
Data Quality Problems In Process Mining And What To Do About Them — Part 2: Missing Data
![Ur Kungl. bibliotekets samlingar - [librisid: 8401659]](https://www.businessprocessincubator.com/wp-content/uploads/2016/02/fluxicon.comblogwp-contentuploads201602Kataloger-dafd7c8b636a94a8e61fd077dacacd6898d54964.jpg)
This is the second article in our series on data quality problems for process mining. You can read the first one on formatting errors here.
Even if your data imported without any errors, there may be still problems with the data. For example, one typical problem is missing data. Keep reading to learn more about some of the most common types of missing data in process mining.
Gaps in the timeline
Check the timeline in the ‘Events over time’ statistics to see whether there are any unusual gaps in the amount of data over your log timeframe.
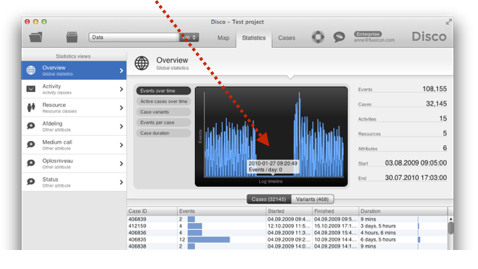
The picture above shows an example, where I had concatenated three separate files into one file before importing it in Disco. Clearly, something went wrong and apparently the whole data from the second file is missing.
How to fix:
If you made a mistake in the data pre-processing step, you can go back and make sure you include all the data there.
If you have received the data from someone else, you need to go back to that person and ask them to fix it.
If you have no way of obtaining new data, it is best to focus on an uninterrupted part of the data set (in the example above, that would be just the first or just the third part of the data). You can do that using the Timeframe filter in Disco.
Unexpected amount of data
You should have an idea about (roughly)…
Leave a Comment
You must be logged in to post a comment.






