
4 Success Factors for Machine Learning in Fraud Detection
Blog: Enterprise Decision Management Blog

In a recent blog post, I discussed how FICO is fighting application fraud by leveraging artificial intelligence (AI) and machine learning in fraud detection, including an overview of supervised, unsupervised, and adaptive analytics techniques and the need to balance transparency (explainable AI) with predictiveness.
Most computer software encodes a set of rules — an algorithm — that a human has explicitly defined. Machine learning enable us to build predictive software that “learns” from data instead of being told explicitly what to do. Hence, machine learning in fraud detection provides tremendous value above and beyond the broad-based approach of rules-only based detection, including considerable performance lift.
Contrary to popular belief and our deepest wishes, however, you can’t just throw a bunch of data at a machine learning model and expect success. Machine learning in fraud detection performs better when we know the strengths and limitations of myriad of analytic toolkits (e.g., supervised vs. unsupervised approaches), and understand the factors that determine accuracy. Let’s dig into the four categories of factors.
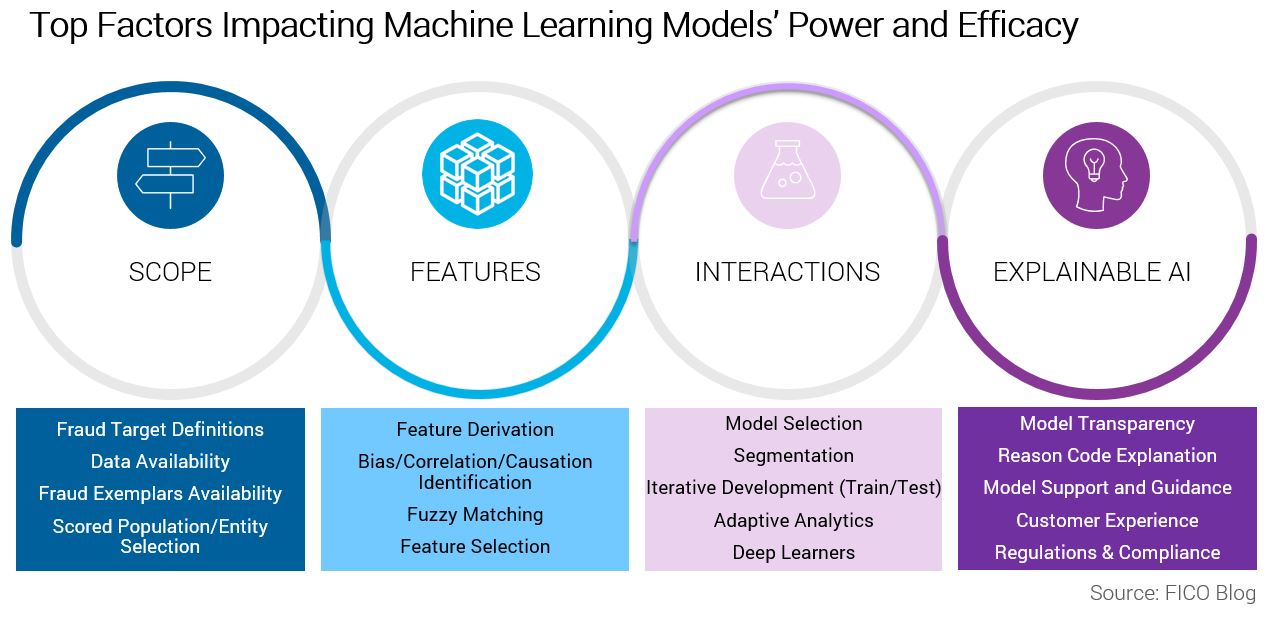
Scope
Scope requires setting a reasonable objective for a model, including identifying the target you want to make a prediction about and ensuring there is sufficient data. While a highly focused model only addresses a small, specialized part of a fraud problem, we are able to optimize and refine the model to do that specific job very well. On the other hand, a general model can address a larger class of a fraud types, with the trade-off that it may not perform as well as a specialized model. Often the best is a combination of focused and general scored models that can be efficiently handled by segmentation via sub-models.
To strike the right balance, we must ask:
- What entity are we scoring — the application, the applicant, the customer, the account?
- What models are built for specific fraud schemes (e.g., synthetic identities, bust-outs) or is the fraud definition more generic (e.g., third-party and first-party fraud) requiring broader defined fraud detection models?
- What historical data is required to support the development of the model types — are there sufficient fraud tags?
- Is the model consortium utilizing various clients’ definitions of fraud types that must be fused to take advantage of broader insight and performance gained from consortium approaches?
- How long is the model expected to be used in production? What is the anticipated lifetime of the mode? Do we need adaptive and self-learning technologies to keep the model robust?
- What are the transparency requirements of the model?
Features
Machine learning models rely on features derived from the historical data to infer the patterns and relationships within the data. In other words, data doesn’t cut it and we need to create feature detectors of both fraud and non-fraud supported both by the available historical data and the anticipated production data. We need to appropriately define features based on the current historical fraud and non-fraud behaviors, and create features that are generic and that will adapt to new patterns in the production data as fraudsters change their tactics.
There are many types of features that FICO uses in our own application fraud model characteristic libraries. One example is the use of Network Analytics (SNA), as was discussed in a recent FICO webinar, Layered Defenses in the Fight Against Application Fraud. Other examples include behavioral profiling techniques, archetypes clustering, bureau characteristics, output of fuzzy matching, and many more that are a topic for another day.
Interactions
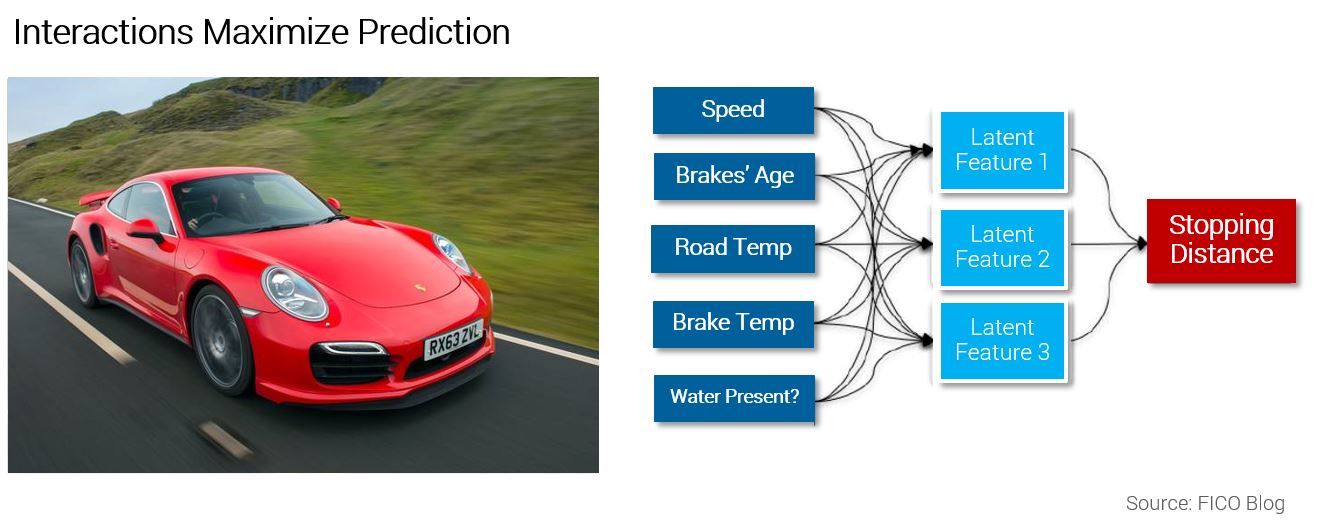
From feature creation we have a number of feature detectors, each with varying degrees of predictive power, but they must be combined into a score. Machine learning allows the signals in data to be combined in optimal ways to maximize detection and minimize false positives. The relationships learned are far too complex for human analysts, or indeed the data scientist, to impute. The machine learning process facilitates learning of nonlinear combinations of features — latent features — where machine learning explores which combinations of features lead to interactions between signals that strengthen predictiveness.
For example, consider the raw data inputs needed to determine the stopping distance of a car. You could capture a variety of data points such as ambient temperature, the presence of water, and weight of the vehicle. There are relationships between these inputs that are far more powerful than a simpler model that does not model interaction terms would learn from historical data.
However, to achieve the most accurate results, the model should also look at interactions between these variables. For example, the relationship between water and temperature indicates the presence of ice — clearly a predictive feature that strongly influences stopping distance.
Explainable AI
One of the biggest challenges in operationalizing machine learning in fraud detection is the need for transparency in a highly regulated credit lending environment. FICO is on the frontier of explainable AI (XAI), researching and developing techniques to enable humans to understand how the machine learning model reached its score, increase the shelf life of analytic models, and providing real-world applicability for organizations to utilize the power of advanced analytics while meeting governance and regulatory requirements on ML.
Stay Tuned for More
Next up in my blog series is an interview with data scientist and application fraud domain expert Derek Dempsey. In the meanwhile, be sure to check out our previous posts on application fraud:
- Trends in Application Fraud – From Identity Theft to First-Party Fraud
- Best Practices in Establishing Your Fraud Risk Appetite
- ELI5: How Does the Dark Web Work?
- What Data Do I Need to Fight Application Fraud?
- Preventing Application Fraud with Machine Learning and AI
The post 4 Success Factors for Machine Learning in Fraud Detection appeared first on FICO.
Leave a Comment
You must be logged in to post a comment.






