
Data Quality Problems In Process Mining And What To Do About Them — Part 2: Missing Data
![Ur Kungl. bibliotekets samlingar - [librisid: 8401659]](https://fluxicon.com/blog/assets/2016/02/Kataloger.jpg)
This is the second article in our series on data quality problems for process mining. You can read the first one on formatting errors here.
Even if your data imported without any errors, there may still be problems with the data. For example, one typical problem is missing data. Keep reading to learn more about some of the most common types of missing data in process mining.
Gaps in the timeline
Check the timeline in the Events over time statistics to see whether there are any unusual gaps in the amount of data over your log timeframe.
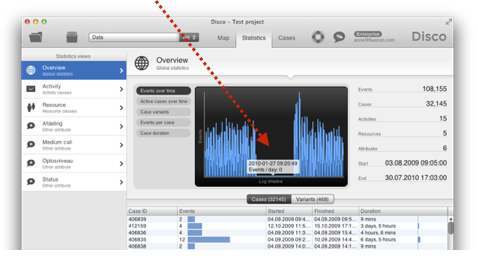
The picture above shows an example, where I had concatenated three separate files into one file before importing it in Disco. Clearly, something went wrong and apparently the whole data from the second file is missing.
How to fix:
If you made a mistake in the data pre-processing step, you can go back and make sure you include all the data there.
If you have received the data from someone else, you need to go back to that person and ask them to fix it.
If you have no way of obtaining new data, it is best to focus on an uninterrupted part of the data set (in the example above, that would be just the first or just the third part of the data). You can do that using the Timeframe filter in Disco.
Unexpected amount of data
You should have an idea about (roughly) how many rows or cases of data you are importing. Take a look at the overview statistics to see whether they match up.
For example, the picture below shows a screenshot of the overview statistics of the BPI Challenge 2013 data set. Can you see anything wrong with it?
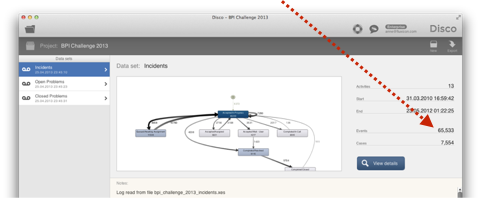
In fact, the total number of events is suspiciously close to the old Excel limit of 65,000 rows. And this is what happened: In one of the data preparation steps the data (which had several hundred thousand rows) was opened with an old Excel version and saved again.
Of course, this is a bit more subtle than an obvious gap in the timeline but missing data can have all kinds of reasons. For some systems or databases, a large data extract is aborted half-way without anyone noticing. Thats why it is a very good idea to have a sense of how much data you are expecting before you start with the import (ask the person that gives you the data how they structured their query).
How to fix:
If you miss data, you must find out whether you lost it in a data pre-processing step or in the data extraction phase.
If you have received the data from someone else, you need to go back to that person and ask them to fix it.
If you have no way of obtaining new data, try to get a good overview about which part of the data you got. Is it random? Was the data sorted and you got the first X rows? How does this impact your analysis possibilities? Some of the BPI Challenge submissions noticed that something was strange and analyzed the data pattern to better understand what was missing.
Unexpected distribution or empty attribute values
Similarly, you should have an idea of the kind of attributes that you expect in your data. Did you request the data for all call center service requests for the Netherlands, Germany, and France from one month, but the volumes suggest that the data you got is mostly from the Netherlands?
Another example to watch out for are empty values in your attributes. For example, the resource attribute statistics in the screenshot below show that 23% of the steps have no resource attached at all.
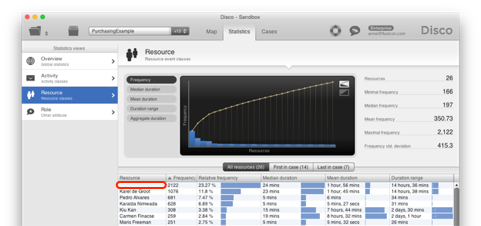
Empty values can also be normal. Talk to a process domain expert and someone who knows the information system to understand the meaning of the missing values in your situation.
How to fix:
If you have unexpected distributions, this could be a hint that you are missing data and you should go back to the pre-processing and extraction steps to find out why.
If you have empty attribute values, often these values are really missing and were never recorded in the first place. Make sure you understand how these missing (or unexpectedly distributed) attribute values impact your analysis possibilities. You may come to the conclusion that you cannot use a particular attribute for your analysis because of these quality problems.
It is not uncommon to discover data quality issues in your original data source during the process mining analysis, because nobody may have looked at that data the way you do. By showing the potential benefits of analyzing the data, you are creating an incentive for improving the data quality (and, therefore, increasing the analysis possibilities) over time.
Cases with unexpected number of steps
As a next check, you should look out for cases with a very high number of steps (see below). In the shown example, the callcenter data from the Disco demo logs was imported with the Customer ID configured as the case ID.
What you find is that while a total of 3231 customer cases had up to a maximum of 30 steps, there is this one case, (Customer 3) that had a total of 583 steps in total over a timeframe of two months. That cannot be quite right, can it?
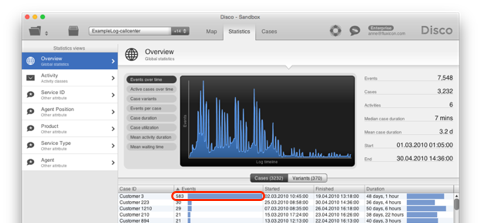
To investigate this further, you can right-click the case ID in the table and select the “Show case details” option (see below).
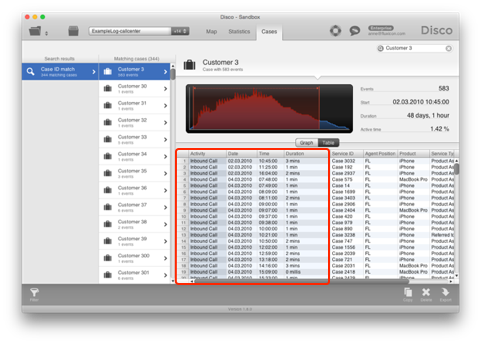
This will bring up the Cases view with that particular case shown (see below). It turns out that there were a lot of short inbound calls coming in rapid intervals. The consultation with a domain expert confirms that this is not a real customer, but some kind of default customer ID that is assigned by the Siebel CRM system if no customer was created or associated by the callcenter agent (for example, because it was not necessary, or because the customer hung up before the agent could capture their contact information).
Although in this data set there is technically a case ID associated, this is really an example of missing data. The real cases (the actual customers that called) are not captured. This will have an impact on your analysis. For example, analyzing the average number of steps per customer with this dummy customer in it will give you wrong results. You will encounter similar problems if the case ID field is empty for some of your events (they will all be grouped into one case with the ID empty).
How to fix:
You can simply remove the cases with such a large number of steps in Disco (see below). Make sure you keep track of how many events you are removing from the data and how representative your remaining dataset still is after doing that.
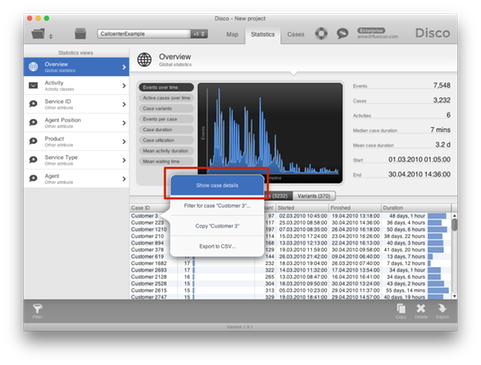
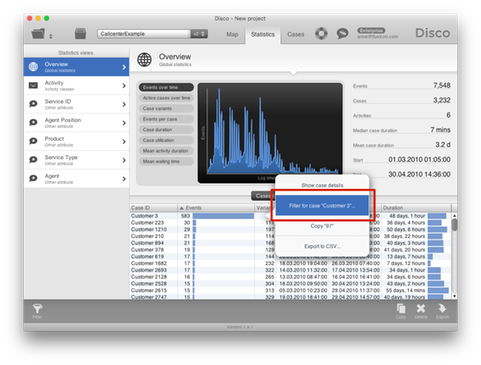
To remove the “Customer 3” case from the callcenter data above, you can right-click the case in the overview statistics and select the Filter for case ‘Customer 3’ option.1
In the filter, you can then invert the selection (see the little Yin Yang button in the upper right corner) to exclude Customer 3. To create a new reference point for your cleaned data, you can tick the Apply filters permanently option after pressing the ‘Copy and filter’ button:
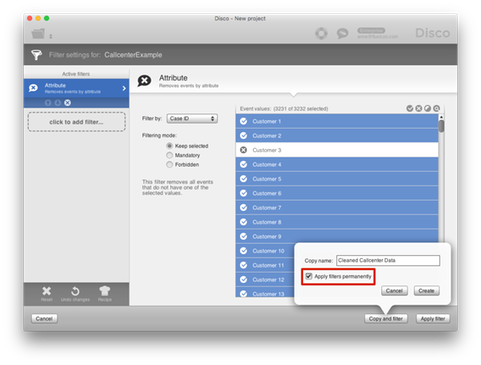
The result will be a new log with the very long case removed and the filter permanently applied (you have a clean start).
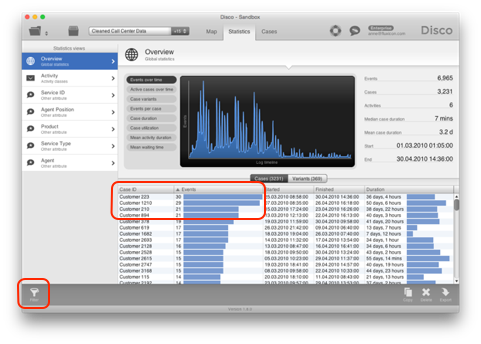
-
Alternatively, you could also use a Performance filter with the Number of events metric to remove cases that are overly long. ↩︎
Leave a Comment
You must be logged in to post a comment.






