DMN 1.2: Haters Gonna Hate
Blog: Method & Style (Bruce Silver)
Here we go again. We saw this eight years ago with BPMN 2.0. A revision of the standard allows tools to work 99% the same as in the previous version, but adds some new features around the edges. This causes the proprietary tool vendors to howl in unison: Not business friendly! Why can’t it work like the earlier version? (Of course their tools are not compliant with the earlier version, either.) Basically they are asking, Why can’t this standard work just like my proprietary tool?
So now on the DMN LinkedIn group we have a similar wailing post: Keep DMN Simple. I’m not a tool vendor, and on reading these self-serving hit pieces I try to bite my tongue, but I gotta call BS on this one.
The arguments in this post mostly center on decision tables. Decision tables are a staple of all decision languages, but every language – tool-specific or standards-based – imposes its own formats and constraints. Here DMN 1.0 made an interesting choice: The condition cells, in DMN called input entries, were limited to so-called unary tests, essentially just literal values or simple variable names that would be compared to the input expression, or input column heading. No expressions would be allowed (except for not()), not even simple arithmetic. That is quite restrictive, but it has one major benefit: It allows the table to checked for completeness, consistency, subsumption, and normalization. DMN felt free to impose this constraint on decision tables because it did not insist that every value expression is a decision table! It could instead be a literal expression, an invocation, or a context, among others.
Since the inputs to the decision defined by a decision table are just input data and the outputs of supporting decisions, this constraint on input entries suggests you need to insert supporting decisions whose sole purpose is to create decision table inputs that work with such simple condition cells. And of course, you are free to do exactly that! But in real decision logic, your DRD is then going to be littered with lots of these special supporting decisions, and so – if you like – you can instead make them context entries followed by the decision table, all within a single decision. And the author illustrates this, with some mock horror, with an example from Jan Purchase’s fine piece on DMN 1.2, shown below:
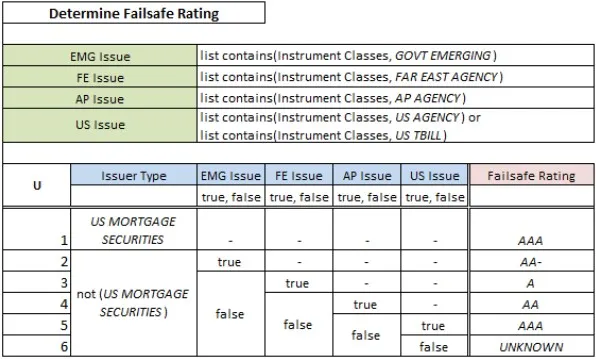
Here the table column EMG issue has the value true if the list Instrument Classes contains an item “GOVT EMERGING”, and similarly for the next 3 input columns. Now you could make these 4 inputs separate supporting decisions – perfectly allowed – or you could make your DRD a little more compact using the context entries as shown here. It’s your choice as a modeler. But context entries are just a DMN thing, so tool vendors that don’t offer them shout “Not business-friendly!” The logic above seems business-friendly enough to me.
Now context entries have been in DMN since v1.0, but some tool vendors continued to ask for the ability to go beyond the strictures of unary tests. If they could put arbitrary expressions in the condition cells, they would not need context entries or the extra supporting decisions. Yes, that eliminates the ability to check completeness, etc., but it might allow them to support DMN without doing too much extra work. So, at the request of these vendors, DMN 1.2 added such a thing, called generalized unary tests. (It’s just something in addition; it does not replace the normal way.) Here is the same logic, without the need for context entries, using generalized unary tests:
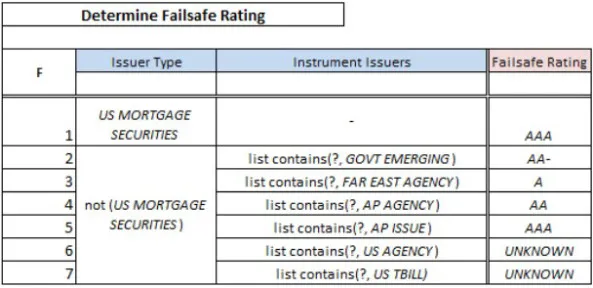
In the generalized unary test syntax, the input entry can be any FEEL expression, where the ? character stands for the input expression (column heading). Now no one on the DMN 1.2 committee was especially thrilled with the syntax, but it has one overriding virtue: It allows standard FEEL – the same language used everywhere else in DMN – to be used in input entries as well. It does not, for example, introduce special operators that only work in the context of decision table condition cells. You cannot say the same for the “simpler” table preferred by the hit piece author, shown below:

You might say, this table syntax looks simpler. But note now the condition cells have two parts, an operator and an operand. Now let’s give the benefit of the doubt and say that the operand is not restricted to literal values as you see here, but could contain variables, functions, and other operators. In order to compare the language on which such a table is based with DMN, you would need to look at the entire grammar, including these special input entry operators and other operators. DMN has no special operators that just work in decision tables. FEEL is FEEL. It is the same language whether used in a literal expression, decision table, context, or other boxed expression type. It has a published grammar, which can be compiled using a variety of tools, as exemplified by the various vendors listed on the DMN TCK site who have done exactly that.
And, I should add, it’s the work of a committee made up of competing vendors using an open process, so it’s a negotiation, a compromise. If your pet proposal is rejected, well that’s the nature of standards. But in the end it means DMN works the same in any tool, and you can interchange models between tools. Honestly, features like the generalized unary tests that are the focus of the author’s critique were added specifically to satisfy the demands of vendors who require all value expressions to be decision tables… not, as the author would have it, things “proudly promoted for their elegance.”
There are other things in the article that are just patently false, such as the statement that S-FEEL and Compliance Level 2 have been eliminated from DMN 1.2. I am looking at the final draft and they’re both still there. Sounds like the author didn’t actually look at the spec before writing his hit piece. He also rejects the statement by “DMN Committee members” that
For the foreseeable future, [executable decision models] will be created by developers and [maybe] more technical business users.
I doubt that is the official view of anyone on the DMN Committee. Actually it sounds like something in the Preface of DMN Cookbook, authored by Edson Tirelli and myself, describing our intended audience:
Certainly, not every user capable of using DRDs to create decision requirements has the skill or inclination to create executable decision models. For the foreseeable future, those will be created by developers and more technical business users, sometimes called “citizen developers”. This book is intended for them.
DMN’s strength is it can be used at many levels of technical skill. You are not compelled to use features added on for some special purpose. The old “standard” ways did not go away. You can still use them. Users can simply create DRDs and hand them off to developers for implementation. If the logic is simple enough, business users can create executable models using nothing but Level 2 decision tables. Most real-world logic is going to require contexts, decision services, functions and filter expressions, but DMN provides a unified language for all of it. Sure any number of non-DMN tools, including those based on Excel with Java jammed in here and there, can also do it. No one is saying otherwise.
This is the thing that proprietary tool vendors just don’t get. Standards have their strengths and weaknesses. But their main strength is they break the user’s dependence on a particular tool. And that’s what the haters hate the most.
The post DMN 1.2: Haters Gonna Hate appeared first on Method and Style.