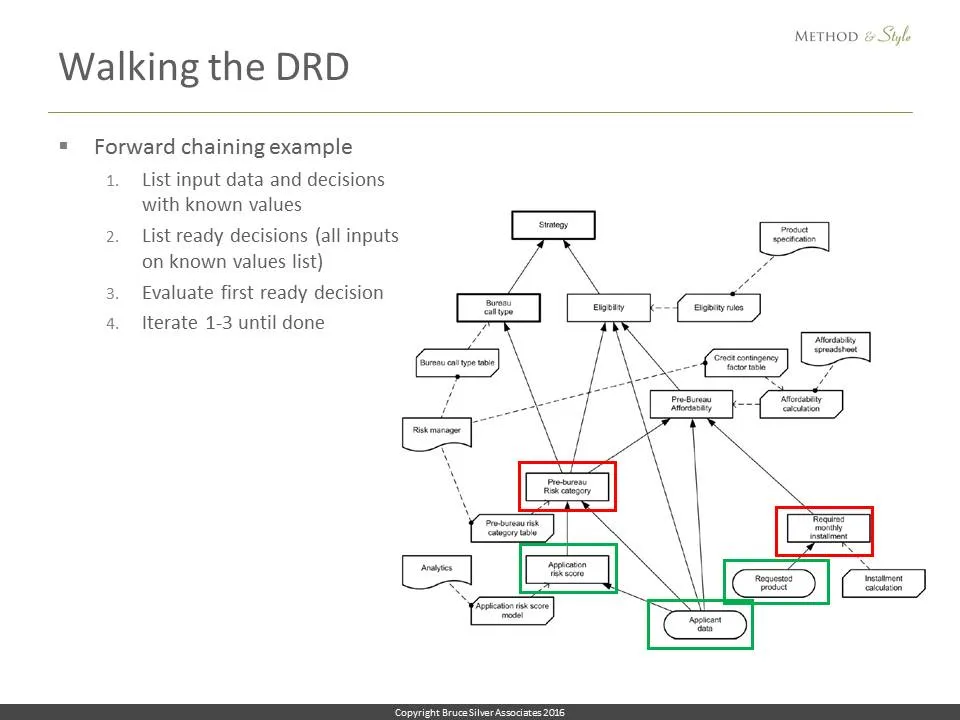
Let’s say we picked Application risk score. Evaluate it, and add that decision to the known list, and repeat the procedure. Now the ready nodes are Pre-bureau risk category and Required monthly installment. We just iterate this procedure until all the decision nodes are green.

That part is easy. The hard part is executing FEEL. One thing that makes it hard is FEEL’s insistence that business-friendliness requires that variable names look like business terms, not variables in a programming language. So they can contain spaces… Most executable languages avoid that because it complicates parsing. And not only can names contain spaces, they can contain arithmetic operators like + and /, and words like and that also serve as logical operators in the language, and periods – normally used as a path operator or name qualifier – and also xml-unfriendly characters like apostrophe.
So in order to tell what is part of a name versus an operator, a function, or a syntax error, the parser must continually refer to the names in scope, determined by the information requirements of the node being processed. In addition, the names of built-in functions also contain spaces, and the grammar itself is context dependent. For example, the + operator could mean addition or it could mean concatenation. You need to evaluate the operands to tell which one.
As the DMN 1.2 meetings began a couple months ago, given that vendors were rejecting FEEL en masse, these all seemed to me to be self-inflicted wounds. But in those meetings, all my efforts to reduce these barriers to FEEL implementation have so far been shot down as “business unfriendly.” So we just have to deal with it.
Here you see a FEEL expression string to be parsed. Abc.com is the namespace of the variable customer list. We know it’s a namespace because it appears in the list of imports to the model, so the period here is part of the namespace name. The next period is a path operator, or name qualifier. The brackets indicate a filter expression, identifying elements in the customer list, a list variable, that satisfy a condition. The condition refers to the component of customer list called customer’s first + last name. That whole thing is a name, which we know because customer list is a variable in scope and its datatype definition references a component with that name. Yes the + and apostrophe are part of the name. OK, you get the picture. For the implementer, parsing FEEL this way is kind of annoying, but not impossible.

Parsing is not the only hard part. Implementers need to map all the built-in functions, operators, and other features of the language to a language they can execute. And this is challenging as well, because FEEL is quite rich in functionality. It has 45 built-in functions, some of them tricky, like string replacement using regular expression patterns, inserting an item into a list variable, date/time arithmetic, and sorting. It supports invocation of user-defined functions, filter expressions, iteration, if..then..else expressions, and a lot more. The benefit of this richness is you don’t need to exit DMN to do the complete decision logic. For example, you don’t need to exit to BPMN to iterate a decision. You don’t need to exit to SQL to do a table query or join. You can do all of this right inside your FEEL expressions. That is a really good thing.

OK, well 3 months ago, as I said, except for Oracle – who invented FEEL – no DMN tool vendor seemed inclined to touch it. Not business friendly, they said. Too hard to parse. Those built-in functions… If I need a programming language I’ll use java not implement a new one. For me the killer was always “our customers are not asking for it.” No kidding! Modelers could never do this before. How would customers know to ask for it? Instead most vendors claiming DMN support seemed content to create DRDs, possibly also level 2 decision tables, that simply feed requirements to programmers in some commercial rule language. But that was never the promise.
I found this surprising, because implementation didn’t seem like it was all that hard. Of course it would seem that way to me because I’m not a programmer. So naturally, I set off to do it myself.
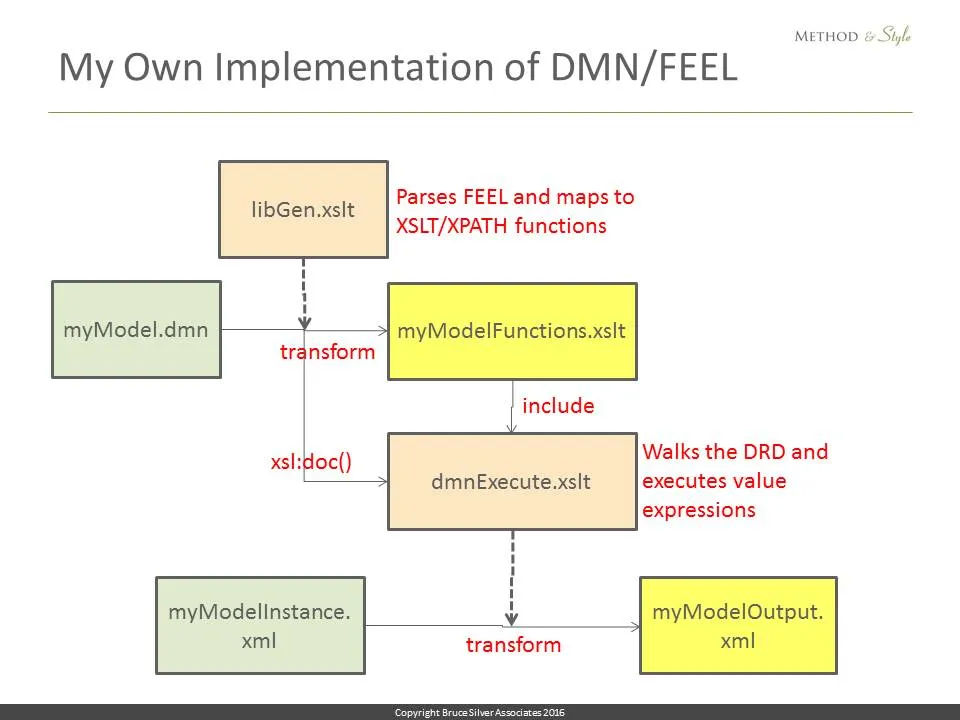
The only language I know is xslt and its sublanguage xpath. It transforms xml into other xml or html. But what made me think I could do it was the fact that the FEEL built-in functions and operators are essentially a subset of xpath functions and operators, so if I could do the parsing, the mapping to xpath would be easy. So here is a block diagram of what I did.
I created 2 transforms, libGen and dmnExecute, here in beige. libGen transforms the serialized model myModel.dmn, in green, to generate a custom function library, myModelFunctions, here in yellow. Every FEEL expression in the original model is mapped to an XPATH expression in myModelFunctions, referencing an element in the knownValues list generated by walking the DRD.
dmnExecute, which includes the myModelFunctions library, then transforms the set of input data instance values, myModelInstance.xml, into a list of DRD decision nodes and their output values.
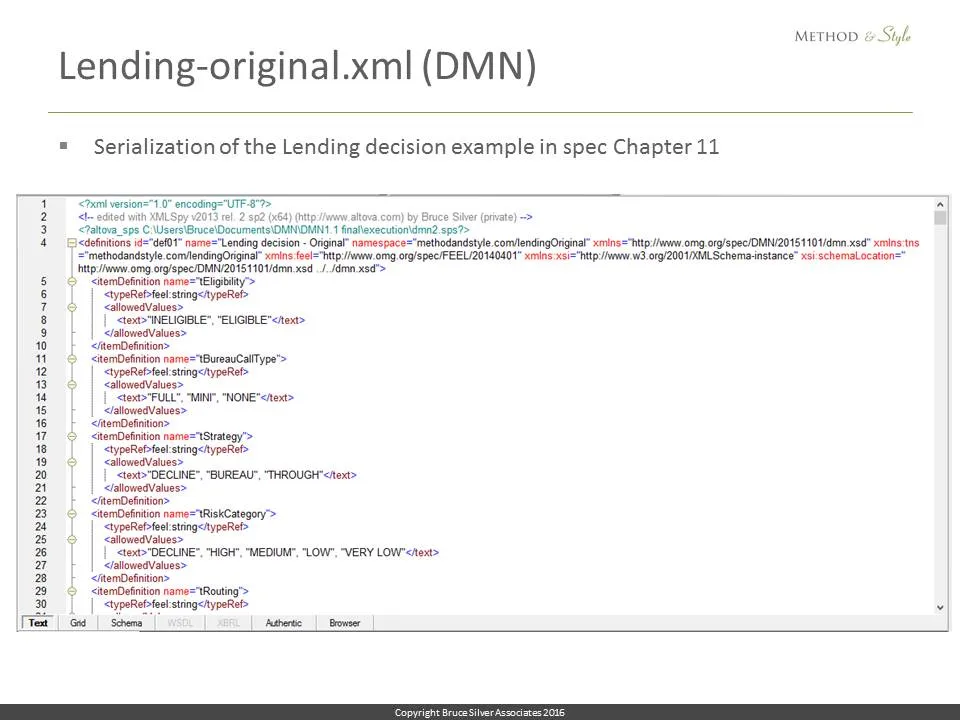
In chapter 11 of the DMN spec there is a detailed example of an end-to-end Lending decision. It contains a number of FEEL Level 3 elements, including if..then..else, contexts, nested function invocation, and the amortization formula, so it’s non-trivial.
OK so here is a fragment of my xml serialization of that decision model. I had to cheat in one important aspect, by removing the spaces from the names of the decisions and input data, to make parsing easier.
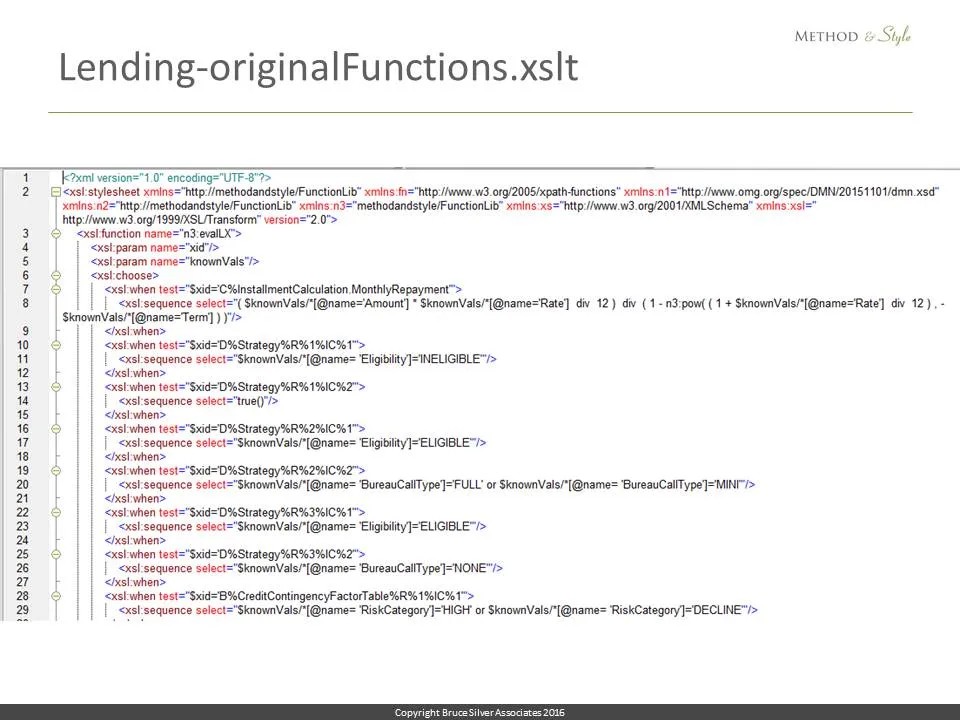
Here is a bit of the function library generated by libGen. Every FEEL expression in the original is mapped to an id and an XPATH equivalent of the FEEL expression, referencing the known values list.
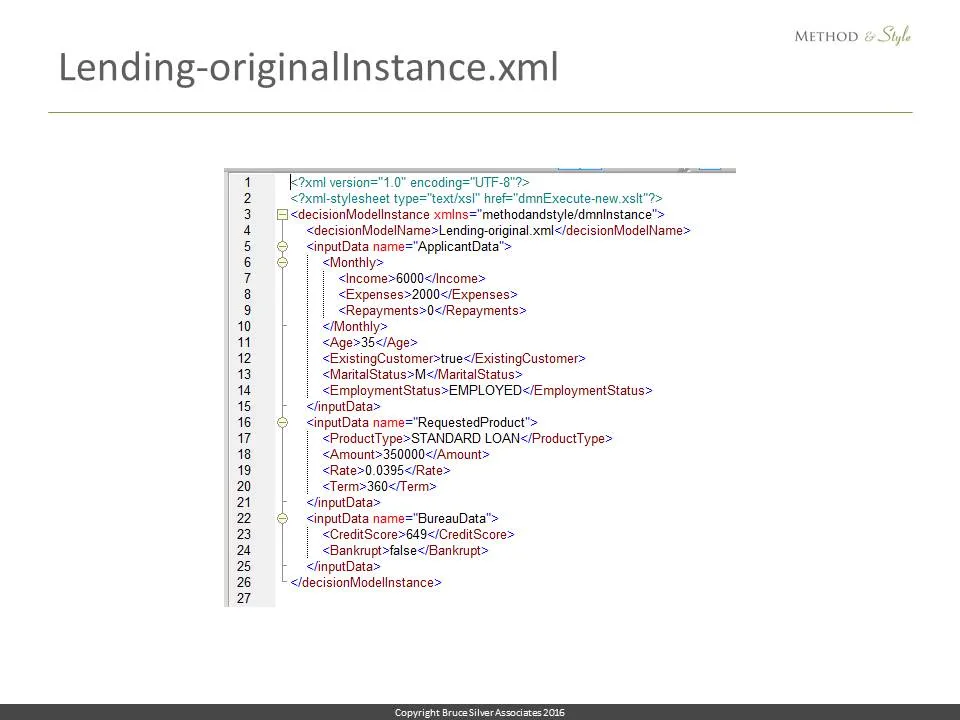
Here is the input data instance file, with values for ApplicantData, RequestedProduct, and BureauData.
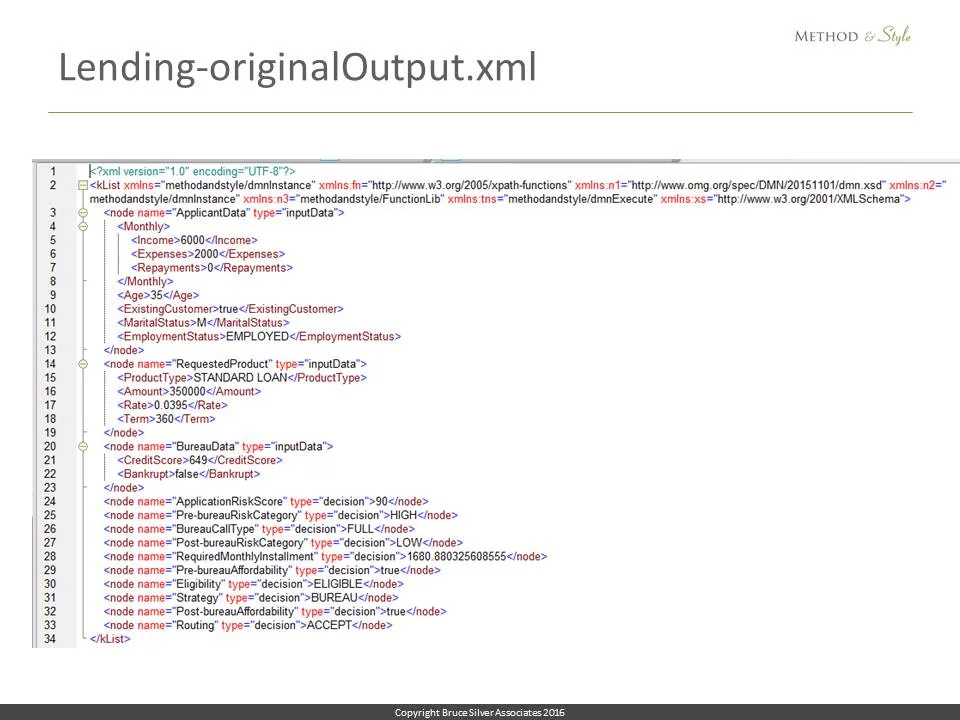
And here is the executed output, the final list of known values, including all of the decision nodes in the DRD. Now… that wasn’t so hard.
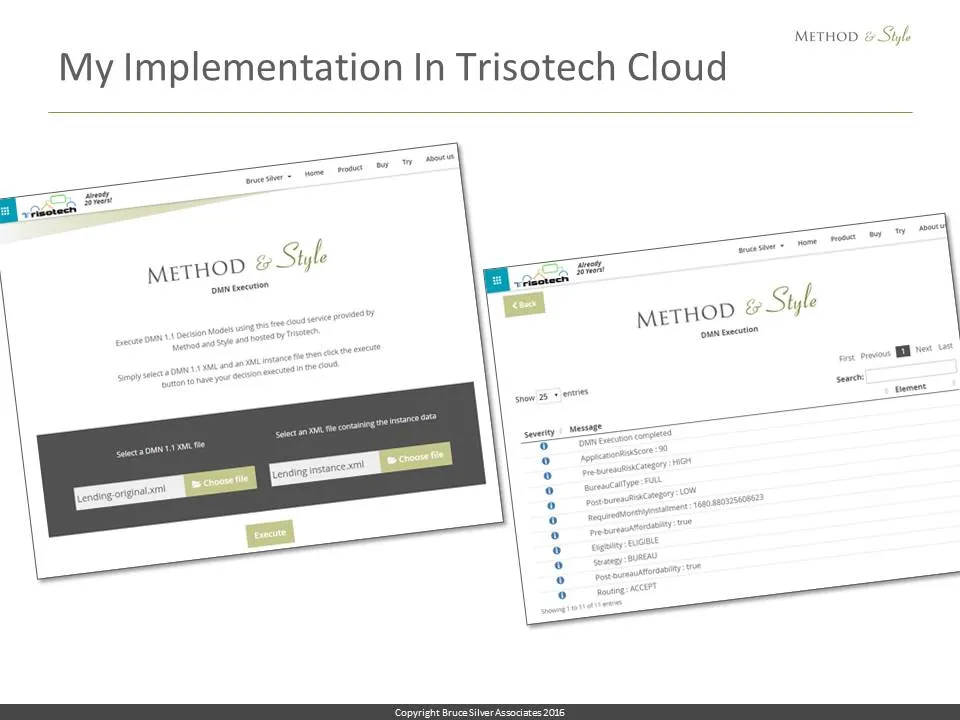
Of course, no one wants to do this manual 2-step procedure on some obscure tool like XMLSpy. But in an unbelievable gesture of goodwill, Trisotech offered to host it for me in their cloud using Saxon, including gluing together the 2 steps. I thought it would take them 3 months, but about a week later I got a message, it’s ready. So here it is, on the left: upload the model – lending-original.xml – and the inputdata instance file, lending instance.xml, click Execute. And the result is shown on the right. Pretty cool.
I mentioned that I kind of cheated by removing the spaces from the names in the example. But it has become clear to me now that spaces in names are fundamental to FEEL, so I am now redoing my implementation.
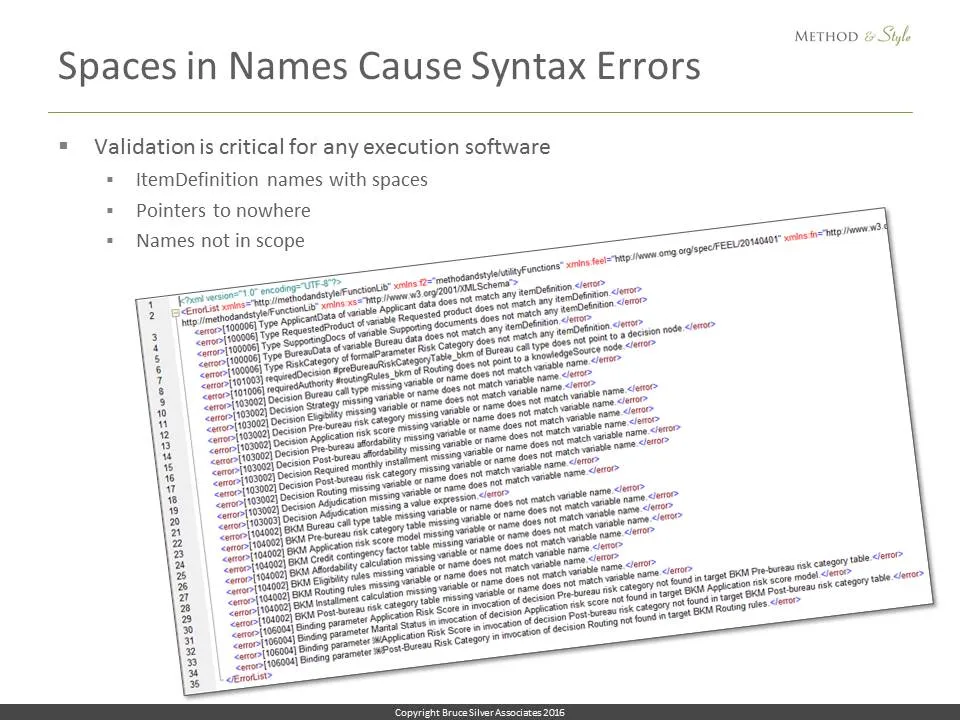
But here’s something I discovered: Having spaces in names not only complicates the parsing, but makes errors in the serialization much more likely, especially in this early phase when most xml examples are being created by hand. Pointers to nowhere because of a slight spelling discrepancy, or case mismatch between a name in FEEL and the name of the referenced decision. Errors like these cause my implementation to hang. So as soon as I started working with Trisotech on the cloud implementation, I realized I needed to include model validation in my code. Any real implementation is going to have to do this.
There are multiple levels of validation. The first level is just syntax checking of the model. The second level is done in conjunction with FEEL parsing; if an expression contains a name not in scope, that is an error. The third level involves runtime errors, things like an expression expects a number and it gets a string.
I quickly wrote some first level validation code and tested it on the Lending example serialization posted with the DMN spec on the OMG website. Unlike my own serialization, this one has the spaces in the names. I expected it to be clean, but surprise! 32 level 1 validation errors! So… Before we have execution, DMN modeling tools MUST be able to generate only valid xml serializations. Generating the xml by hand, obviously what happened in this case, is a losing proposition.

I started my Level3 execution project when nothing else was available and it looked like nothing else would be available anytime soon. Today, that is no longer the case. At this conference you have seen, or will see, a number of real tools on the path to delivering the real thing.
- Oracle is demoing the latest build of their tool, with full support for FEEL and boxed expressions, but does not yet support DRDs. The DMN tool should be available later this year as part of the Oracle Process Cloud Service.
- Trisotech currently offers a DMN editor supporting DRDs, FEEL, boxed expressions, and xml export. Execution currently is limited to decision tables with S-FEEL, but they should have full Level 3 later this year.
- OpenRules has in beta a full FEEL implementation, open source. It can import DMN xml but It does not yet have boxed expressions or xml export. OpenRules is committed to full Level 3.
- RedHat, maker of DROOLS, is working on a full Level 3 implementation, open source, available this Fall.
- The Workflow Management Coalition project for DMN Level 3 is just getting going. It will provide a DMN Technology Compatibility Kit, including test cases for all the Level 3 features and capabilities, validation code, and maybe some running code.

In addition…
- Sapiens Decision is working on a standalone DMN modeler. It will support FEEL but not sure if it is full Level 3. DMN models will be mapped to TDM for governance and production.
A number of vendors have produced Level 2 or 2a implementations but are waiting for customer demand to go all the way to Level 3.
- Signavio is committed to get there eventually.
- FICO and Camunda I would describe as wait-and-see. But once full Level 3 implementations are released, I anticipate that demand will be there for all vendors.

Here is the bottom line: Three months ago I was wondering if all my DMN efforts were just a waste of time. Now I am totally excited. And you should be, as well.
DMN, in spite of everything, is today a success story in the process of unfolding. The promise, requiring full implementation, is real. It’s happening now. We’ll see real Level3 products this year – at least 3, I believe – that deliver on the promise: What you see is what you execute, in a tool-independent language. Vendors who thought they could get away with partial implementation may now be rethinking their strategy.
Many of the heroes of this story are here at this event. You should thank them: Gary Hallmark, Alan Fish, Jan Vanthienen. Some who were there at the beginning, went away, and now have come back: Larry Goldberg, Jacob Feldman, Mark Proctor. The momentum is building.
We’re still trying to make it better. If you want to participate, join the Revision Task Force in OMG. Contact Gary for that. Or Participate in the TCK – contact Keith Swenson for that. If you want to learn how to use DMN, here are links to my book and training – we have a live/online class next week!
Welcome to the new world of decision management.
The post DMN as a Decision Modeling Language appeared first on Method and Style.