
Case Study: Auditing With Process Mining — Part VIII: Discovered Model

This is the 8th article in our case study series on auditing with process mining. The series is written by Jasmine Handler and Andreas Preslmayr from the City of Vienna. You can find an overview of all the articles in the series here.
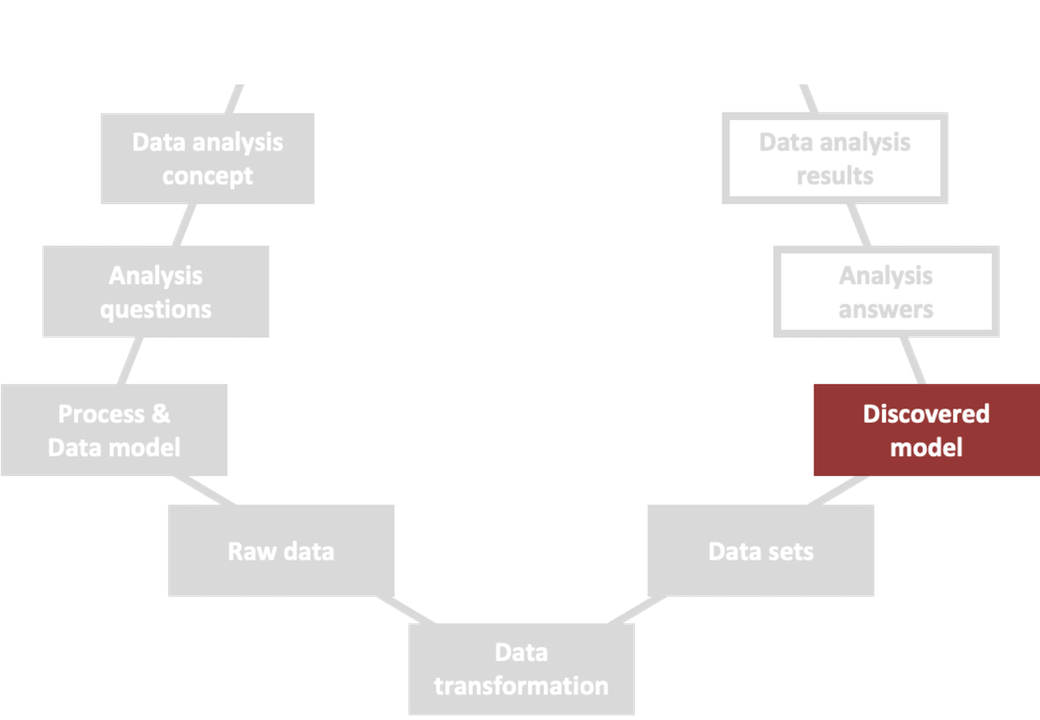
Once we had access to our transformed data sets, we loaded the data into the process mining software Disco and got a first impression of the complexity of the process.
Although we had worked with simplification methods from the beginning and focused on the activities from the high-level reference process to identify relevant data tables, the process map was still very complex. Figure 10 shows the discovered process model from an order perspective.

Figure 10: Discovered process model
Due to the high complexity, we applied further simplification strategies to enable an explorative analysis and a should-be comparison of the real process paths and the reference process.
Firstly, by including most of the timestamp fields that we could find, we had derived a high number of activities from the raw data files. Among these activities were administrative process steps that were outside our reference process. We reduced the number of activities by only keeping those process steps that we could directly map to the high-level reference process (Milestone simplification method). This reduced the number of activities from more than 100 to approximately 50. Note that the data in the IT system was still more detailed than the high-level process. For example, a purchase order could be checked, rejected, and released on different levels (see Figure 11).

Figure 11: Mapping data to the high-level process
Secondly, there was still a high variation regarding the process paths. Therefore, we decided to cluster the data into four groups (Semantic variant simplification method). These four groups were:
-
canceled cases,
-
cases without an invoice,
-
cases with one invoice, and
-
cases with multiple invoices.
By looking at each data segment separately, the number of process variants was further reduced.
Finally, we also decided to focus on the most common process paths to get an overview of the mainstream behavior (Variant simplification method). Figure 12 shows the discovered model based on only the ten most frequent process variants. This helped us to get an overview of the main process before going into detail and analyzing the less frequent paths and how they deviate from mainstream behavior.

Figure 12: Discovered model after simplification
Due to the complexity reduction, we could now perform an explorative analysis, searching for inconsistencies and analyzing unexpected process paths in more detail.
New parts in this auditing series will appear on this blog every week. Simply come back or sign up to be notified about new blog entries here.
Leave a Comment
You must be logged in to post a comment.






