
Change in Perspective with Process Mining

This article has been previously published as a guest post on the Data-Science-Blog (in German) and on KDnuggets (in English).
Data Scientists spend a large part of their day on exploratory analysis. In the 2015 Data Science Salary Survey, 46% of respondents said that they use one to three hours per day on the summarizing, visualization, and understanding of data, even more than on data cleansing and data preparation.
Process mining is focused on the analysis of processes, and it is an excellent tool in particular for the exploratory analysis of process-related data. If your data science project concerns business or IT processes, then you need to explore these processes and understand them first before you can train machine learning algorithms or run statistical analyses in any meaningful way.
With process mining you can get a process view of the data. The specific process view results from the following three parameters:
-
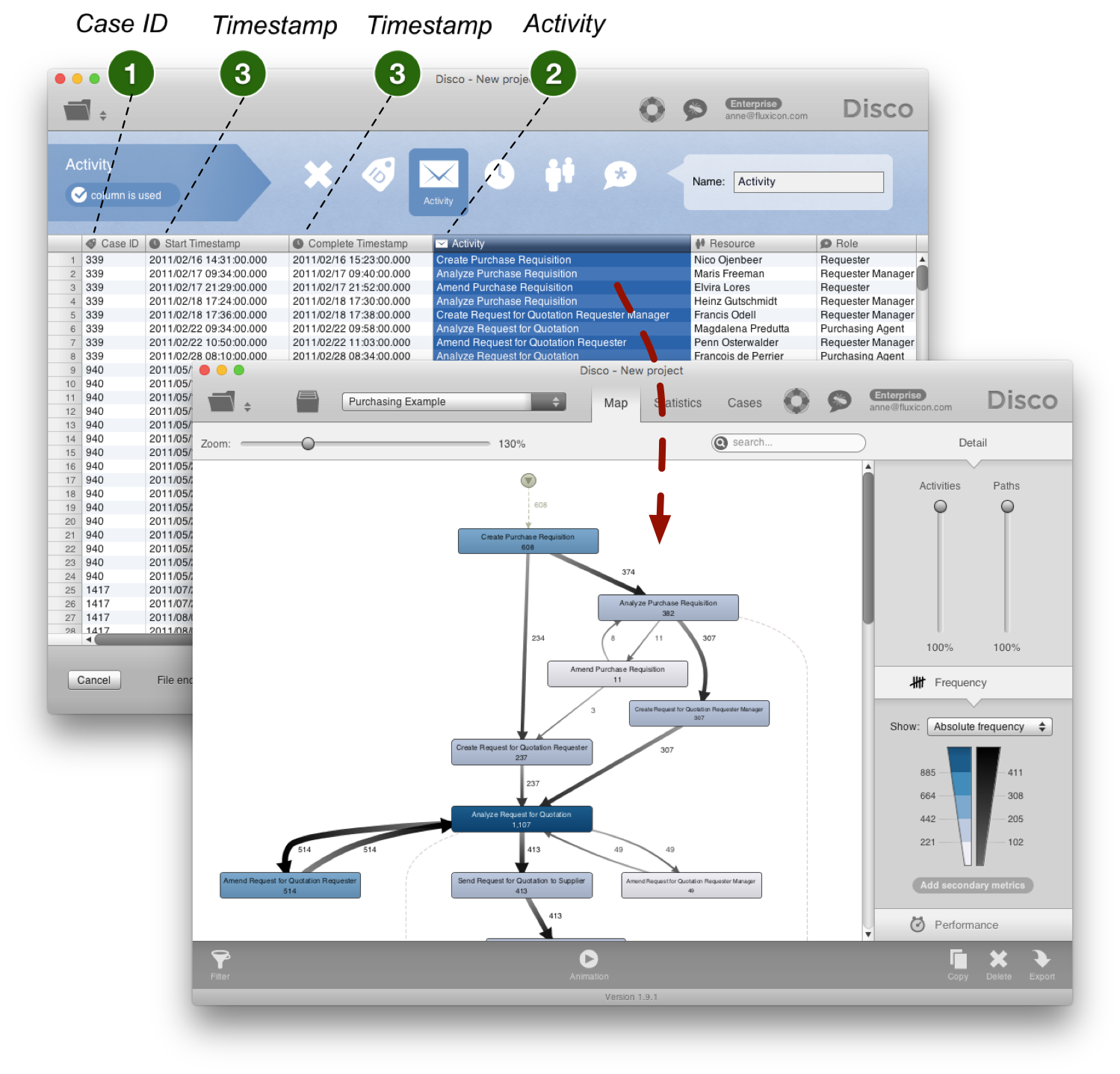
Case ID: The selected case ID determines the scope of the process and connects the individual steps of a process instance from the beginning to the end (for example, a customer number, order number or patient ID)
-
Activity: The activity name determines the steps that are shown in the process view (such as order received or X-ray examination completed).
-
Timestamp: One or more timestamps per step (for example for the beginning and the end of an X-ray examination) are used to calculate the process sequence and to derive parallel process steps.
When you analyze a data set with process mining, then you determine at the beginning of the analysis, which columns in the data correspond to the Case ID, activity name, and timestamps. You can set these parameters in the configuration when importing the data into the process mining tool.
When importing a CSV file into the process mining software Disco, you can specify for each column in your data set how it should be interpreted.1
In the following example of a purchasing process, the Case ID column (the purchase order number) is configured as Case ID, the start and complete timestamps as Timestamp, and the Activity column as Activity. As a result, the process mining software automatically produces a graphical representation of the actual purchasing process based on historical data. The process can now be further analyzed based on facts.
Usually, the first process view and the import configuration derived from itfollows from the process understanding and task at hand.
However, many process mining newcomers are not yet aware of the fact that a major strength of process mining, as an exploratory analysis tool, is that you can rapidly and flexibly take different perspectives on your process. The above parameters function as a lens with which you can adjust process views from different angles.
Here are three examples:
1. Focus on Another Activity
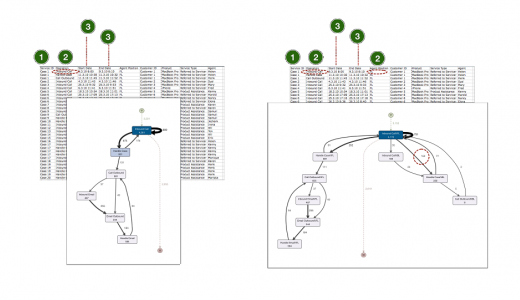
For the above purchasing process, we can change the focus on the organizational process flow by setting the Role column (the function or department of the employee) as Activity.

This way, the same process (and even the same data set) can now be analyzed from an organizational perspective. Ping-pong behavior and increased transfer times when passing on operations between organizational units can be made visible and addressed.
2. Combined Activity
Instead of changing the focus, you can also combine different dimensions in order to get a more detailed picture of the process.
If you look at the following call center process, you would probably first set the column Operation as activity name. As a result, the process mining tool derives a process map with six different process steps, which represent the accepting of incoming customer calls (Inbound Call), the handling of emails, and internal activities (Handle Case).

Now, imagine that you would like to analyze the process in more detail. You would like to see how many first-level support calls are passed on to the specialists in the back office of the call center. This information is actually present in the data. The attribute Agent Position indicates whether the activity was handled in the first-level support (marked as FL) or in the back office (marked as BL).
To include the Agent Position in the activity view, you can set both the column Operation and the column Agent Position as activity name during the data import step. The contents of the two columns are now grouped together (concatenated).

As a result, we get a more detailed view of the process. We see for example that calls accepted at the first-level support were transferred 152 times to the back office specialists for further processing. Furthermore, no email-related activities took place in the back office.
3. Alternative Case Focus
Finally, we could question whether the service request ID of the CRM system, which was selected as the case ID, provides the desired process view for the call center process. After all, there is also a customer ID column and there are at least three different service requests noted for Customer 3 (Case 3, Case 12 and Case 14).
What if these three requests are related and the call center agents just have not bothered to find the existing case in the system and re-open it? The result would be a reduced customer satisfaction because Customer 3 has had to repeatedly explain the problem with every call.
The result would also be an embellished First Call Resolution Rate. The First Call Resolution Rate is a typical performance metric for call centers, which measures the number of times a customer problem could be solved with the first call.

That is exactly what happened in the customer service process of an Internet company. In a process mining project, initially the customer contact process (via telephone, Internet, e-mail or chat) was analyzed with the Service ID column chosen as the case ID. This view produced an impressive First Contact Resolution Rate of 98%. Of 21,304 incoming calls, apparently only 540 were repeat calls.

Then the analysts noticed that all service requests were closed fairly quickly and almost never re-opened again. To analyze the process from the customers perspective, the Customer ID column was chosen as a case ID. This way, all calls of a specific customer in the analyzed time period were summarized into one process instance and repeating calls became visible.
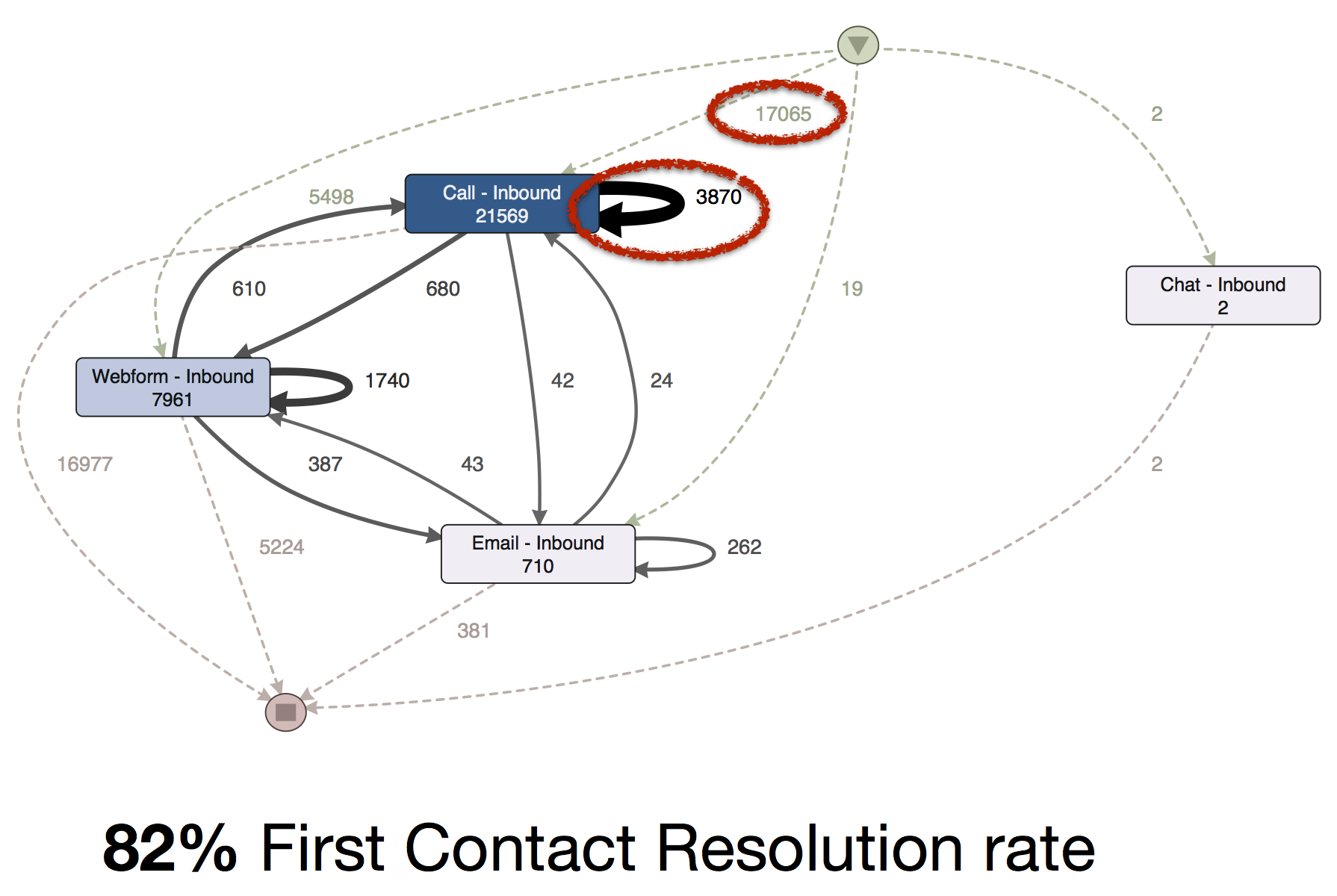
The First Contact Resolution Rate in reality amounted to only 82%. Only 17,065 cases were actually started by an incoming call. More than 3,000 were repeat calls, but were counted as new service requests in the system (and on the performance report!).
Conclusion
Process mining allows you to get a process perspective on your data. Moreover, it is worthwhile to consider different views on the process. Look out for other activity perspectives, possible combinations of fields, and new perspectives on what constitutes the case in the process.
You can take different views to answer different questions. Often, multiple views are necessary to obtain an overall picture of the process.
Do you want to explore the perspective changes presented in this article yourself in more detail? You can download the used example files here and analyze them directly with the freely available demo version of our process mining software Disco.
-
Note: For the open-source software ProM (http://www.promtools.org/) you often use XML formats such as XES or MXML, which contain this configuration. ↩︎
Leave a Comment
You must be logged in to post a comment.






