

Dealing With Parallelism in Your Process Maps
Last week, we have seen how you can differentiate between active time and passive time if you have a start and end timestamp in your data set.
If you do have a start and end timestamp in your data, it can also happen that some of the activities are running at the same time. Disco detects parallelism if two activities overlap in time (see illustration below).
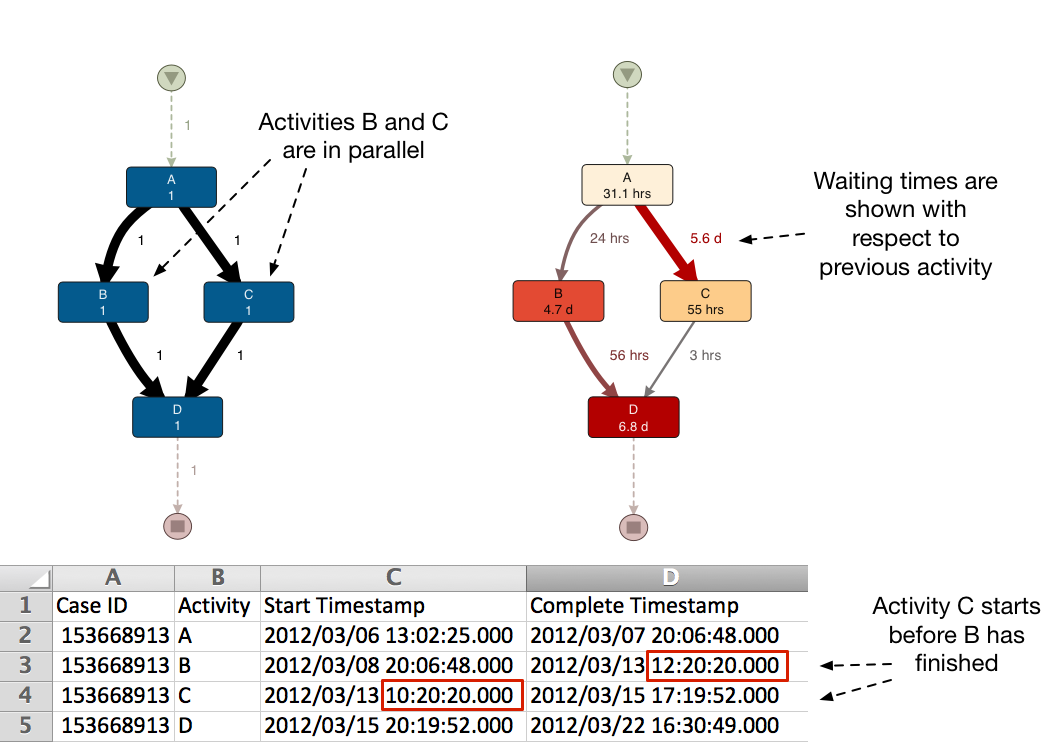
In the example above you can see that activity C starts two hours before activity B has ended. Therefore, both activities are shown in parallel in the process map (see left at the top). You can see that for processes that have parallel activities the frequencies do not add up to 100% anymore. For example, after activity A both the path to activity B and C are followed and their frequencies (1 + 1) do not add up to frequency of the previous activity as they would if there was a choice between them.1
Furthermore, the waiting times in the process are now calculated with respect to the previous activities — not the ones that are running in parallel (see top right).
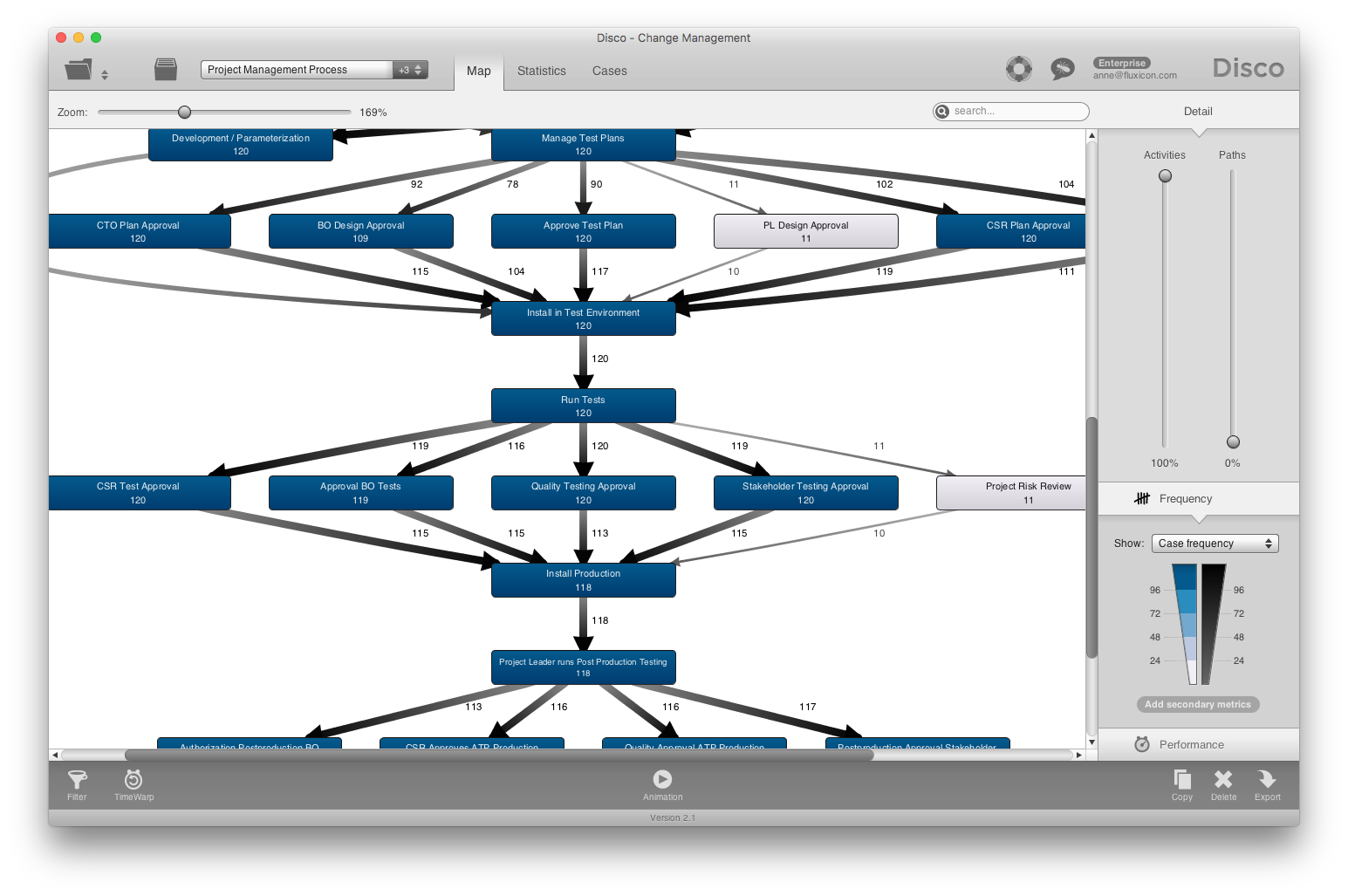
If you have a parallel process, then this is typically what you want. For example, the screenshot below shows a project management process (click on the image to see a larger version of it).
You can see that there are several milestones in the process, such as ‘Install in test environment’. To reach a milestone in this process, several activities need to be completed beforehand but they can be completed in parallel. In the example below we can see that not all the parallel activities are always performed. For example, a ‘Project risk review’ has only be done for 11 out of the 120 cases.
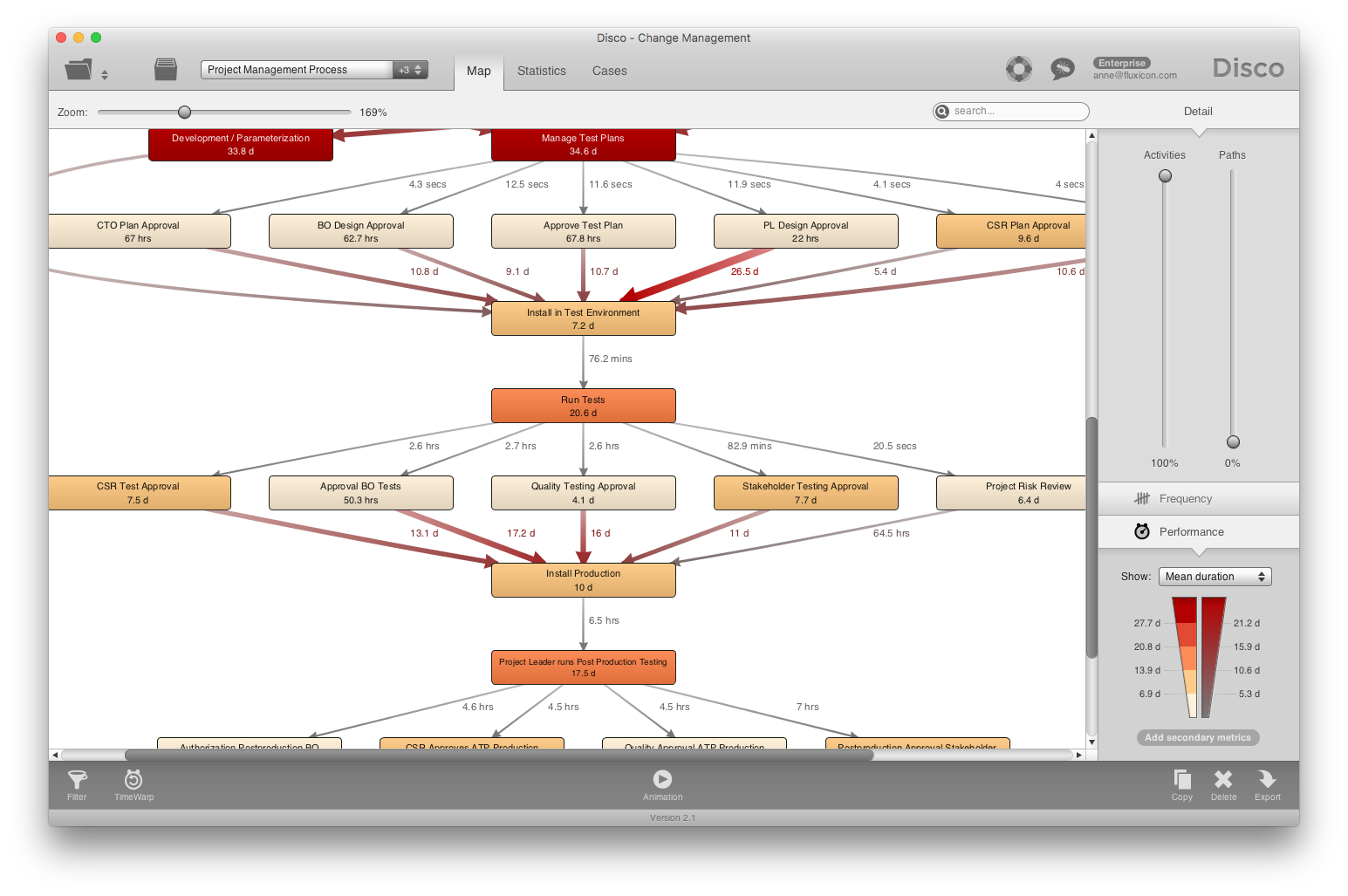
When you switch to the performance view for this process, you can analyze the times of the different parallel paths to perform a Critical Path Analysis. A critical path analysis is only applicable for parallel processes and allows to see which of the parallel branches, if delayed, would delay the next milestone even more.
Challenges with Parallel Processes
Im most situations, if you have parallelism in your process, this is exactly what you want to see. However, there can be some problems related to parallelism as well. For example:
- Sometimes, activities overlap due to the way that the data is recorded. For example, the start of the next activity might be 1 second earlier than the completion time of the previous one just because of the buffering of the logging mechanism in the IT system.In this situation you get process maps that accidentally show parallel activities while the activities are not actually performed in parallel in reality. It’s a data quality problem.
- Even if the timestamps are correct and some activities overlap in time, it can be much more complicated to analyze a parallel process and you might find it difficult to fully understand the process map.
Fortunately, if you find yourself in one of these situations, there is a simple way to get around the parallelism problem: You can import your data set again and configure only one of your timestamps as a ‘Timestamp’ column in Disco (you can keep the other one as an attribute). If you have only one timestamp configured, Disco always shows you a sequential view of your process. Even if two activities have the same timestamp they are shown in sequence with ‘instant’ time between them.
Looking at a sequential view of your process is a great way to investigate the process map and the process variants without being distracted by parallel process parts. You can then always go back and import the data with two timestamps again if you want to analyze the activity durations and the parallel flows.
- If you run the animation for this process, you will also see that one token splits into two tokens for the parallel part of the process and then they merge again.
Leave a Comment
You must be logged in to post a comment.






