

Disco 1.7.0

It is our pleasure to announce the immediate release of Disco 1.7.0!
In many ways, this release is the biggest update to Disco since its initial release two years ago. The new features we have introduced in 1.7.0 will enable process analysts to not only work much more efficiently and fluently, but we think that these extensions will also open up many new opportunities and possibilities for applying process mining in your organization.
Disco will automatically download and install this update the next time you run it, if you are connected to the internet. You can of course also download and install the updated installer packages manually from fluxicon.com/disco.
If you want to make yourself familiar with the changes and new additions in Disco 1.7.0, we have made a video that should give you a nice overview. Please keep reading if you want the full details of what we think is a great summer update to the most popular process mining tool in the world.
Continuous use and bigger data
When we first released Disco in 2012, process mining was still very much something new for most companies we talked to. Consequently, most of its practical applications were proofs-of-concept or pilots, and had a decidedly “project” character to them. A data set was extracted from the company’s IT systems, and a small team would spend some weeks or months analyzing it.
In the years since, the tide has clearly started to turn for process mining. There are now more than enough practical experiences, in a wide range of industries and use cases, that there is less of a need to “start small” for many companies. Furthermore, many of the early adopters are now way ahead in their process mining practice, and have integrated it deeply all across their daily operations. Consequently, the share of our customers that have a large installed base of Disco, and who use it every day in a repeated fashion, is about to become the majority.
At the same time, there has been an unrelenting trend for data sets becoming bigger and bigger. On the one hand, this growth of data volume reflects the increased importance that many organizations place on collecting and analyzing their operations. On the other hand, it is a testament to the success that process mining has experienced. Many companies have extended their use of process mining onto more and more segments of their operations, while more and more of the largest enterprises have embraced this technology as well. When you analyze a larger (part of your) business, you consequently have more data to analyze.
From the outset, we have designed Disco to be the perfect tool for all process mining use cases. It is easy to get started with for beginners, and at the same time the most flexible and powerful tool for experts. This flexibility has always made Disco great for exploratory and one-off projects, and thus very popular with consultants and process excellence groups. At the same time, our relentless focus on performance, and a smart design that rewards continued use, make sure that Disco is also the best companion for continued use on large data sets.
With Disco 1.7.0, we have focused on making Disco an even better tool for continuous use within organizations, and for ever-growing data sets. This release adds a number of features and improvements that not only make using Disco more enjoyable and productive in continuous use settings, but also open up completely new application areas in your organization.
At the same time, Disco 1.7.0 stays true to its nature of being the best tool for every process mining job. All the changes and additions that we have made will make Disco a better solution also for project use and other use cases, and we think that it significantly improves the Disco experience across the board.
There are three major “tentpole” features in Disco 1.7.0, which we will introduce right below: Overdrive, Recipes, and Airlift. Of course, this release is also chock-full of many more features, improvements, and bug fixes, which you can read about further below.
Overdrive

From the very start, we have designed and engineered Disco from the foundation to be as fast as possible, and to be able to deal also with very large data sets. Over the years, we have been able to steadily improve this performance, keeping Disco well ahead of other process mining solutions in terms of speed and scalability.
There are two major use cases where performance really matters in Disco: Loading a data set into Disco, e.g. from a CSV file, and filtering a data set, either to clean up data or to drill down for analysis. First, let us look more closely at what happens in Disco when you load a data set.

In the first phase, the actual data is loaded and parsed from your file, organized in a way that enables process mining (e.g., sorted by timestamp and into cases), and stored within Disco for further analysis. This is the part that will typically consume the most time, and there is not much we can do about this, since it depends on the speed of your hard drive, and also on the characteristics of your data set.
Then, Disco extracts the process metrics from your data set. The metrics are a highly optimized data structure that stores process information about your data in a compressed form that enables fast process mining (e.g., how often activity “A” is followed by activity “B”).
Finally, the Disco miner analyzes the process metrics and builds a graphical process map, based on your detail settings for activities and paths (i.e., the sliders). This final phase is very fast, and happens almost instantly. When you move the sliders in the map view of Disco, this is what happens in the background.
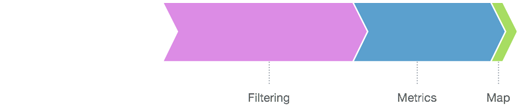
When you filter a data set in Disco, the data is first processed by the filters you configured, and the result is then organized and stored in Disco (the “Filtering” phase above). Again, we are basically moving a whole lot of data around here, so there are limits to how fast this phase can be performed.
After filtering, we have to create updated process metrics, since these are based on the now-changed event data, and of course we finally have to create an updated process map.
From the above, you can see that for both our performance-critical tasks in Disco we have three phases. The first phase of both loading and filtering has been thoroughly optimized over the years, and there are inherent physical boundaries to how fast this can get. The last phase has always been close to instant, so we can’t move the needle here as well.
This leaves the creation of the process metrics, and we are proud to announce that with Disco 1.7.0, we have achieved a real break-through in performance here.
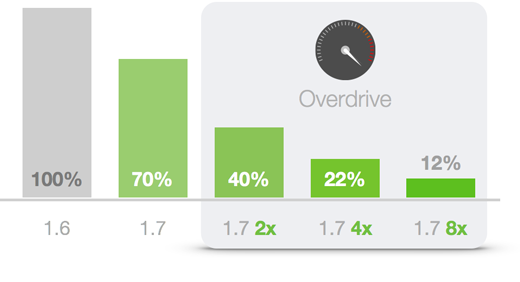
Both our algorithms and data structures have been thoroughly redesigned and optimized from the ground up for maximum performance. This means that in Disco 1.7.0, generating the metrics will take 70% of the time when compared with Disco 1.6 as a base line.
Today, most computers in use have multiple CPU cores, and their number is growing with every generation. Most software, though, will only use one or at most two cores at a time. The reason for that is that developing for multiple cores adds a high degree of complexity to any software, and is often close to impossible or simply not worth it.
In Disco 1.7.0, the metrics generation phase will now transparently scale across all available CPU cores, using your system capacity to the max. And, as you can see from the chart above, the performance gain you get from each extra core is linear, meaning every time you double your number of cores, your processing time shrinks in half. For example, when you have 8 cores, you are now down to 12% of the processing time before Disco 1.7.0, which can turn a coffee break into the blink of an eye.
Many other performance-critical parts of Disco have been making use of all your CPU cores for quite some time. Bringing the metrics generation phase into the fold has been a real technical challenge, and we are proud to have achieved this linear step up in performance. This is an improvement that all of you will benefit from. But for those of you who use Disco every day, with very large data sets, we hope and expect that it will be a real game changer!
Recipes

As a Disco user, you know that filtering is a cornerstone of process mining in Disco, and a major factor for its unmatched analysis power and flexibility. Filters allow you to clean up your data set and remove distracting and incorrect data. More importantly, they are a powerful mechanism for drilling down into subsets of your data, and for quickly and decidedly answering any analysis question you may have.
In Disco 1.7.0, we have made filtering faster and more powerful than ever before, for instance by improving the performance of every filter, and the responsiveness and functionality of the filter settings user interface. However, the biggest enhancement to filtering in 1.7.0 are Recipes.
Recipes are a feature in Disco to re-use and share filter settings. This means that you can now export your current filter settings to a Recipe file, and you can also load a Recipe file and apply its settings to another data set, even on another machine.
So far so good, and that’s pretty much the implementation for re-using filter settings that our customers have been asking us for. However, when we add a feature like that in Disco, we don’t stop with the obvious, trivial implementation. We think long and hard about the actual use cases, about when and why someone would re-use filter settings, and only after we have thoroughly understood it all, we carefully design a complete feature and add it to Disco.
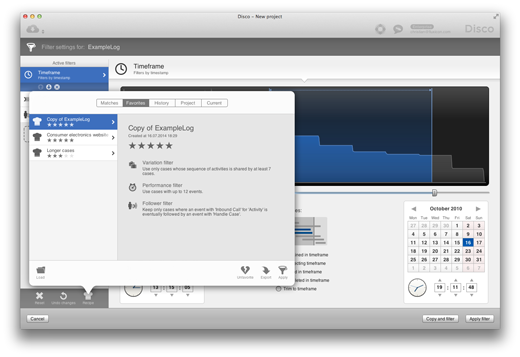
Above, you can see the Recipes popup, which you can trigger from a newly introduced button in the filter settings of Disco. On the lower left, you can open a Recipe file to apply it to your current data set. When you select the “Current” tab on the top right, you can see a summary of your current filter settings, and you can export it to a Recipe file for sharing it.
Next to the “Current” tab, you can see all filter settings in your current project in the “Project” tab. This allows you to quickly transfer filter settings, e.g. from the data set for last month to the updated data you just loaded into Disco.
Disco also remembers all your recently-applied filter settings, which are shown in the “History” tab. This feature acts much like a browser history, and allows you to quickly go back to something you did a few minutes ago and want to restore again.
Especially if you work in a continuous setting, and you have similar analysis questions for similar data sets over and over again, you will probably feel right at home in the “Favorites” tab. For every recipe, you can click the “Favorite” button on the lower right, which will remember this setting and add it to the “Favorites” section. Think of this as your personal “best-of” library of filter settings to clean up your data, or to drill down into specific subsets for further analysis in a snap. You can easily rename Recipes in your Favorites by clicking on their name on top.
Every recipe is shown with a short, human-readable summary of its filter settings. This allows you to quickly establish whether this is what you had been looking for, and to estimate its impact on your data. Moreover, below the recipe name and in the recipe list on the left, we have included a five-star-rating. This rating estimates how well each Recipe fits your current data set. It makes no sense to filter for an attribute that is not even present in your current data, or a timeframe that is long gone. The smart Recipe rating feature captures these problems, and allows you to focus on what’s relevant.
On the very left tab, you can see the “Matches”, which will only display those recipes from all over your Favorites, History, and Project that best match your current data set. This allows you to get a quick start with Recipes, and quickly find what is most relevant for your current context.
We think that Recipes will make working with Filters much more efficient and effortless in Disco. Especially if you are using Disco in a continuous and repetitive use case, Recipes will make your life much easier, boost your productivity, and allow you to focus on what’s really relevant.
Recipes also make it possible to quickly bring a colleague up to speed, by sharing your favorite filter settings with her for a head start. And finally, Recipes now enable consultants to share the “Recipes” of their work with their clients, empowering them to repeat and continue their analysis on updated data, right where the consultant left off.
Airlift

One of the most remarkable benefits of process mining is that it makes analyzing business processes so easy and fluid that even more non-technical business users can start improving their processes right away. This sets process mining apart from more technically involved analysis methods, both from the classical statistics and the big data space. However, since the actual analysis part is so approachable and efficient, it highlights even more the challenge of getting event log data to analyze, and also the hurdles associated with getting that data into your process mining tool in the correct format.
Disco can read your log data from files in a number of formats. While the XES and MXML standards are more popular in the academic space, most business users prefer importing from CSV files, which can be easily exported from almost all process support system and data base servers. Many people have complimented us on our very user-friendly CSV import user interface in Disco, which intelligently aids users in configuration, and makes sure that you don’t have to do unnecessary work here.
However, the fact remains that configuring your CSV data for import, that means mapping columns in your data to case ID, activity names, and timestamps, is arguably the most complex task for most Disco users. Even worse, every user has to master this step before he can even start with the much more enjoyable and productive phase of actually analyzing their process.

With Disco 1.7.0, we are introducing Airlift, which addresses this problem. Airlift is an interface which provides a direct and seamless integration between Disco and the system where your event log data is stored. When you request log data over Airlift, technical details like case IDs, activities, and timestamps are already configured on the server side, so that business users can directly dive into analysis tasks.
Another benefit of Airlift is that it directly connects any number of Disco users with a single, canonical data source. You no longer have to maintain a shared space where the regularly exported CSV dumps are stored. Every user has direct access to up-to-date data, which she can request right at the point in time where she needs them.
As an interface, Airlift is located at the perfect position between the business side and the IT side of process operations. The IT staff can concentrate on configuring and maintaining the data source, while business users can focus on analysis only, without concerning themselves with technical details. And when you need an updated data set, there is no longer the need to involve the IT staff with your request, since you can directly download your data over Airlift.
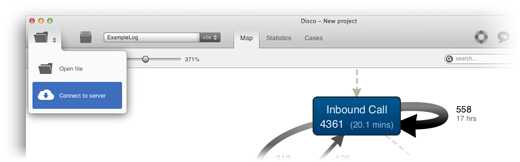
In Disco, you can access your Airlift server simply over the toolbar. The “Open file” button can now be switched to a “Connect to server” option, which brings up a login screen. As a Disco user, you need to provide the URL of your Airlift server, as well as your login and password details only once. After that, Disco will remember your settings and provide direct and fast access to your server every time, as simple as accessing the local file system.
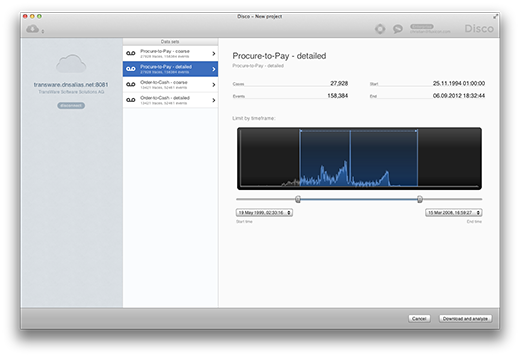
When you are connected to your Airlift server, Disco provides you with a view where you can browse all data sets available on your Airlift server. For every data set, you can see some meta-data, like the number of cases and events, and the timeframe covered by the data set. Before you download, you can also specify which timeframe of data you are interested in, and whether you are only interested in completed cases.
Once you download a data set, only the data that you have requested is transferred from your Airlift server. Combined with a transfer format that is optimized for speed and throughput, an import from Airlift is much faster than importing that data from CSV. The time required for downloading log data is basically only limited by the speed of your network connection, and by the performance of your Airlift server.
Airlift is the perfect solution when you want to apply process mining in a continuous use case, and when you have multiple business users analyzing the same data sets in your organization. It provides the following main benefits over a file-based input.
-
Scalability: Onboarding a new process mining user becomes as easy as setting them up with the Airlift URL, login, and password, and they can immediately start analyzing their processes. Also, you no longer need a meta-process for extracting and sharing CSV data, since all your data is now transparently served directly from the source system.
-
Performance: The Airlift API and protocol is designed for high speed from the ground up. An optimized file format and request API ensures that only the necessary data is transferred in a highly compressed manner.
-
Security: By default, all Airlift data is transferred over industry-standard encrypted SSL connections, keeping your data safe in transit. You no longer need to worry about securing a shared space where your sensitive data rests in CSV files.
-
Maintainability: Instead of managing a collection of SQL queries and scripts for export, plus manual tasks for sharing your data, all these tasks are now automated in your Airlift server. Once you have set up sharing your process data over Airlift, there is no more regular maintenance for your IT staff to perform.
Of course, Airlift support in Disco is only one part of the solution. You also need an Airlift server, capable of serving your data sets to Disco. Some of our customers already have an infrastructure of data warehouses and legacy systems, where their event log data is stored. If that is your situation, we can help you connecting your data source systems to your Disco clients with an Airlift server through our professional services.
Airlift Official Partners
Even more exciting, we are also introducing Airlift Official Partners. Theses are select vendors who have built the Airlift API right into their products. When you are using a system from an official partner, you get Airlift functionality out of the box. Just connect Disco to an official partner system, and you can start analyzing the processes supported or recorded by these systems right away, without any configuration or setup work.
We are especially excited about our three launching partners.
 Alfresco Activiti provides a highly-scalable, Java based, workflow and Business Process Management (BPM) platform targeted at business people, developers and administrators. Alfresco provides an out-of-the-box Airlift integration to Disco for any process that is deployed with their Activiti Enterprise BPM system. Since the Activiti system makes it easy to modify and update business processes, you can directly close the loop from running your process, analyzing it with Disco, and going back to implement the required changes in Activiti.
Alfresco Activiti provides a highly-scalable, Java based, workflow and Business Process Management (BPM) platform targeted at business people, developers and administrators. Alfresco provides an out-of-the-box Airlift integration to Disco for any process that is deployed with their Activiti Enterprise BPM system. Since the Activiti system makes it easy to modify and update business processes, you can directly close the loop from running your process, analyzing it with Disco, and going back to implement the required changes in Activiti.
 Profiling for SAP is a software and service solution from Transware, based on latest SAP technology standards like SAP Solution Manager. Transware enables a direct integration of your SAP system for process mining with Disco via Airlift. Transware’s Airlift-enabled solution is especially interesting if you want to continuously analyze your SAP processes with access to live data, while also limiting the impact on your SAP system’s setup and performance.
Profiling for SAP is a software and service solution from Transware, based on latest SAP technology standards like SAP Solution Manager. Transware enables a direct integration of your SAP system for process mining with Disco via Airlift. Transware’s Airlift-enabled solution is especially interesting if you want to continuously analyze your SAP processes with access to live data, while also limiting the impact on your SAP system’s setup and performance.
 UXsuite are specialized in data collection and analysis for measuring, controlling, and improving the customer experience of your users. Their SaaS service can collect data both from embedded systems in the field, and from websites and web apps that your customers interact with. Via UXsuite’s built-in Airlift integration, you can now analyze your customer journeys directly with process mining in Disco, with minimal setup and without installing any software.
UXsuite are specialized in data collection and analysis for measuring, controlling, and improving the customer experience of your users. Their SaaS service can collect data both from embedded systems in the field, and from websites and web apps that your customers interact with. Via UXsuite’s built-in Airlift integration, you can now analyze your customer journeys directly with process mining in Disco, with minimal setup and without installing any software.
We are really excited about our three launching partners, because we think that they provide exceptionally strong solutions in areas that are particularly relevant for process mining. For those of you that are using either of their solutions, process mining with Disco just got a whole lot easier and more powerful!
We are going to publish more in-depth articles about these particular Airlift integrations, and about Airlift in general, in the following weeks on this blog, so stay tuned! You can also get in touch if you want more information about these solutions right away.
One of our goals here at Fluxicon is to make process mining as easy, powerful, and accessible as possible for everyone, and we are very happy about our great set of launching partners. Going forward, there are already a number of further official partners hard at work on finishing their Airlift API implementations as we speak. If you have a product that you would like to offer Airlift integration for your customers, or if you would like the vendor of your process-supporting system to support Airlift, please get in touch with us at anne@fluxicon.com, and we will help you get the ball rolling!
Secondary Metrics
In Disco’s map view, you can project a number of frequency- and performance-related process perspectives onto the process map, which will both be visualized in terms of the color and shading of activities and paths, and also explicitly given in their respective text labels.
When we designed Disco, we have chosen for this view to show one metric at a time, for a number of reasons. For one, this makes the interaction with Disco much easier and more fluent, since when we only show one thing, we can show a larger part of the process map at the same time. This is one main reason why Disco is so successful in displaying very large and complex behavior with its compact map layout.
Secondly, picking a single process metrics for display provides instant context, which can then become subconscious. For every label you read on the map, you don’t have to think every time “What does that number say, again?”. You pick it once, and then you know it and move on to analysis. Focusing on a single metrics for map visualization thus provides also mental focus and improved productivity, which is why we have been very happy with this choice.
However, there are also some situations where you would really like to see two metrics on the map, at the same time. For example, the “Total Duration” performance perspective is great for visually highlighting the bottlenecks with the greatest impact on your process performance. When you want to learn more about these bottlenecks, though, you need to switch perspectives.
You will want to know how frequent that bottleneck occurs (i.e., its total or case frequency), to see whether you are dealing with an outlier. At the same time, you also want to know the specific extent of the delay (i.e., median, mean, or maximum duration), to properly estimate your improvement potential. In situations like this, showing two perspectives at the same time would actually improve your productivity, outweighing the detrimental effects introduced thusly.
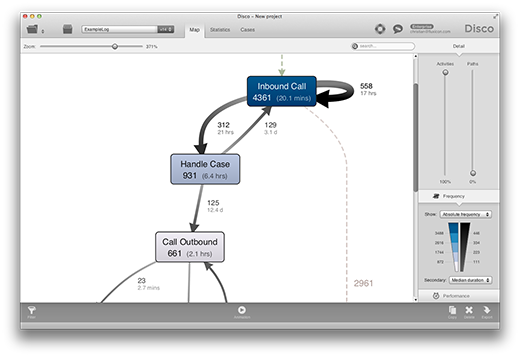
In Disco 1.7.0, you now have the option to add a secondary metrics to your process map visualization, by clicking on the “Add secondary” button below the perspective legend on the bottom right. The primary metrics will still take center stage, and will determine the visualization (colors, shades) of your map to ensure focus. But now, the labels of both activities and paths will now also feature a label detailing the secondary perspective.
Beside the specific situations where this is beneficial, like the one outlined above, this feature is also useful if you want to export more information-rich process maps (e.g. as a PDF) to share with other stakeholders of your analysis. We believe that, for the overwhelming majority of use cases, you should stick to a single perspective at a time. However, for those situations when one metrics is not enough, you now have a choice.
Filter Summary
While you are analyzing your data in the Map, Statistics, or Cases view, you often want a quick reminder of what you are looking at exactly. Disco has always had two small pie-chart indicators for displaying the filtered percentage of cases and events, but often you also want to get a quick overview of the filter settings you have applied to this data set.
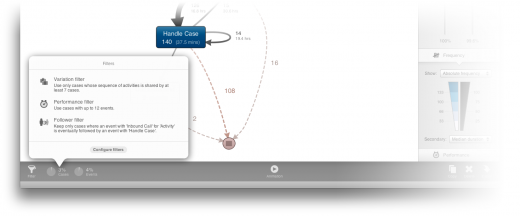
In Disco 1.7.0, you can now click on these pie-chart indicators to open a condensed filter summary. This summary is human-readable and to the point, like the filter settings display in the Recipes popup, allowing you to get a quick overview without entering the filter dialog every time.
Export
We have designed Disco to be the perfect tool for process mining, and as such it includes all functionality that you need to analyze your business processes in depth. Focusing on process mining, however, also means that there are a lot of things that Disco does not do, because there are other tools better for these jobs.
To make sure that you can move seamlessly between Disco and other data analysis tools, like MS Excel, Disco allows you to export almost any result for further analysis in other software. In Disco 1.7.0, we introduce two additional export options that can help you to perform even deeper analysis in third-party tools like MS Excel.
When you export a process map in Disco, you typically want to export a graphical representation to a PDF document, or to a PNG or JPG image. With Disco 1.5.0, we have introduced an XML export for process maps, including all process metrics.
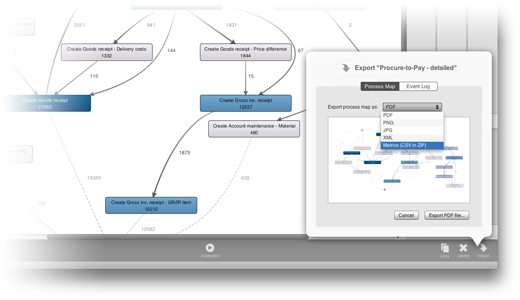
Starting from Disco 1.7.0, you can now also export the full set of process metrics to a set of CSV files packaged in a ZIP archive. This is the raw data that the Disco miner uses to construct the process map from, and is independent from the activity and paths slider settings. While this data is very low-level, it is the perfect starting point when you want to analyze your process metrics very in-depth, in a tool like Excel, Minitab, or SPSS.
As you may know, you can also export the full list of variants from Disco to CSV by right-clicking on the variants table in the Statistics view. This CSV file includes all meta-information about the variants, like the number of cases they cover, their number of events, and mean and median duration of cases. Starting from Disco 1.7.0, the exported CSV file now also includes the activity steps for each variant. This makes it easier for you to map each variant’s meta-data to their exact sequence of steps for further analysis or documentation.
Improved bug reports from within Disco
We could not plan the roadmap from Disco without the great amount of high-quality feedback we get from all our customers. For us, this feedback is essential for understanding how people are applying process mining, what problems they are trying to solve, and what challenges and problems they encounter with Disco today. Your feedback ensures that our roadmap tackles the relevant problems and challenges.
It is also challenging to develop process mining software bug-free out of the gate. Our customers use Disco for very different use cases, and the data sets they are analyzing differ widely in their characteristics. In order to make sure that bugs get fixed as quickly as possible in Disco, we have added in-app feedback from the beginning. By clicking on the speech-bubble icon in the toolbar, you can directly send us your feedback about bugs and problems you encounter, and you can also let us know your suggestions and ideas for improvement.
With Disco 1.7.0, we have improved our feedback system even more, to fix bugs and problems even faster, and to make it easier for you to help us make Disco better.
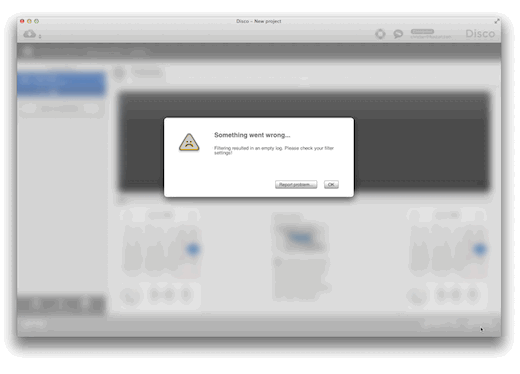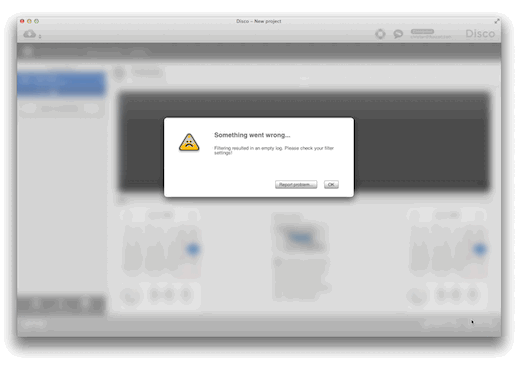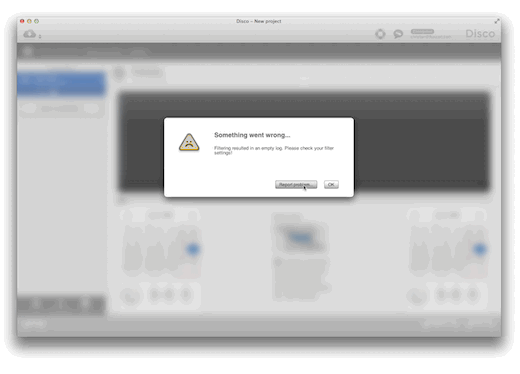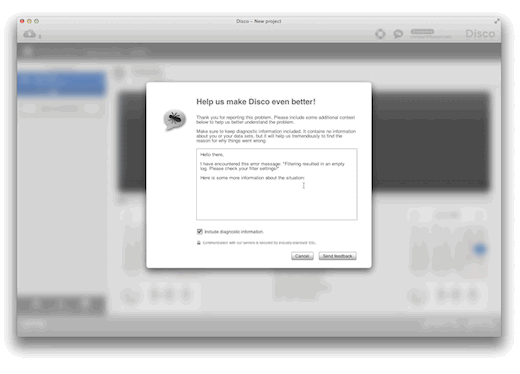
When something goes wrong in Disco, you will see an error or warning dialog. With Disco 1.7.0, we have added a button to each error dialog that lets you directly provide feedback on this problem, right when it occurs. After you have sent your feedback, Disco will bring you right where you left off, so your flow of work will not be interrupted.
For every feedback option, from an error dialog or from the toolbar popup, we have also added the option to transmit diagnostic information to us. This is a set of information that allows us to see the precise context and state of Disco at the time of feedback. Especially when you report a bug or problem, diagnostic information allows us to get a better idea of what may have caused this problem, and enables us to fix it faster and in a better way.
Please note that this diagnostic information contains no personal data, and it also contains no information about your data sets. Its purpose is strictly to let us better understand the internal state of Disco, and to pinpoint the conditions that may have led to the problem you experienced. This information will help us to fix bugs and problems better and faster, with less of a need for you to provide more information or run tests for us. If you prefer not to send diagnostic information, you can always disable this option while still sending feedback.
Your continued feedback is a major reason why Disco is the best, and the most stable, process mining solution out there. By making it easier to send feedback right from error dialogs, and by including diagnostics information, providing feedback is now both easier and even more productive than before. Please keep sending us your feedback, and help us make Disco even better!
Other changes
The 1.7.0 update also includes a number of other features and bug fixes, which improve the functionality, reliability, and performance of Disco. Please find a list of the most important further changes below.
-
Significantly improved filter performance and responsiveness of filter settings interactions.
-
Introduced option to extend the Performance Filter range down to zero for later-stage filtering.
-
Improved performance of Variation Filter.
-
Improved full-text search performance and behavior in Cases view.
-
Improved performance of copying data sets.
-
Improved performance of log data handling, resulting in faster import and filtering speeds.
-
Improved resilience of CSV import when importing malformed files.
-
This update addresses several issues that could result in inconsistent UI behavior for some users.
-
Improved shutdown time and responsiveness.
Leave a Comment
You must be logged in to post a comment.






