
AWS Data Pipeline Tutorial
What is AWS?
AWS stands for Amazon Web Services. It is a cloud computing platform that provides versatile, dependable, scalable, user-friendly, and cost-effective cloud computing solutions.
AWS is a comprehensive computing platform provided by Amazon. The platform is built using a combination of infrastructure as a service (IaaS), platform as a service (PaaS), and packaged software as a service (SaaS) solutions.
This blog on AWS Data Pipeline will provide you with a thorough understanding of the following:
- What is AWS Data Pipeline?
- Features of AWS Data Pipeline
- AWS Data Pipeline Components
- AWS Data Pipeline VS AWS Glue
- Benefits of AWS Data Pipeline
- AWS Data Pipeline Pricing
- Conclusion
Wanna Learn AWS from the beginning, here’s a video for you
Alright!! So, let’s get started with the AWS Data Pipeline Tutorial
What is AWS Data Pipeline?
AWS Data Pipeline is a web service that allows you to process and transport data between AWS computing and storage services, as well as on-premises data sources, at predefined intervals.
With AWS Data Pipeline, you can easily access data from wherever it is stored, transform and process it at scale, and efficiently transfer the results to AWS services such as Amazon RDS, Amazon EMR, Amazon S3, and Amazon DynamoDB.
It enables you to create complex data processing workloads that are fault-tolerant, repeatable, and highly available.
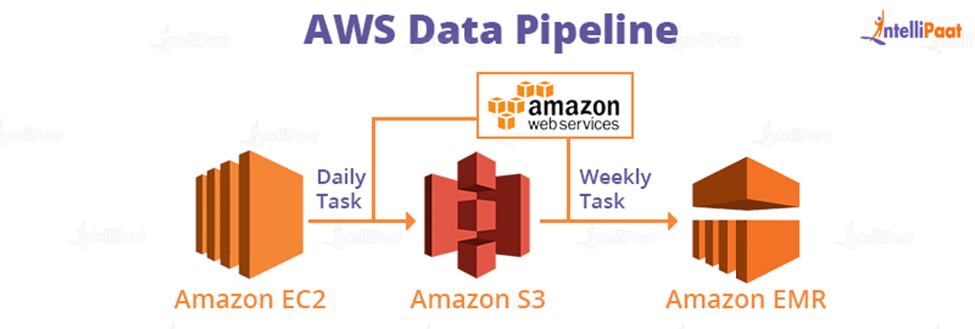
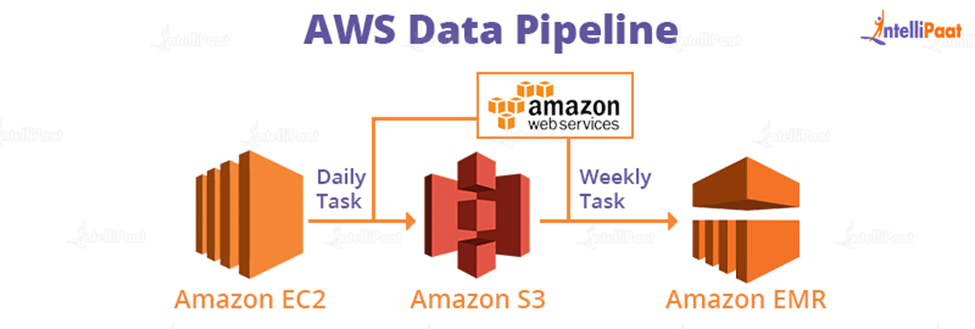
For example, you can create a Data Pipeline that extracts event data from a data source on a daily basis and then runs an Amazon EMR (Elastic MapReduce) on the data to generate EMR reports.
A tool like AWS Data Pipeline is required because it allows you to transport and convert data that is dispersed across several AWS products while also allowing you to monitor it from a single spot.
Are you excited to learn AWS from the experts, here’s a Golden opportunity for you to Enhance your career through Intellipaat’s AWS Training Course!
Features of AWS Data Pipeline
- It is simple to troubleshoot or alter your data processing logic because AWS Data Pipeline offers you complete control over the computing resources that execute your business logic.
- It has high availability and fault-tolerance design. As a result, it can efficiently operate and monitor your processing operations.
- It is very adaptable. You can create your own conditions/activities or utilize the built-in ones to make use of platform capabilities such as scheduling, error handling, and so on.
- It supports a wide range of data sources, from AWS to on-premises data sources.
- It allows you to define activities such as HiveActivity (which runs a Hive query on an EMR cluster), PigActivity (which runs a Pig script on an EMR cluster), SQLActivity (which runs a SQL query on a database), EMRActivity (which runs an EMR cluster), and others to help you process or transform your data on the cloud.
Learn more about AWS Tutorial!
AWS Data Pipeline Components
AWS Data Pipeline is a web service that allows you to automate the transport and transformation of data. You may create data-driven workflows in which tasks are reliant on the successful completion of preceding activities.
You can determine the parameters of your data transformations, and AWS Data Pipeline enforces the logic you’ve defined.
Basically, you always start constructing a pipeline with the data nodes. The data pipeline is then used in combination with computation services to transform the data.
Normally, a large amount of additional data is created throughout this procedure. So, optionally, you can have output data nodes where the results of data transformation can be stored and accessible.
Data Nodes: A data node determines the location and kind of data that a pipeline activity utilizes as input or output in the AWS Data Pipeline. It supports data nodes such as
- DynamoDBDataNode
- SqlDataNode
- RedshiftDataNode
- S3DataNode
Now, explore a real-world example to better understand the other components.
Use Case: Collect data from various data sources, analyze it using Amazon Elastic MapReduce (EMR), and create weekly reports.
In this use case, we are developing a pipeline to harvest data from data sources such as Amazon S3 and DynamoDB in order to do EMR analysis daily and provide weekly data reports.
The terms that are highlighted are now known as activities. We can optionally add preconditions for these actions to run.
Activities: An activity is a pipeline component that describes the task to be completed on time utilizing a computing resource and often input and output data nodes. Activities include the following:
- Data transfer from one site to another
- Executing Hive queries
- Making Amazon EMR reports
Preconditions: Preconditions are pipeline components that include conditional statements that must be true before an action can be performed.
- Before attempting to transfer source data, check that it is present.
- Whether or not a particular database table exists.
Resources: A resource is a computing resource that executes the task specified by a pipeline activity.
- An EC2 instance that completes the tasks specified by a pipeline activity.
- An Amazon EMR cluster that completes the tasks specified by a pipeline activity.
Finally, there is a component known as actions.
Actions: Actions are the steps taken by a pipeline component when specific events occur, such as success, failure, or late activities.
- Send an SNS notice to a subject based on activity success, failure, or lateness.
- Enable a pending or incomplete action, resource, or data node to be canceled.
Preparing for the interviews of AWS, Here’s an opportunity for you to crack like an ACE… Top AWS Interview Questions!!
Career Transition





AWS Pipeline VS AWS Glue
| Differences | AWS Pipeline | AWS Glue |
| Infrastructure Management | AWS Data Pipeline is not serverless in the same way that Glue is. It starts and controls the lifetime of EMR clusters and EC2 instances used to run your tasks. | AWS Glue is serverless, meaning there is no infrastructure to manage for developers. In Glue’s Apache Spark environment, scaling, provisioning, and configuration are all completely controlled. |
| Operational Methods | AWS Data Pipeline allows you to make data transformations using APIs and JSON, however, it only supports DynamoDB, SQL, and Redshift. | AWS Glue supports Amazon S3, Amazon RDS, Redshift, SQL, and DynamoDB, as well as built-in transformations. |
| Compatibility | AWS Data Pipeline is not limited to Apache Spark and lets you utilize other engines such as Pig, Hive, and others. | AWS Glue to execute your ETL operations in a serverless Apache Spark environment using its virtual resources. |
Benefits of AWS Data Pipeline
- Within the AWS interface, it provides a drag-and-drop console.
- AWS Data Pipeline is built on a distributed, highly available architecture that is optimized for fault-tolerant activity execution.
- It includes capabilities like scheduling, dependency tracking, and error handling.
- It makes it simple to distribute work to a single or several machines, in serial or parallel mode.
- It is a low-cost service with a low monthly fee.
- Provides complete control over the computing resources used to run your data pipeline logic.
AWS Data Pipeline Pricing
AWS Data Pipeline costs a monthly fee of $1 per pipeline if it is operated more than once per day and $0.68 per pipeline if it is run once or less per day. You should also pay for EC2 and any other resources that you use.
Courses you may like
Conclusion
AWS Data Pipeline is a better substitute for implementing ETL operations without the requirement for a separate ETL infrastructure. The crucial thing to remember here is that ETL should only use AWS components. The experience of using AWS may be rewarding. It may greatly assist enterprises in automating data flow and transformation.
You’re Doubts get resolved on Intellipaat’s AWS Community Page!!
The post AWS Data Pipeline Tutorial appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






