
CamundaCon 2020.2 Day 2: roadmap, business-driven DMN and ethical algorithms
Blog: Column 2 - Sandy Kemsley
I split off the first part of CamundaCon day 2 since it was getting a bit long: I had a briefing with Daniel Meyer earlier in the week on the new RPA integration, and had a lot of thoughts on that already. I rejoined for Camunda VP of Product Management Rick Weinberg’s roadmap presentation, which covered what’s coming in 2021. If you’re a Camunda customer, or thinking about becoming one, you should check out the replay of his session if you missed it. Expect to see updates to decision automation, developer experience, process monitoring and interoperability.


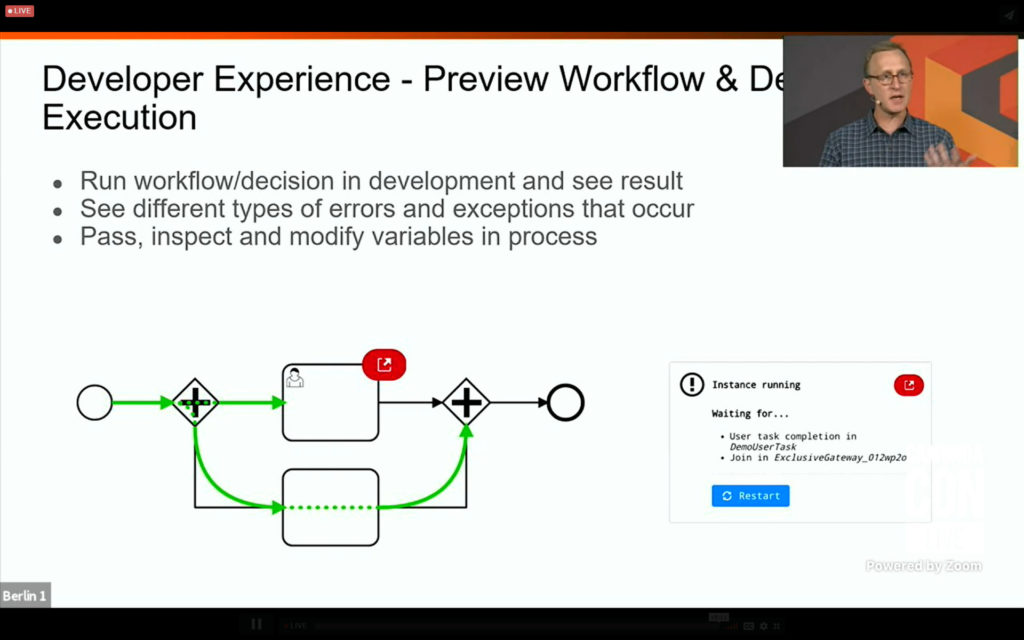
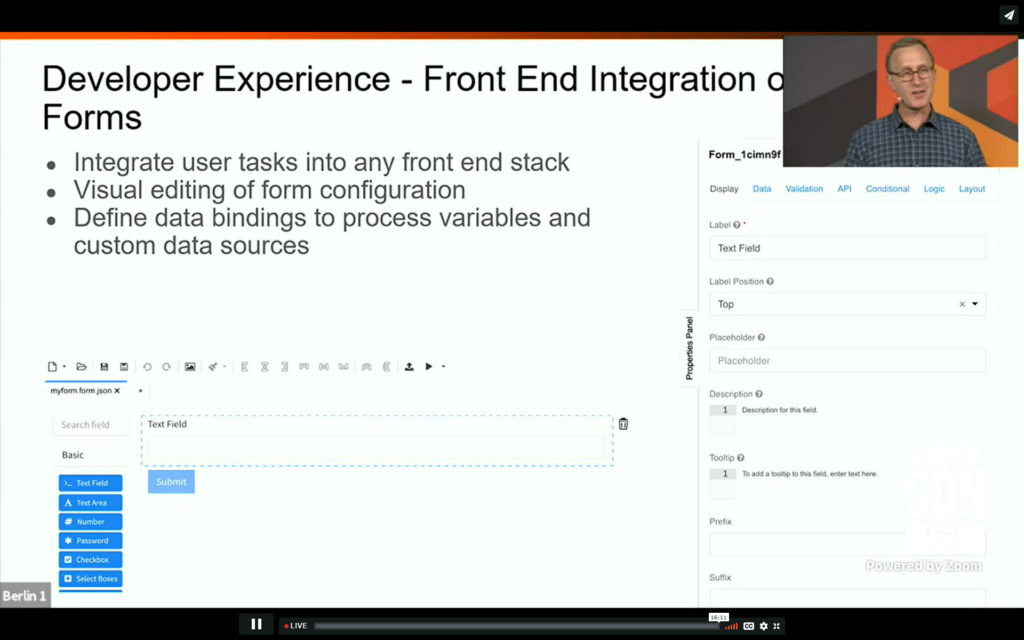
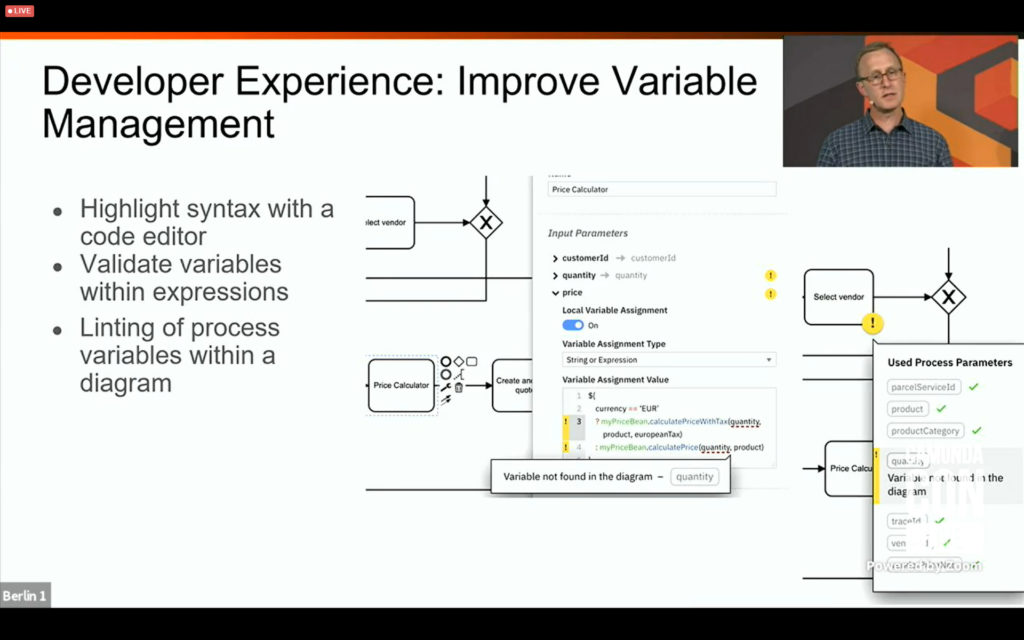
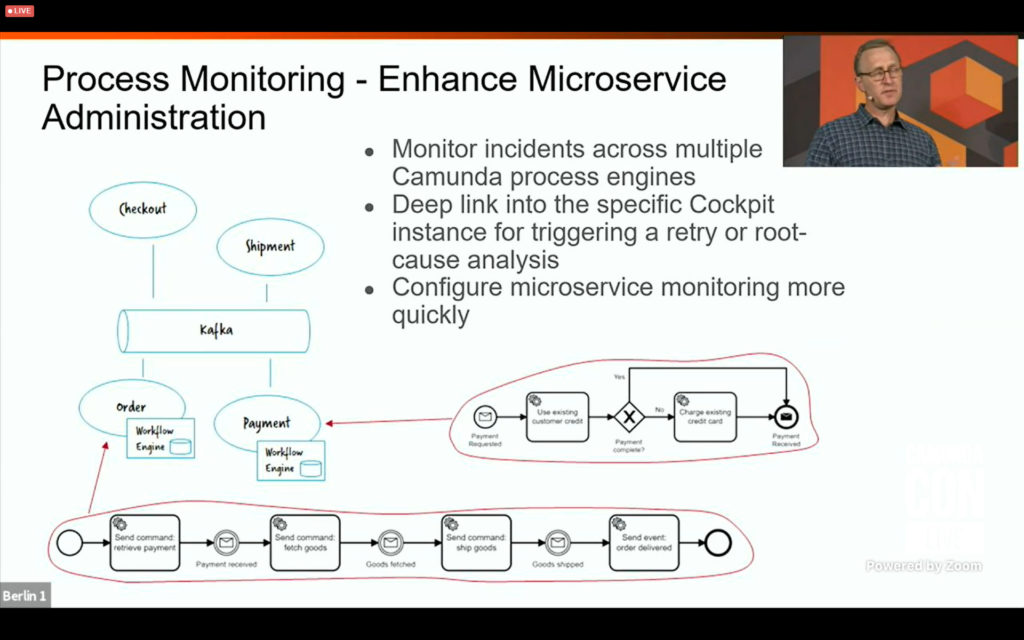


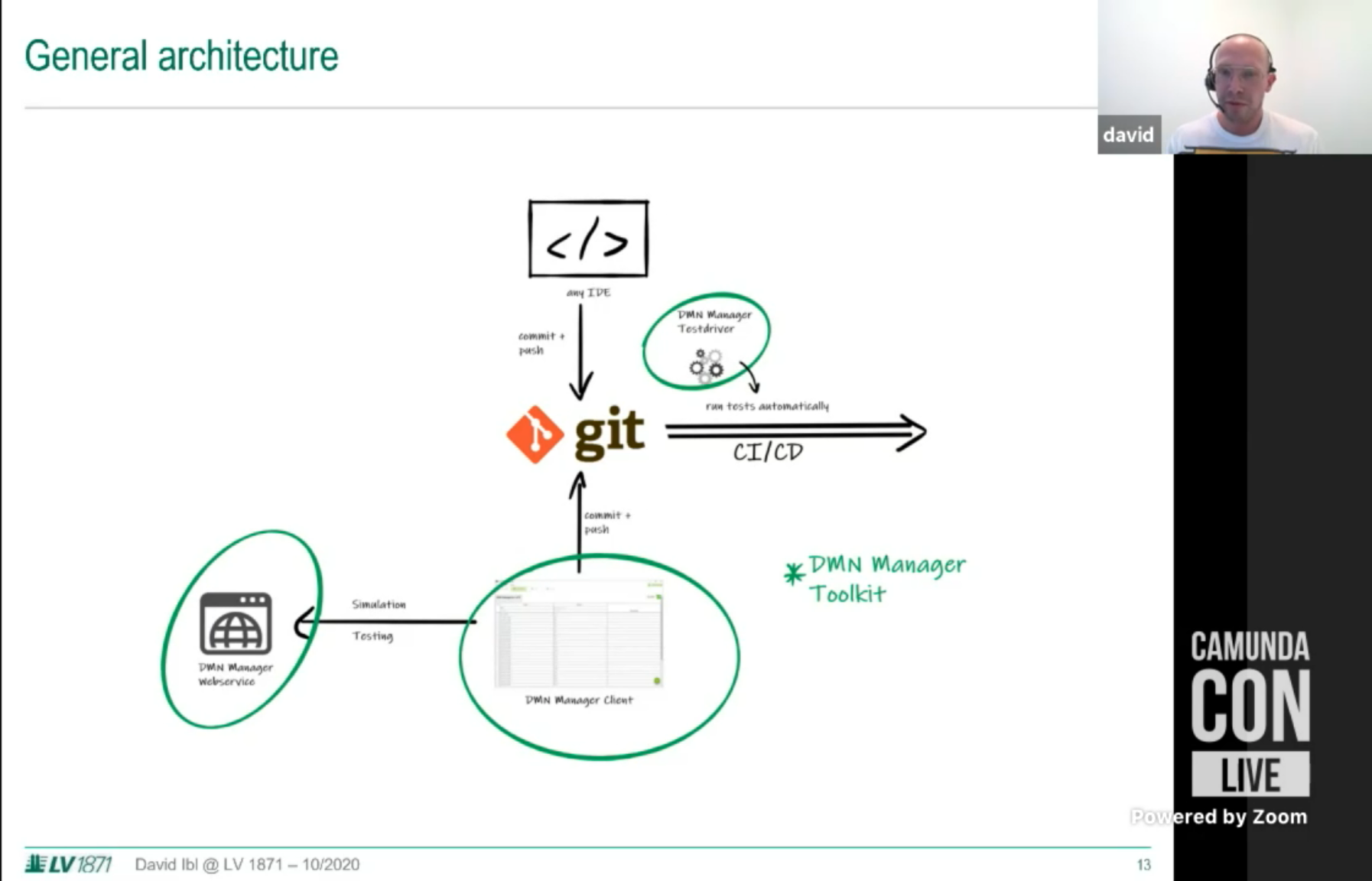
I tuned in to the business architecture track for a presentation by David Ibl, Enterprise Architect at LV 1871 (a German insurance company) on how they enabled their business specialists to perform decision model simulation and test case definition using their own DMN Manager based on the Camunda modeler toolkit. Their business people were already using BPMN for modeling processes, but were modeling business decisions as part of the process, and needed to use externalize the rules from the processes in order to simplify the processes. This was initially done by moving the decisions to code, then calling that from within the process, but that made the decisions much less transparent to the business. Now, the business specialists model both BPMN and DMN in Signavio, which are then committed to git; these models are then pulled from git both for deployment and for testing and simulation directly by the business people. You can read a much better description of it written by David a few months ago. A good example (and demo) on how business people can model, test and simulate their own decisions as well as processes. And, since they’re committed to open source, you can find the code for it on github.
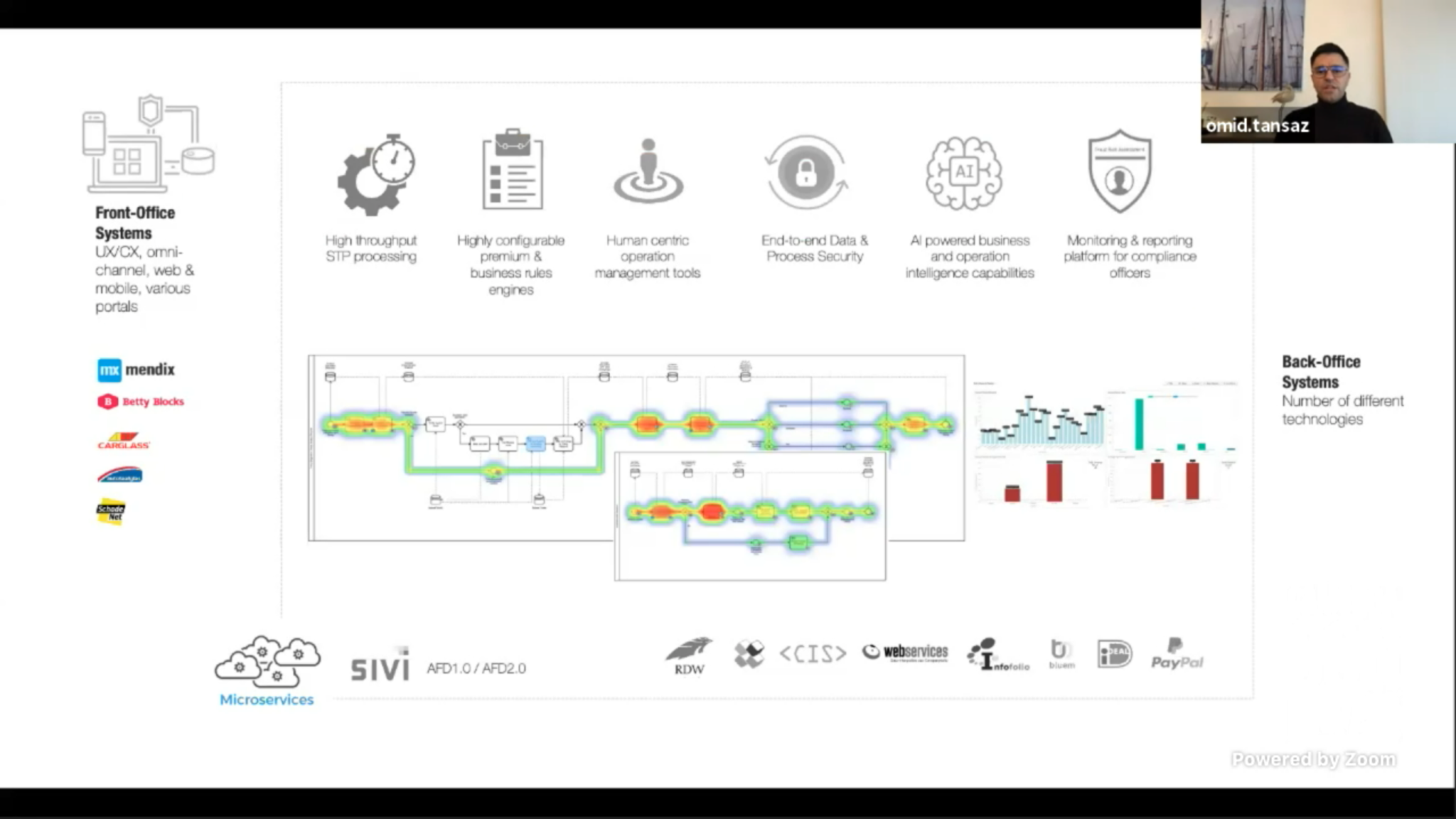
I also attended a session by Omid Tansaz of Nexxbiz, a Camunda consulting services partner, on their insurance process monitoring capability that allows systems across the entire end-to-end chain of insurance processes to be monitored in a consolidated fashion. This includes broker systems, front- and back-off systems within the insurer, as well as microservices. They were already using Camunda’s BPM engine, and started using Optimize for process visualization since Optimize 3.0 can include external event sources (from all of the other systems in the end-to-end process) as well as the Camunda BPM processes. This is one of the first case studies of the external event capability in Optimize, since that was only released in April, and show the potential for having a consolidated view across multiple systems: not just visibility, but compliance auditing, bottleneck analysis, and real-time issue prevention.

The conference closed with a keynote by Michael Kearns from the University of Pennsylvania on the science of socially-aware algorithm design. Ethical algorithms (the topic of his recent book written with Aaron Roth) are not just an abstract concept, but impact businesses from risk mitigation through to implementation patterns. There are many cases of how algorithmic decision-making shows definite biases, and instead of punting to legal and regulatory controls, their research looks at technical solutions to the problem in the form of better algorithms. This is a non-trivial issue, since algorithms often have outcomes that are difficult to predict, especially when machine learning is involved. This is exactly why software testing is often so bad (just to inject my own opinion): developers can’t or don’t consider the entire envelope of possible outcomes, and often just test the “happy path” and a few variants.
Kearns’ research proposes embedding social values in algorithms: privacy, fairness, accountability, interpretability and morality. This requires a definition of what these social values mean in a precise mathematical. There’s already been some amount of work on privacy by design, spearheaded by the former Ontario Information and Privacy Commissioner Ann Cavoukian, since privacy is one of the better-understood algorithmic concepts.

Kearns walked us through issues around algorithmic privacy, including the idea that “anonymized” data often isn’t actually anonymized, since the techniques used for this assume that there is only a single source of data. For example, redacting data within a data set can make it anonymous if that’s the only data set that you have; as soon as other data sets exist that contain one or more of the same unredacted data values, you can start to correlate the data sets and de-anonymize the data. In short, anonymization doesn’t work, in general.
He then looked at “differential privacy”, which compares the results of an algorithm with and without a specific person’s data: if an observer can’t tell the discern between the outcomes, then the algorithm is preserving the privacy of that person’s data. Differential privacy can be implemented by adding a small amount of random noise to each data point, which makes is impossible to figure out the contribution of any specific data point., and the noise contributions will cancel out of the results when a large number of data points are analyzed. Problems can occur, however, with data points that have very small values, which may be swamped by the size of the noise.
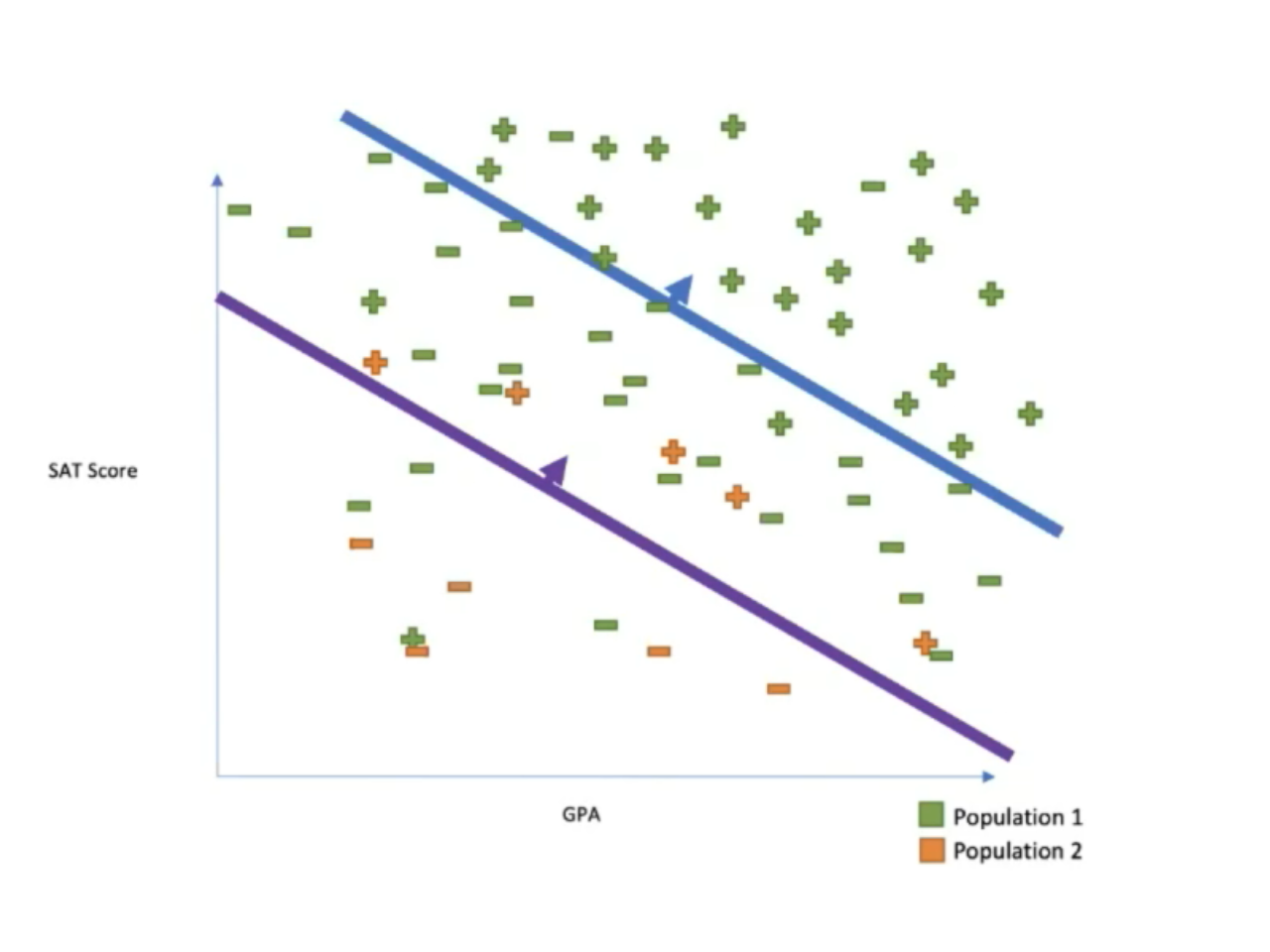
He moved on to look at algorithmic fairness, which is trickier: there’s no agreed-upon definition of fairness, and we’re only just beginning to understand tradeoffs, e.g., between race and gender fairness, or between fairness and accuracy. He had a great example of college admissions based on SAT and GPA scores, with two different data sets: one for more financially-advantaged students, and the other for students from modest financial situations. The important thing to note is that the family financial background of a student has a strong correlation with race, and in the US, as in other countries, using race as an explicit differentiator is not allowed in many decisions due to “fairness”. However, it’s not really fair if there are inherent advantages to being in one data set over the other, since those data points are artificially elevated.
There was a question at the end about the role of open source in these algorithms: Kearns mentioned OpenDP, an open source toolset for implementing differential privacy, and AI Fairness 360, an open source toolkit for finding and mitigating discrimination and bias in machine learning models. He also discussed some techniques for determining if your algorithms adhere to both privacy and fairness requirements, and the importance of auditing algorithmic results on an ongoing basis.