
Datatypes with Constraints
Blog: Method & Style (Bruce Silver)
As a followup to my post from last month, there is another aspect of datatypes I’ve been thinking about. When a simple type is subject to constraints, such as a numeric range or a list of enumerated values, I have been teaching students to create an item definition that expresses those constraints. For example, if a numeric value is always positive, we might assign it the datatype tPositiveNumber, a Number subject to the constraint >0. But I’m only now beginning to understand what those constraints really mean in practice.
You would likely expect that the effect of datatype assignment in the Modeler is to “do something” at runtime when a variable’s value is inconsistent with its assigned type. But what “do something” means is platform-dependent. On the Trisotech platform, the runtime includes a type-checking option that will return an error when a value is out of bounds, but except for decision tables this option is currently turned off for performance reasons. That means that on this platform the effect of constraints such as a numeric range or list of enumerated value affects only decision tables. Otherwise, constraint violations are effectively ignored by the runtime engine. Here is an example:

Here Risk Category is classifying Credit Score into categories. The type tCreditScore defines a numeric range, 300 to 850 inclusive. What happens when you submit a Credit Score value of 200? In this case, it returns an error; the output value is null.
But here is the same logic expressed as an if-then-else literal expression (in this case using the Conditional boxed expression):
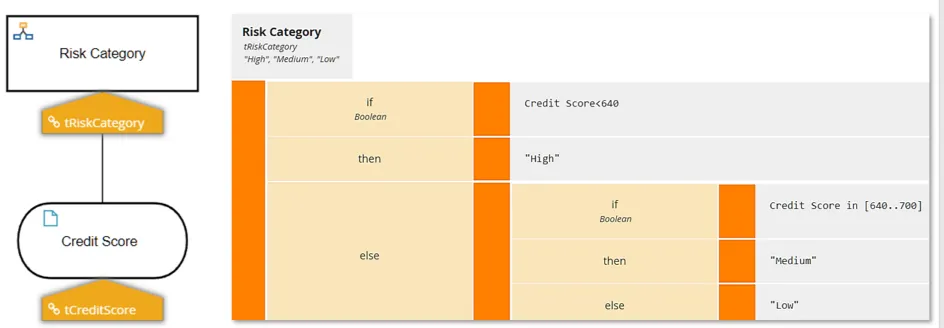
Now submitting a Credit Score of 200 returns High, not an error. The type violation is ignored.
So let’s return to the original question. If you have some variable that, say, is always a positive number, is it better to define it as an item definition with that constraint, or just use the base type Number? Let’s consider the Pros and Cons.
On the Pro side:
- A numeric range constraint on decision table inputs aids in assuring table completeness, meaning there are no gaps in the rules. Otherwise, the table would have to consider all numbers from negative infinity to positive infinity. In the decision table above that’s no problem, but in real-world decision tables it can make the logic unnecessarily complicated.
- In addition to the completeness benefit, an enumerated list constraint on decision table inputs makes data entry in model testing easier, as it allows the user to select from a dropdown list.
- An enumerated list constraint on a table output is absolutely necessary to take advantage of Priority hit policy, something used all the time.
On the Con side, it comes down to what you want to happen when a model input is out of bounds. You might say, this should never happen, it means something is seriously wrong, and you want execution to halt with a runtime error. Currently that would happen only with decision tables. With other boxed expressions, unless the value causes some error in a FEEL function – say taking the square root of a negative number – the type violation is not flagged.
On the other hand, you might say, it’s one thing for me to test the model with valid values, but out in the wild, clients can pass anything at all to the decision service – can and probably will! So in that case, do you want your service to return a runtime error or not? Normally, the last thing I want with a deployed service I have created is the possibility of a runtime error. And that’s because normally the error information returned to the user makes no sense to a non-programmer: “Null pointer exception.” “Index out of bounds.” What the heck do those things mean? Am I doing something wrong, or is the service broken? Hard to say.
But those are the kind of errors you get outside of decision tables, when type checking is not performed and the logic goes off the rails somewhere downstream. At least in the new Trisotech v11 runtime, the error message for a type constraint violation in decision tables is business user-friendly. In the example above, I get this:
Credit Score='200' does not match any of the valid values [300..850] for decision table 'Risk Category'.
And that’s great!
On the other hand, I am now in the habit of publishing my decision models not as plain DMN services but as part of a Low-Code Business Automation service containing Decision tasks that call the DMN. The advantage of that, when you need to consider the possibility of invalid data in the service call, is that you can validate the submitted data up front, as I have described in a previous post. This eliminates the possibility of running afoul of any downstream logic. It also allows you to create business-friendly error messages yourself… and in a screenflow provide a form that allows the user to correct the bad data and try again. In such Business Automation models, it is less important to create an item definition for something like a positive number. Probably better to leave it as base type Number and if the range is important to the logic, test it in a validation activity.
Remember, while the type checking now works well, strong type checking is currently turned on by default only for decision tables, so out-of-bounds inputs can still get in. Validating data inputs to Business Automation services, along with the output of any User tasks, catches errors whether destined for decision tables or not. It is a bit of extra work but well worth it in the end.