

Combining Process Mining and Simulation

In the above image, Astronaut Christer Fuglesang participates in an underwater simulation to practice for an extravehicular activity scheduled for the 19th shuttle mission to the International Space Station. He wants to make sure he knows the effect of every step by heart, so that he does not make any mistakes when the time comes.
What if you could “try out” the effects of your own process improvements before actually making the change in the organization? What if you could actually compare the impact of alternative “What-if” scenarios for possible changes in your process, and then choose the best one?
People sometimes ask us whether Disco can simulate the effect of removing a process step here, or reducing some flow times in the process there. And for simple scenarios you can actually do that just by tweaking the input data and re-running the analysis. But for more advanced scenarios you need to use more advanced simulation techniques.
Simulation is the imitation of the operation of a real-world process or system over time.
While there are a lot of mature simulation tools available, one of the biggest challenges is to create an accurate base model for running simulations. If the model is flawed, your simulation results will be wrong as well!
And here is where process mining can help: Rather than assuming how your process looks, and how long each activity takes, process mining provides you with objective information about your process flows including delays and availabilities, which you can use to create a simulation model that resembles reality more closely.
Because process mining and simulation appear to be such a great match, I have teamed up with Geoff Hook from Lanner, an established predictive simulation company, to explore the combination of our process mining software Disco and their simulation software Witness.
Here is a simple example scenario of how the combination of process mining and simulation looks like:
Step 1: Discovering the Actual Process
Imagine you are the manager of a credit card application process at a bank. To understand how the process is really running, we extract the data from the IT system and perform process mining.
The first step is to import the extracted data from the credit card application process in Disco. In this example, we have just four columns: the case ID (the application number), the activity name, and a start and complete timestamp for each activity. Disco configures the columns automatically.
You can click on each of the screenshots below to see a larger version:

After pressing the ‘Start import’ button, the process map is automatically created by Disco.
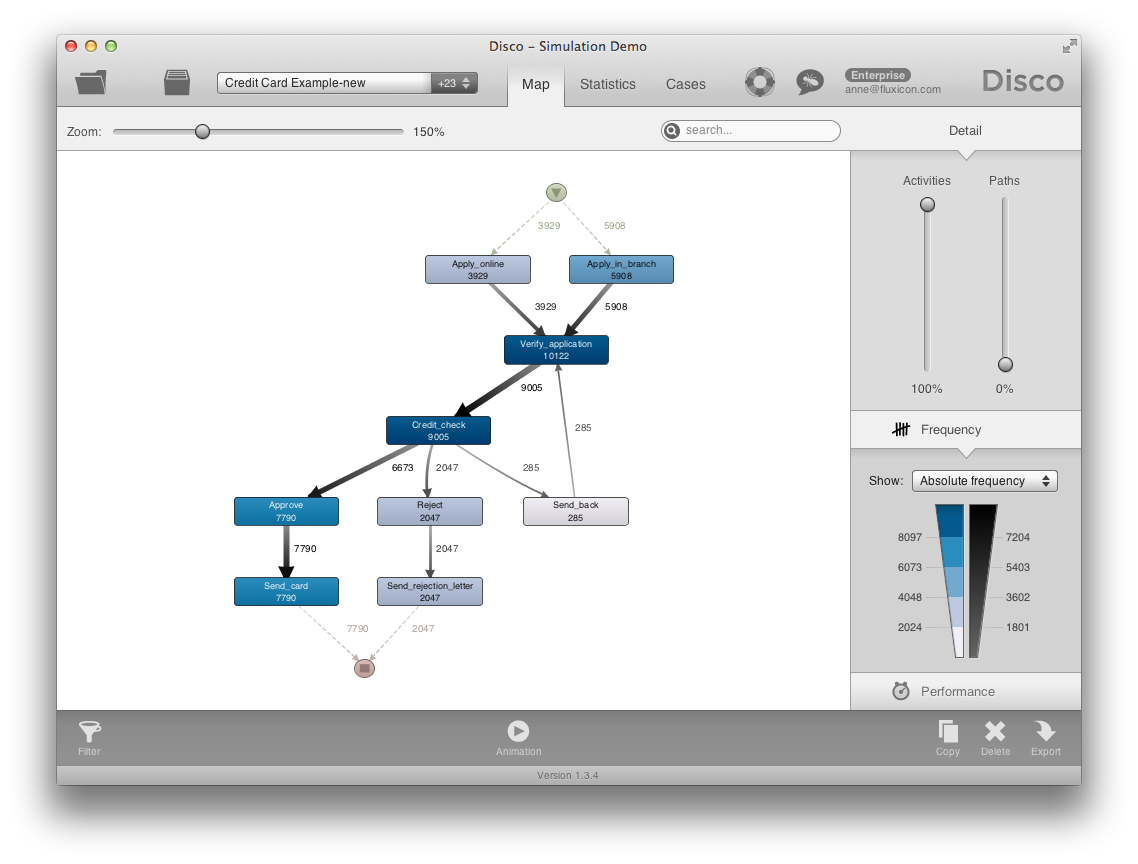
We can determine how detailed we want to see the process …
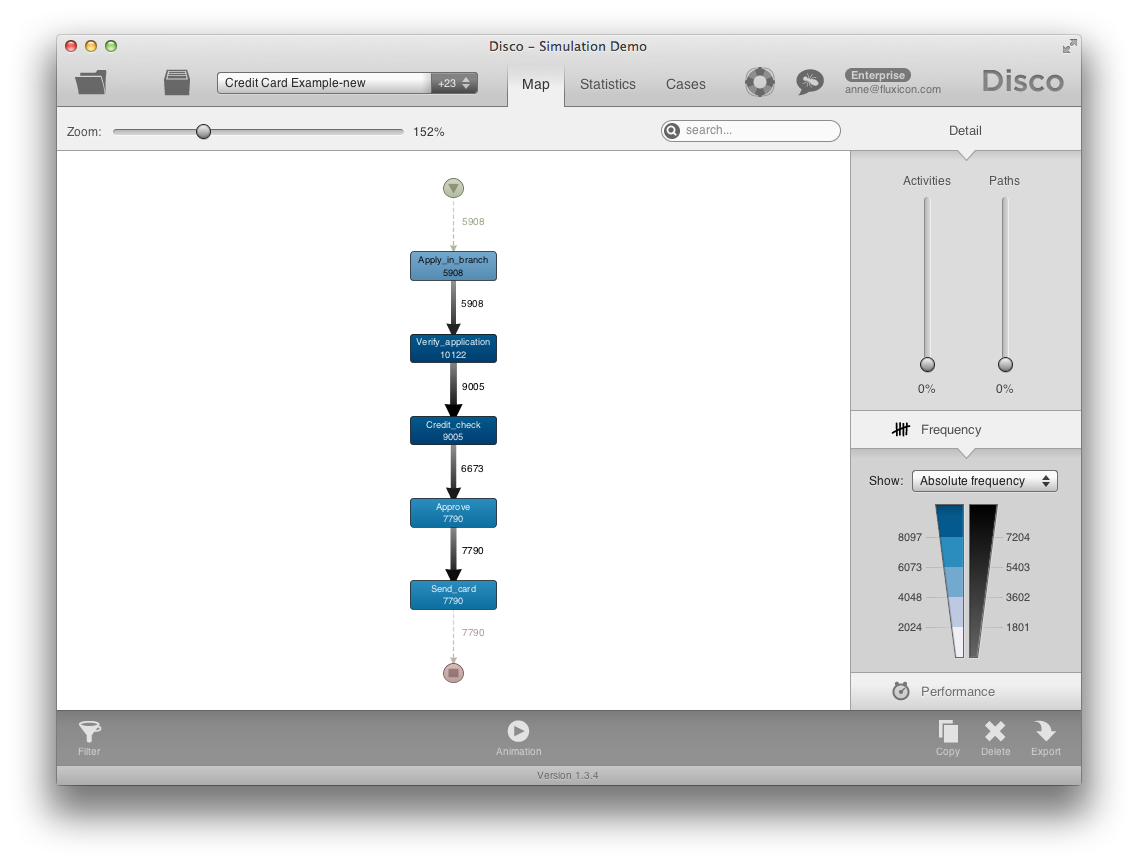
… and the frequency numbers show us how often each path has been used in reality.

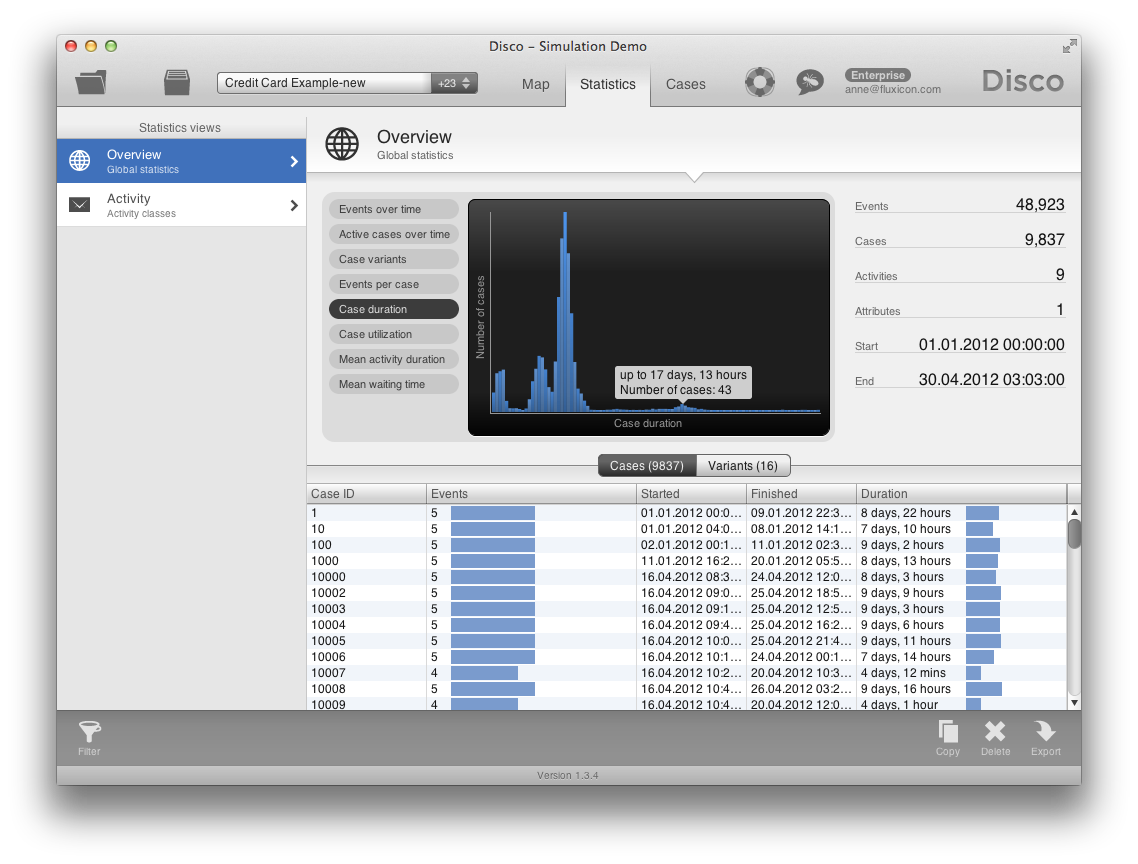
We analyze the case durations and we can see that some of the applications take up to 17 days. In fact, 90% of the applications take more than 9 days. The problem is that customers start going to other banks, because they are faster.
In the performance view of the process map we can see where the bottleneck is. For example, the credit check step is delayed, on average, by 4.2 days.
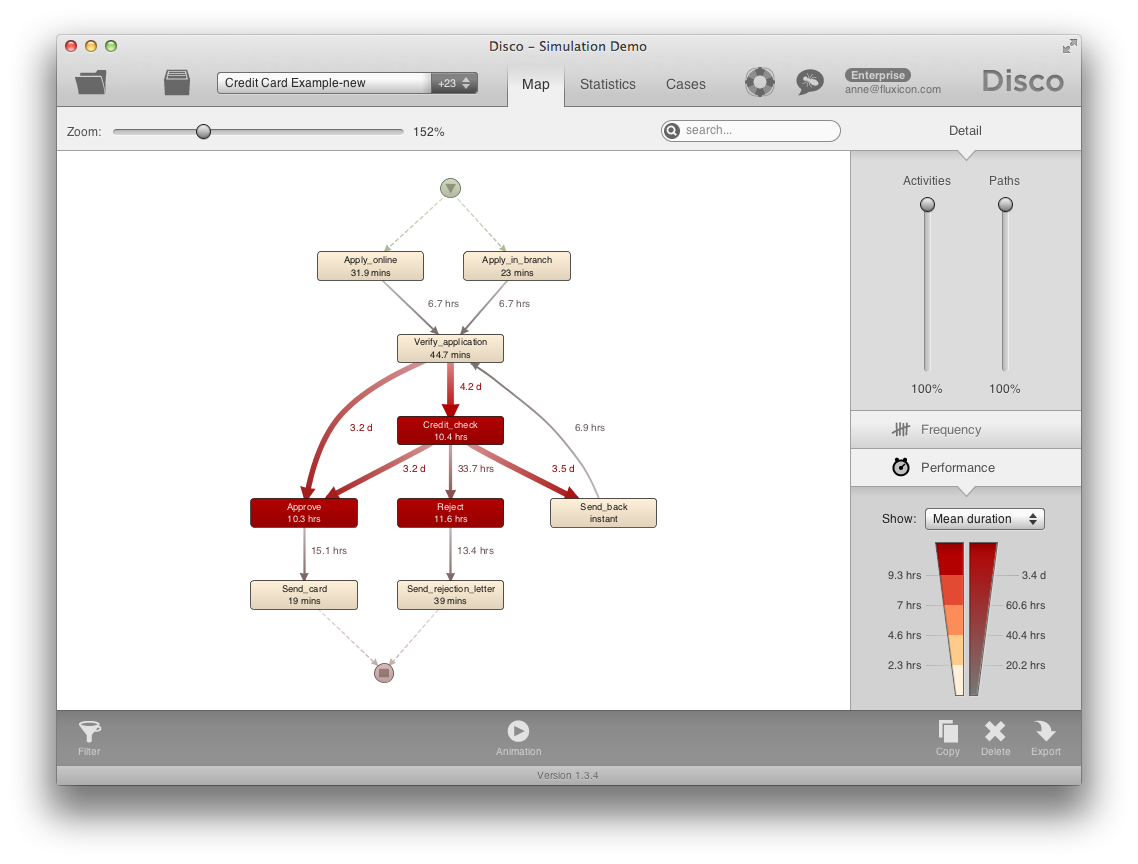
Process mining shows us the actual process flows, including deviations, rework, and bottlenecks. In addition, it gives us objective information about the frequency of chosen process paths, and about the timing of activities and waiting times in the process.
Step 2: Simulating the As-Is Process
All this is fantastic information to use as a starting point for our simulation. Instead of creating our simulation model from a blank sheet of paper, we want to re-use the discovered process to create a simulation model for the As-is process.
Simulating the As-is process can provide more understanding and insight, but recall that the goal is to use a valid simulation model to predict the performance of alternative ‘to-be’ scenarios. However, this step also provides us with a way to check how accurate our model is.
In our prototype project with Lanner, we captured data from Disco in an Excel workbook. A Witness framework model was designed which accepts this data and automatically instantiates the activities, routing and timing data defined in Excel. This framework model also contains some KPIs that can be exported back to Excel to measure the simulated performance.
The following provides examples of the data required.
Activities: A definition of each Activity in the model.
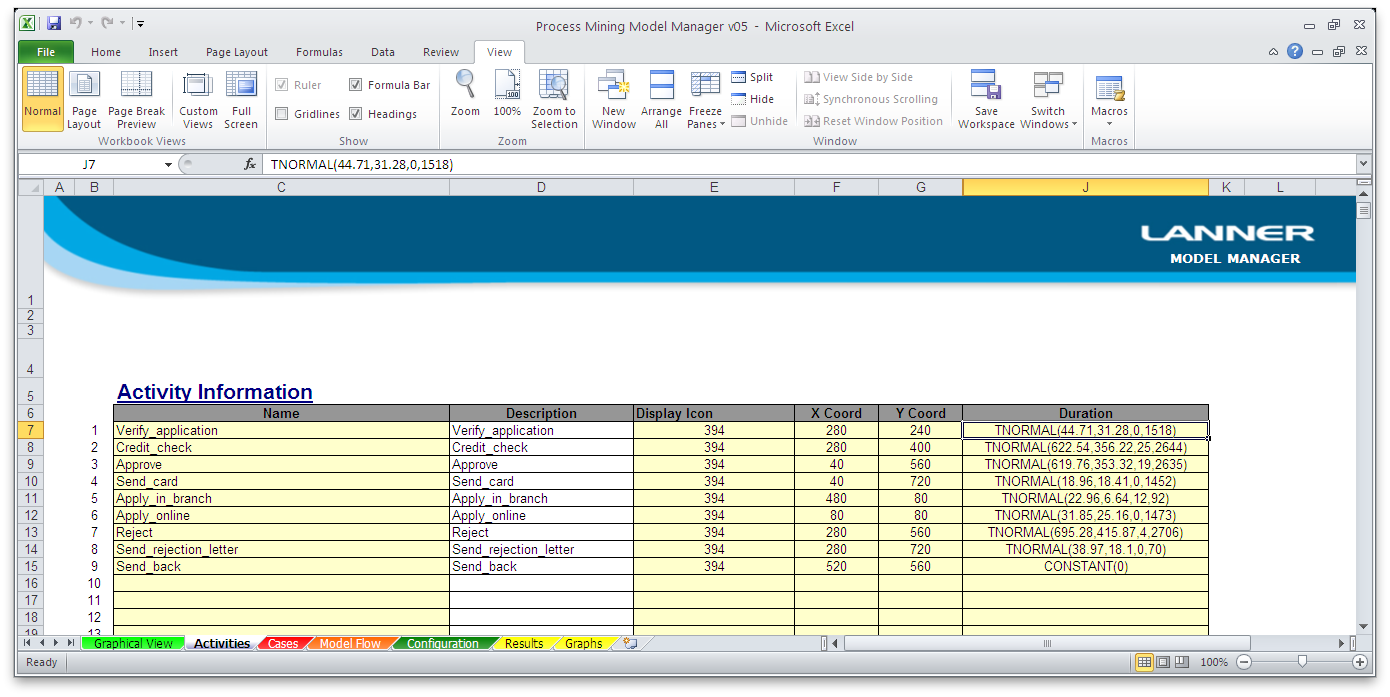
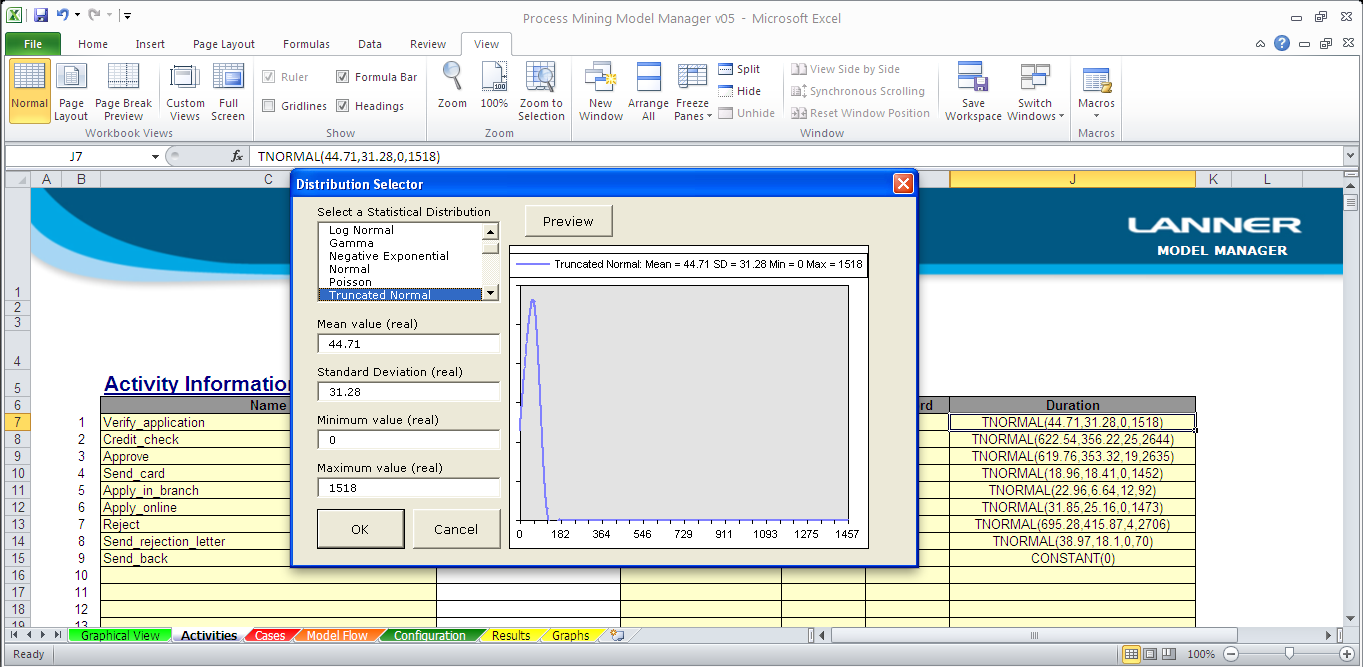
Activity Times: Distributions can be defined from the process execution to provide a valid means of generating process times for simulation.
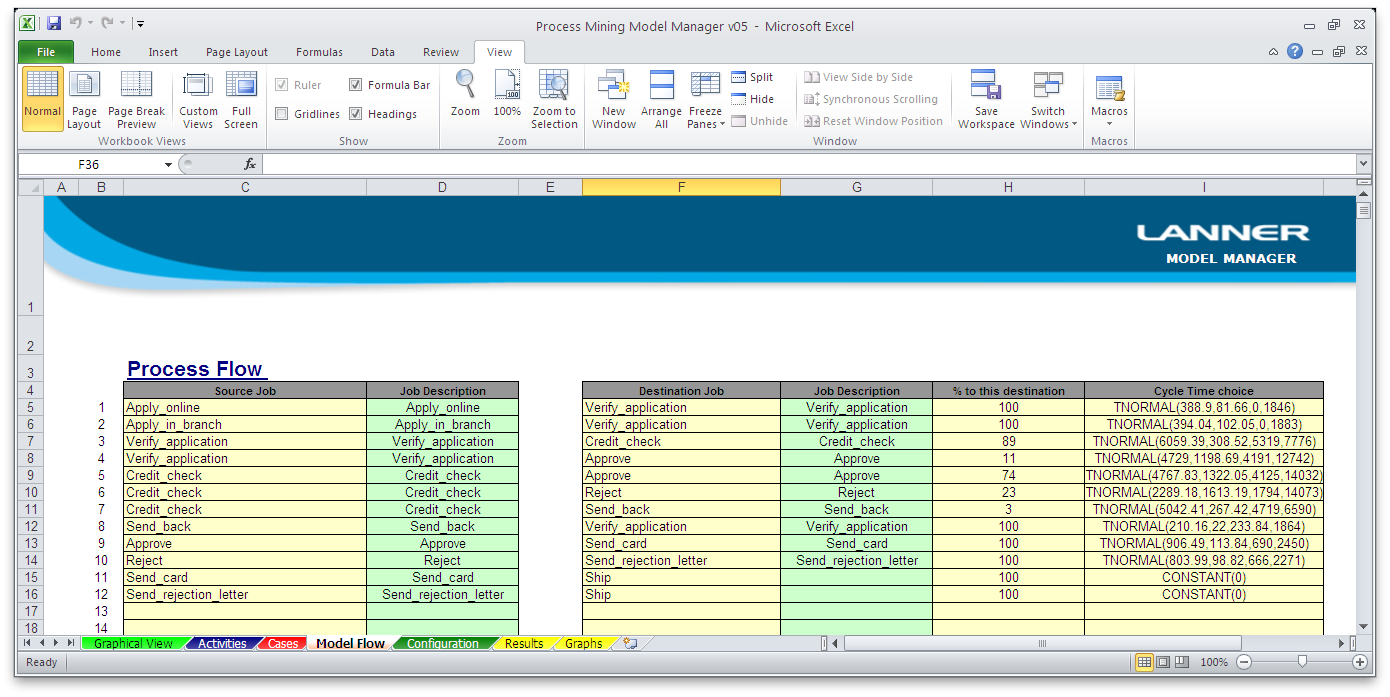
Routings: Probablities are used to define the routing in the model.
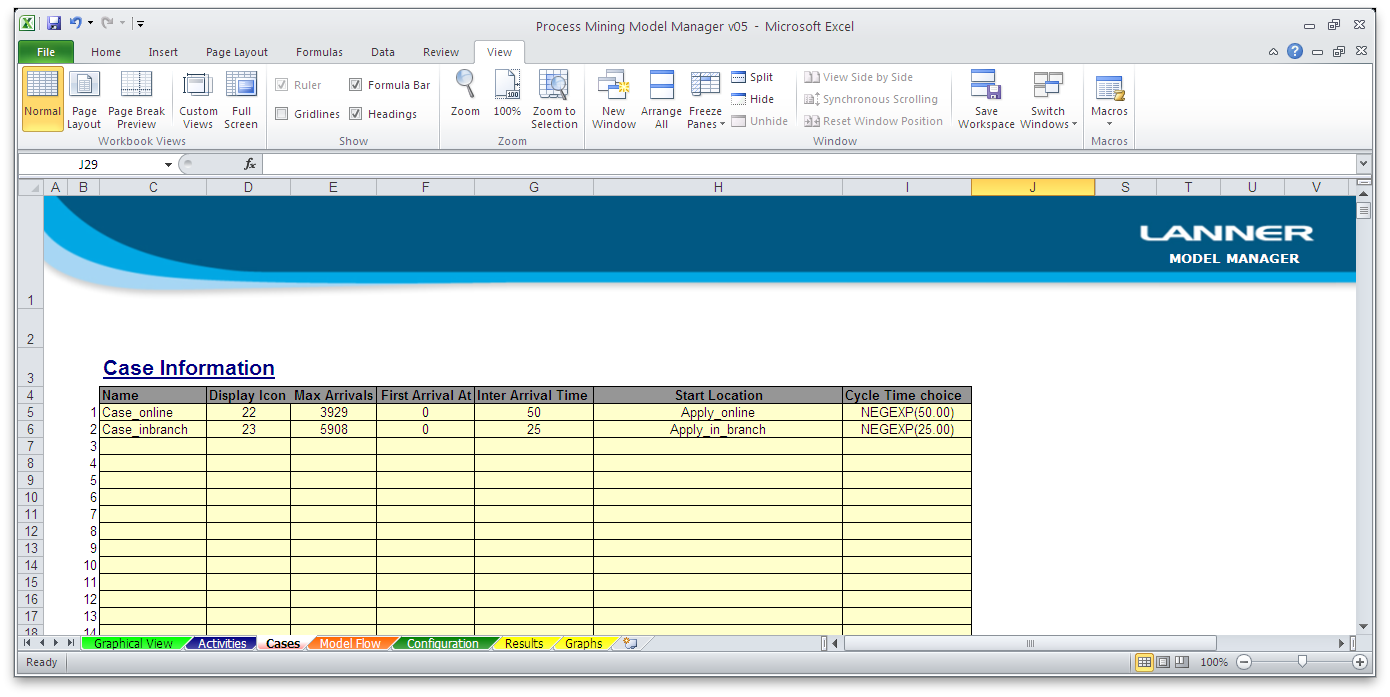
Case information: This data is used to provide the input of work to the model.
Simulation: The Simulation model is automatically created from the Excel data. This includes a “layout” similar to DISCO, in the prototype. This model runs in WITNESS and shows the flow of cases through the system, collecting performance statistics along the way.

Results: Results are exported to Excel and include the frequency that each Activity occurs, throughput times and more.
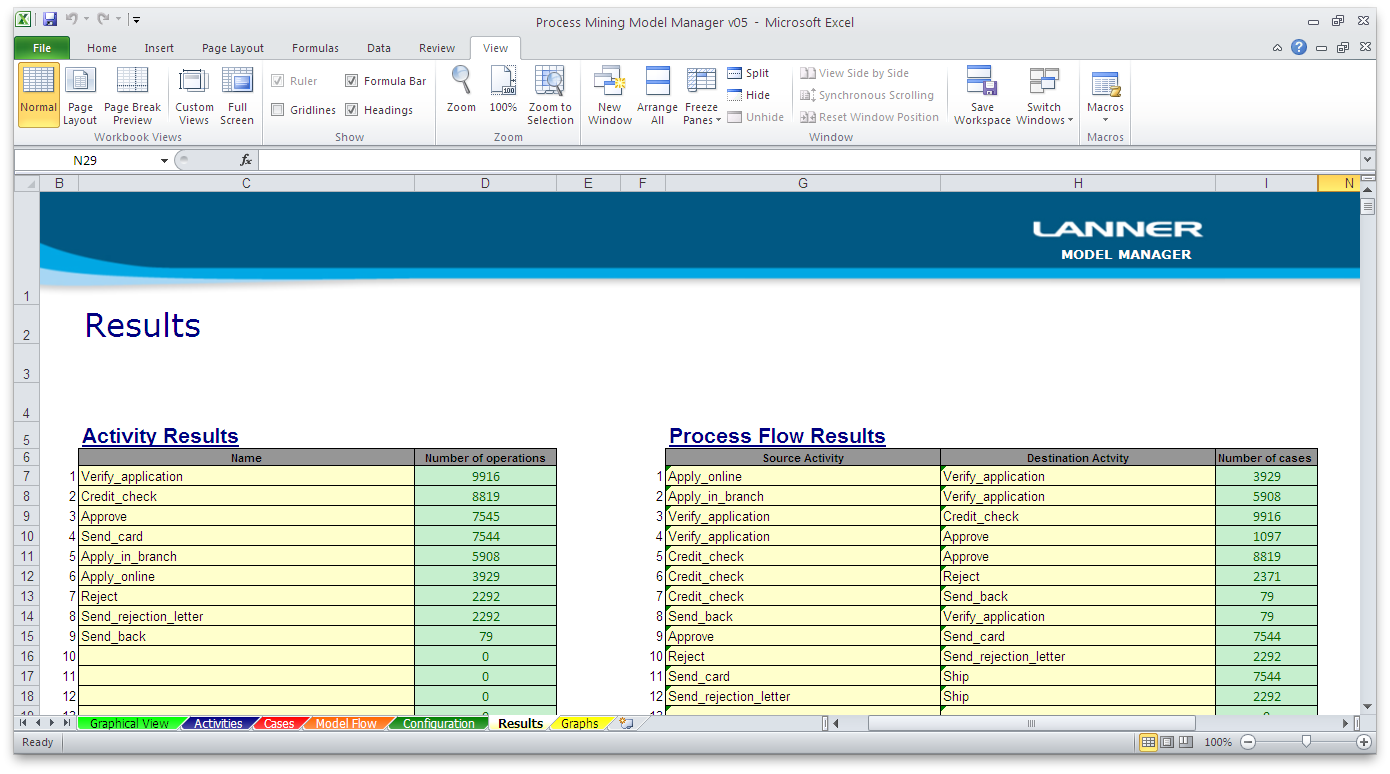
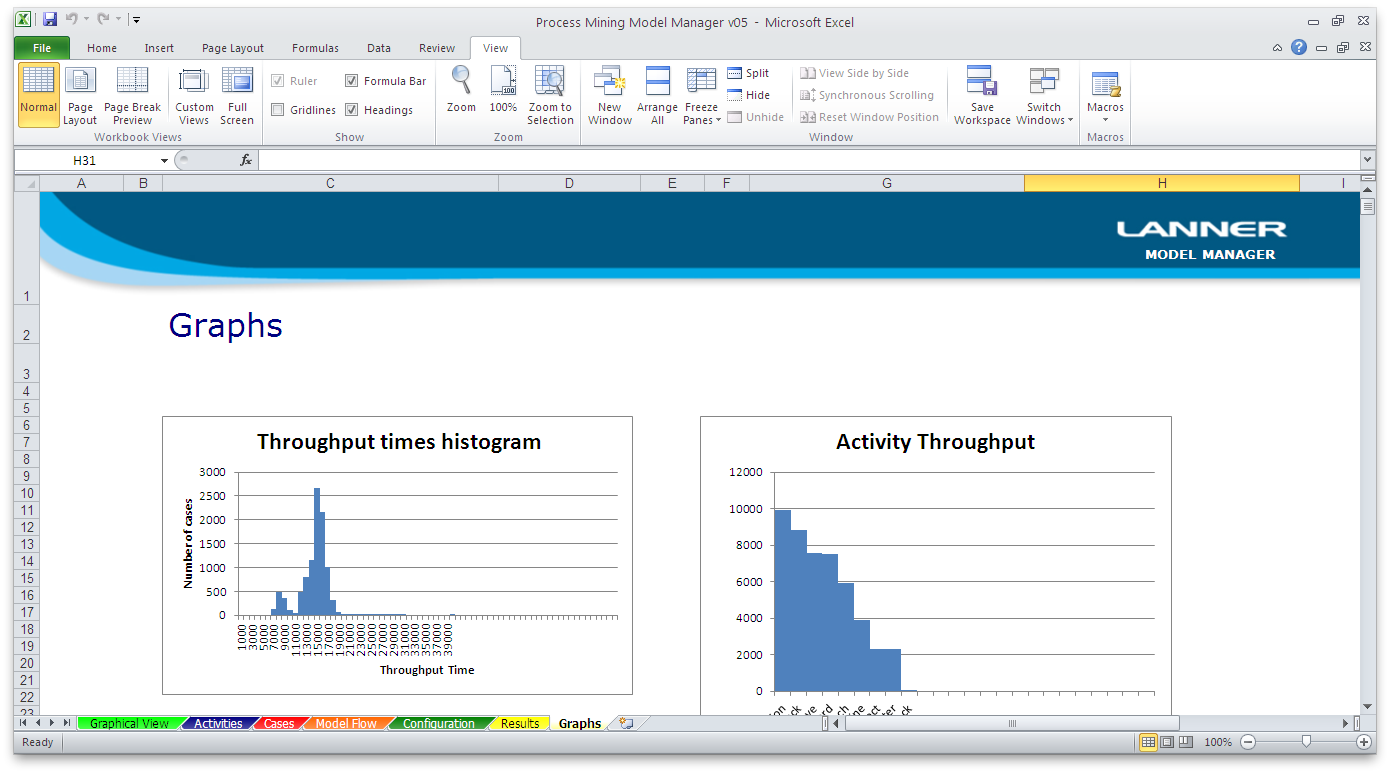
From the results of the simulation we can see whether the ‘As-Is’ process has been captured accurately by the simulation model. For example, if you compare the throughput times histogram produced from the simulation run in Witness with the case duration statistics in Disco above, you recognize a similar shape of distribution.
Note that this is not obvious, because the simulation is built on parameters approximating the real process (and not built based on complete instance data like the process mining analysis).
Step 3: Exploring What-If Scenarios
Now that we have a good simulation model, we can move on to explore “what-if” scenarios. During the process mining analysis I have seen that there is a bottleneck before the credit check in my process. So, for example, if I move resources from the verification step to the credit check, can the bottleneck be resolved and customers can get their cards in less than 5 days?
By changing the parameters and structure of the simulation model, I can explore the impact on the overall process for “what-if” process improvement scenarios like the following:
-
What if I eliminate this activity?
-
What if we reduce the processing time for this activity?
-
What if, instead of 30%, 70% of the cases would follow the Straight Through Processing (STP) path?
-
What if we could reduce the waiting and queuing in this part of the process?
-
What if we combined those activities into one step by the same person?
-
What if these two activities were done in parallel instead of in sequence?
-
…
There are endless scenarios like these, and the value of the possibility to estimate the impact of alternative improvement scenarios before spending millions on changing the whole organization to actually implement one of them is huge.
Your Feedback
Obviously, the parameters that we included allow for only simple simulation scenarios at the moment. For example, the simulation model does not even consider people yet. The usefulness of simulation stands and falls with the quality of the simulation models. I recommend to read Bruce Silver’s articles on making simulation useful and why simulation in most BPM tools is actually a fake feature.
In fact, there are at least two aspects to making good simulation models:
-
The capabilities of the simulation tool to model various process parameters. This is what Bruce is talking about in his criticism, but most of the mature and specialized simulation tools now actually give you all the capabilities that you need.
-
The suitability of the simulation model itself for the problem at hand. This is often harder than it sounds.1 It’s not practical to put the whole world in the simulation model. Instead, you want to capture the relevant parameters for the problem at hand in a model as compact as possible.
To address the latter point, we would be very curious about the type of questions that you would like to answer with simulation. What is the goal? Is it about managing workload? Is it to drive down throughput times? Is it to optimize the availability of resources? What else?
Also: Have you worked with simulation in the past? Would you use process mining and simulation together?
Contact Geoff or myself directly to continue the discussion.
-
For example, in my PhD thesis (see Chapter 9) we have explored the discovery of simulation models through process mining techniques. One of the problems was that the availability of people is much lower in reality due to the fact that people work in multiple processes, at varying speeds, etc. We are not machines, and capturing the right causal dependencies in a simulation model can be really difficult. There has been follow-up work on improving the modeling of human behavior in simulation models through the use of chunks. For a recent and comprehensive overview about the state of the art of process mining and simulation, I recommend to read Wil van der Aalst’s Business Process Simulation Survival Guide. ↩︎
Leave a Comment
You must be logged in to post a comment.






