

Analyzing Legacy Systems with Process Mining

This is a guest article by Derek Russell from Objektum Modernization Ltd. You can find an extended version of this article here. If you have a process mining case study that you would like to share as well, please get in touch with us at anne@fluxicon.com.
Legacy systems are old systems that often support particularly important processes in an organization. At the same time, precisely because they are so old, the inner workings of these systems are typically poorly understood. This makes them hard to adapt or replace altogether.
There have been previous examples, where process mining was used to understand the behavior of a legacy system. However, in these examples there was existing log data that could be analyzed. What do you do if your legacy system does not provide any suitable event log data at all?
This is where the following approach can help: We can create a new logging capability in the legacy system by combining model generation and instrumentation of software code. Here is how it works.
Example: Hotel management system
Let us look at the example of a hotel management system. The system is used by the hotel reception to create new reservations, check in and check out guests, and to keep records of the food and beverages for billing. Figure 1 shows a screenshot of the current desktop application.
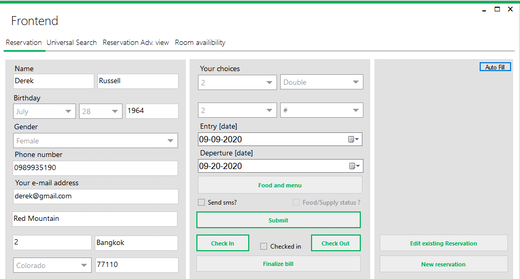
Figure 1: Screenshot of the hotel management application
The hotel management wants to extend or replace the system with the goal to let guests make online reservations in the future. When we set out to modernize a system, we need to first fully understand how the existing system is used to make sure that all the important functionalities are covered in our redesign. Unfortunately, there is limited knowledge and documentation available for the hotel management system.
Therefore, we want to use process mining to understand the different scenarios of the current reservation and billing processes. However, the system creates no usage logs at the moment. All we have is the C# source code and the data model in the SQL database.
Step 1: Generate the static model
To create the logging that is required for process mining, we start with the SQL database that stores all the records in a so-called data model. The data model describes the tables, relations, fields, and field types. This description can be extracted from the database in terms of a so-called SQL schema. This schema is translated into objects with attributes and relationships. For example, a customer has a first name, a last name, and a reservation from entry day to departure day (see Figure 2 below).
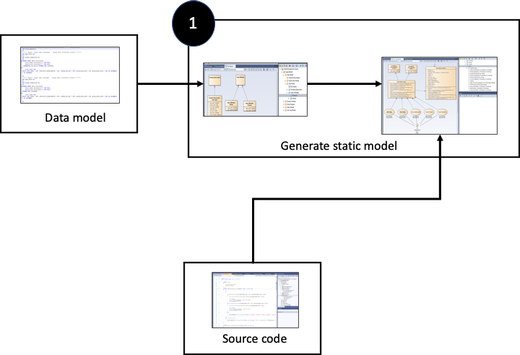
Figure 2: Generate static model from data model and source code
This model is then extended by parsing the source code (this can be done with virtually any programing language) to provide an overview of all the components in the system including the classes, attributes and methods. This results in the so-called ‘static model’, which gives an overview of all the components in the system.
Step 2: Generate the dynamic model
The static model shows the information that is processed but not the order in which this is done. Software code is composed of classes, representation of objects and properties, and the methods that provide the behavior of the system. However, the static model does not describe the order in which the methods take place.
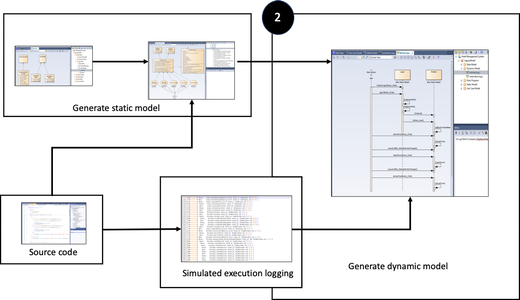
Figure 3: Generate dynamic model by simulating source code
To gain an understanding of the dependencies between the methods, it is necessary to record and analyze the dynamic execution of the software.
To achieve this, we instrument the source code to enable the logging of program flow during normal usage of the application. This results in a log from which UML sequence diagrams are generated. These sequence diagrams now describe the flow of the methods that are invoked at each object. This ‘dynamic model’ is not a business process but the sequence of methods related to one use case.
Step 3: Extend the dynamic model
For the process mining data we need information about what the case ID and the activity names are. In the dynamic model, we can define the activities by selecting which methods define the start or end of an activity. The model is extended by tagging the methods in the sequence diagram to define when to log what. Note that no code is changed, only properties in the model are set.
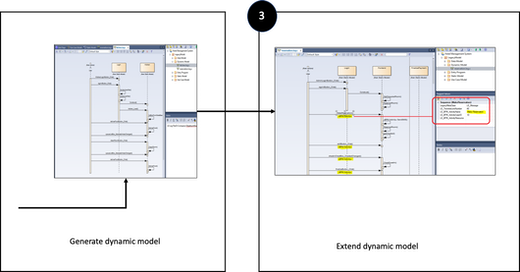
Figure 4: Extend the dynamic model with logging by tagging methods
At this point also the case ID and further attributes from the static model can be selected to be included as part of the logging. For example, the reservation number or customer number can be added to represent the case ID. One of the advantages is that you can start small, with minimal impact to the application, and add more information by repeating step 3, 4, and 5.
Step 4: Instrumentation, build, deploy and run
In the next step, we automatically re-generate the application by combining the original source code with the logging directives on the sequence diagrams. The original source code is not touched. It is only combined with the code to introduce the logging behavior described by the tags in the sequence diagrams. This is referred to as instrumentation. It is important that the original source code itself is not changed, because we don’t want to change anything else in the system’s behavior.
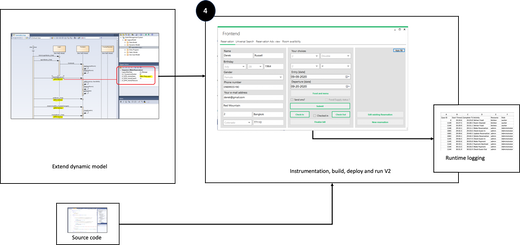
Figure 5: Instrument code, build and deploy new version of the system
The instrumented code can be built into a new version of the hotel management application. This instrumented application behaves identically to the original one, with the additional capability of event logging. The logging starts at the moment that the instrumented version is deployed. So, from that moment on it is possible to analyze new reservations and the execution of any other system use case.
Step 5: Analyze logging
The output of step 4 is the ‘runtime logging’ event log that we can now analyze with process mining. We have to wait until enough events have been collected to perform a representative process mining analysis. For each of the run methods for which a tag was added in the sequence diagram an event will be added to the log. A snippet of the resulting log is shown in Figure 6 below.

Figure 6: The event log captured by the instrumented version of the hotel management system
When you import this event log into Disco then the process map shown in Figure 7 below is discovered. In the process mining tool, we can further analyze the system behavior based on the actual usage of the instrumented system.
As soon as we understand the current behavior in detail, we can start working on the new system that supports online reservations for future customers without losing track of all the other scenarios from the current system that still need to be supported.

Figure 7: The discovered process map
This is a small and simple example, but imagine a large legacy system that has many different functionalities. Without process mining we would have to manually look at the source code to understand how the system works. For a large system, going through the entire source code can be a very time-consuming and daunting task.
Furthermore, looking at the source code does not give us any indication about how the system is actually used. So, we might end up transferring pieces of functionality to a replacement system that are no longer necessary, thereby making the new system more complicated than it needs to be.
Process mining is a great way to understand processes of any kind. Leveraging process mining to understand the inner workings of legacy systems is an application area, where this insight is especially valuable.
Leave a Comment
You must be logged in to post a comment.






