

Data Quality Problems in Process Mining and What To Do About Them — Part 12: Missing History

This is the twelfth article in our series on data quality problems for process mining. You can find an overview of all articles in the series here.
When you get a data set and assess the suitability of the data for process mining, you start by looking for the three elements: Case ID, activity name and timestamp.
For example, when you look for the case ID then you start looking at the candidate columns to see whether there are multiple rows in the data set that refer to the same ID (see image below). If you don’t have multiple rows with the same case ID, then most likely the field that you thought could be your case ID is just an event ID and does not help you to correlate the steps that belong to the same process instance1.
When you continue looking for the other fields, it sometimes seems as if you have all the fields that you need at first. But then you find out that you actually miss the history information in these fields. Read on to learn about four situations, where this can happen.
Missing Activity History
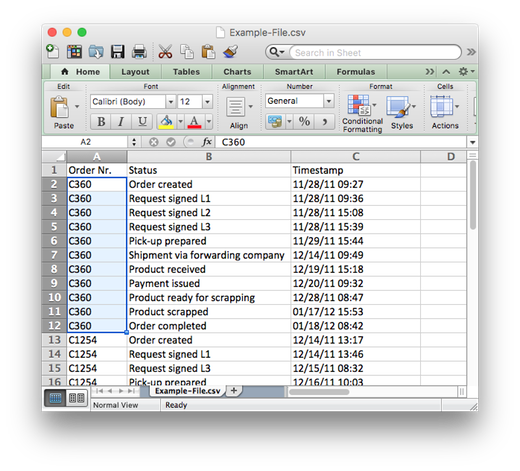
When you look for a field that can be your activity name, you may encounter a situation like shown in the picture below: The status is the same for each event in the case.
In this situation, you do have a column that tells you something about the process step, or the status, for each case. However, you don’t have the historical information about the status changes that happened over time. Often, such a field will contain the information about the current status (or the last activity that happened) for each case. However, this is not enough for process mining, where you do need the historical information on the activities.
How to fix:
If the activity name or status column never changes over the course of a case, then you cannot use the column as your activity name. You need to go back to the system administrator and ask them whether you can get the historical information on this field.
You can also look for other columns in your data set to see whether they contain information that does change over time (like an organizational unit, so that you can analyze the transfers of work between different units).
Note that even if you do have history information on your activities in the process, you may still be missing information on the activity repetitions.
Missing Timestamp History
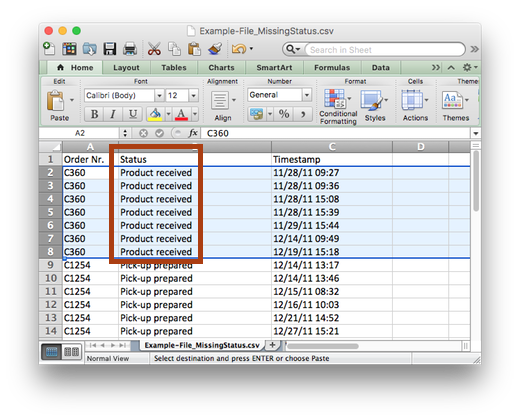
The same can happen with the timestamp fields. At first, it might seem as if you had many different timestamp columns in your data set. But does any of them change over time for the same case? Or are they all the same like in the example below?
How to fix:
If your timestamp field never changes over the course of a case, then this is a data field but not a timestamp field as you would need for process mining. If you only have timestamp columns that never change, then you don’t have a timestamp column at all.
If your data is sorted in such a way that the evens are the right order, then you can still import the data set into Disco. Even without a timestamp, you can then still analyze the process flow and the variants (based on the sequence information in the imported data set), but you won’t be able to do a performance analysis.
Missing Resource and Attribute History
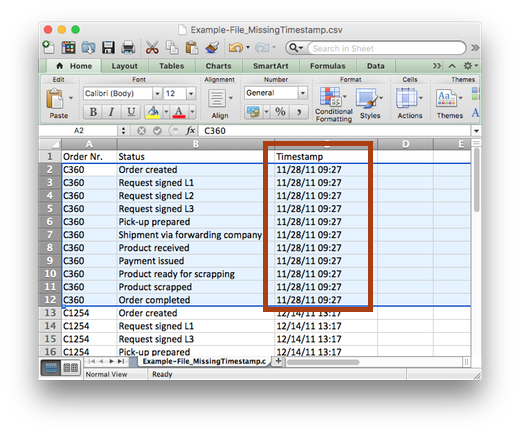
A similar situation can occur with other data fields, like a resource field or another data attribute. For example, in the data set below, the resource column does not change over the course of the case.
Instead of the person who performed a particular process step, the ‘Resource’ field above could indicate the employee that started the case, who is responsible for it, or the person that last performed a step in the process.
The same can happen with a data field, like the ‘Category’ attribute in the example above, where you might know that the field can change over time but in your data set you only see the last value of it.
How to fix:
If you can’t get the historical information on this field, request a data dictionary from the IT administrator to understand the meaning of the field, so that you can interpret it correctly.
Realize that you cannot perform process flow analyses with this attribute (for example, no social network analysis will be possible based on the resource field in the example above). You can still use these fields in your analysis as a case-level attribute.
Missing History for Derived Attributes
Finally, the missing history information on attributes might even be trickier to detect. For example, take a look at the data set below. We see that the registration of the step ‘Shipment via forwarding company’ in case C360 has been performed by a ‘Service Clerk’ role. However, for case C1254 the same step was performed by a ‘Service Manager’ role, which if we know the process might strike us as odd.
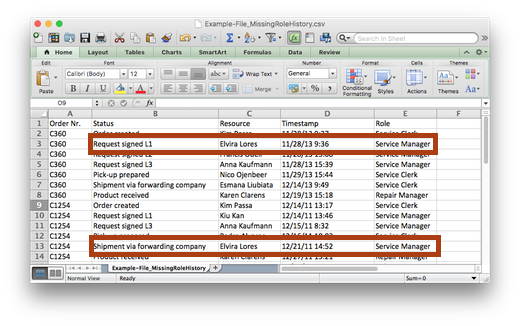
If we look deeper into the problem, then we find out that the ‘Role’ information was actually extracted from a separate database and linked to our history data set later on. However, the ‘Role’ information that was linked contains the roles of the employees today.
In 2011, when case C1254 was performed, Elvira Lores still was a ‘Service Clerk’. But by 2013, when case C360 was performed, Elvira had become a ‘Service Manager’. However, we can’t see that Elvira performed the step ‘Shipment via forwarding company’ back then in the role of a ‘Service Clerk’ because we only have her current role information!
How to fix:
As with the other examples above, there is typically not much that you can do about this in the short term. The most important part is that you are aware of this data limitation, so that you can interpret the results correctly.
-
One exception is when your data is formatted in such a way that the activities are in columns rather than rows. Take a look at the following article to see what you can do in this situation: http://fluxicon.com/blog/2016/10/data-quality-problems-in-process-mining-and-what-to-do-about-them-part-10-missing-timestamps-for-activity-repetitions/. ↩︎
Leave a Comment
You must be logged in to post a comment.






