

3 Ways Big Data Will Influence the Future of People Analytics
Blog: The Process Street Blog

Big Data freaks me out.
Chalk it up to being spoonfed George Orwell at an early age or adolescent heroes like Fox Mulder and Neo. Maybe it’s being one of those darn, pesky Millennials always rousing rabble while perpetually straddling the conflicting worlds of analog vs digital.
Regardless: I do not trust institutions, especially institutions that want my information.
On the other hand, I use Google for everything, Alexa lives in every room of my house, and I get really annoyed when Netflix doesn’t remember that I watched something. 10 years ago. On DVD.
We will live within this dichotomy of acceptable spying and unacceptable spying. “Cyberstalking” acquaintances, colleagues, and future partners is considered the norm, as a consumer, it’s fantastic. Who doesn’t love being shown that exact thing you don’t really need the minute you pop ‘round to your friendly internet megastore?
All of those things depend on Big Data. As data collection methods improve, more and more applications for that data are coming into play. In addition to customer profiles, education, healthcare, and finance are all jumping on the Big Data bandwagon.
While traditionally more art than science, HR departments have also become recent converts to the sway of data collection. Applying hard data to soft skills may feel wrong, but people analytics has a vital role to play in measuring the employee experience.
But with additional metrics, new sources, and faster methods of collection popping up every day, what will the future of people analytics look like? More importantly, what role will Big Data play in that evolution?
In this Process Street post, I’m going to look at exactly what Big Data is and the three primary ways it will affect the hows, whys, and whats of people analytics going forward.
What exactly is “Big Data”?
The definition of Big Data is nebulous at best. Conventionally, Big Data is large, complex data sets that are extremely difficult or impossible to actually process.
The problem with this definition is the “large, complex data set” part. What qualifies as large and complex is constantly – and very quickly – changing.
The very first iPhone (way back in 2007) offered a storage option of 4, 8, or 16 GB. By contrast, 2021’s iPhone 12 comes with either 64, 128, or 256 GB, with the most frequent search question being: Is 256 GB enough?
Obviously, the concept of “large” is a bit relative.
In 2001, Gartner analyst Doug Laney introduced the idea of the “3 V’s of Big Data.” The actual Gartner-approved definition of Big Data is:
“‘Big data’ is high-volume, -velocity, and -variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.”
Personally, I think this definition is just as ambiguous, but, just for funsies, let’s presume Gartner knows what it’s talking about.
A quick search reveals that, as always, Laney’s 3 V’s have been greatly expanded to 5, 8, and even 42 (seriously – 42 V’s. I’m not sure I even know 42 words beginning with V).
For the most part, though, these additions seem to be splitting hairs more than anything. For example, when you include both veracity (the quality of data) and validity (data quality), it starts to get a little silly.
As a result, I’ve fallen back to the seminal work of Jean-Paul Isson and Jesse S. Harriott, Ph.D. for the definitive number of V’s necessary to define Big Data. There are 4. It’s nice, succinct, and pretty much covers all the bases. Less is more, after all (just ask my editor).
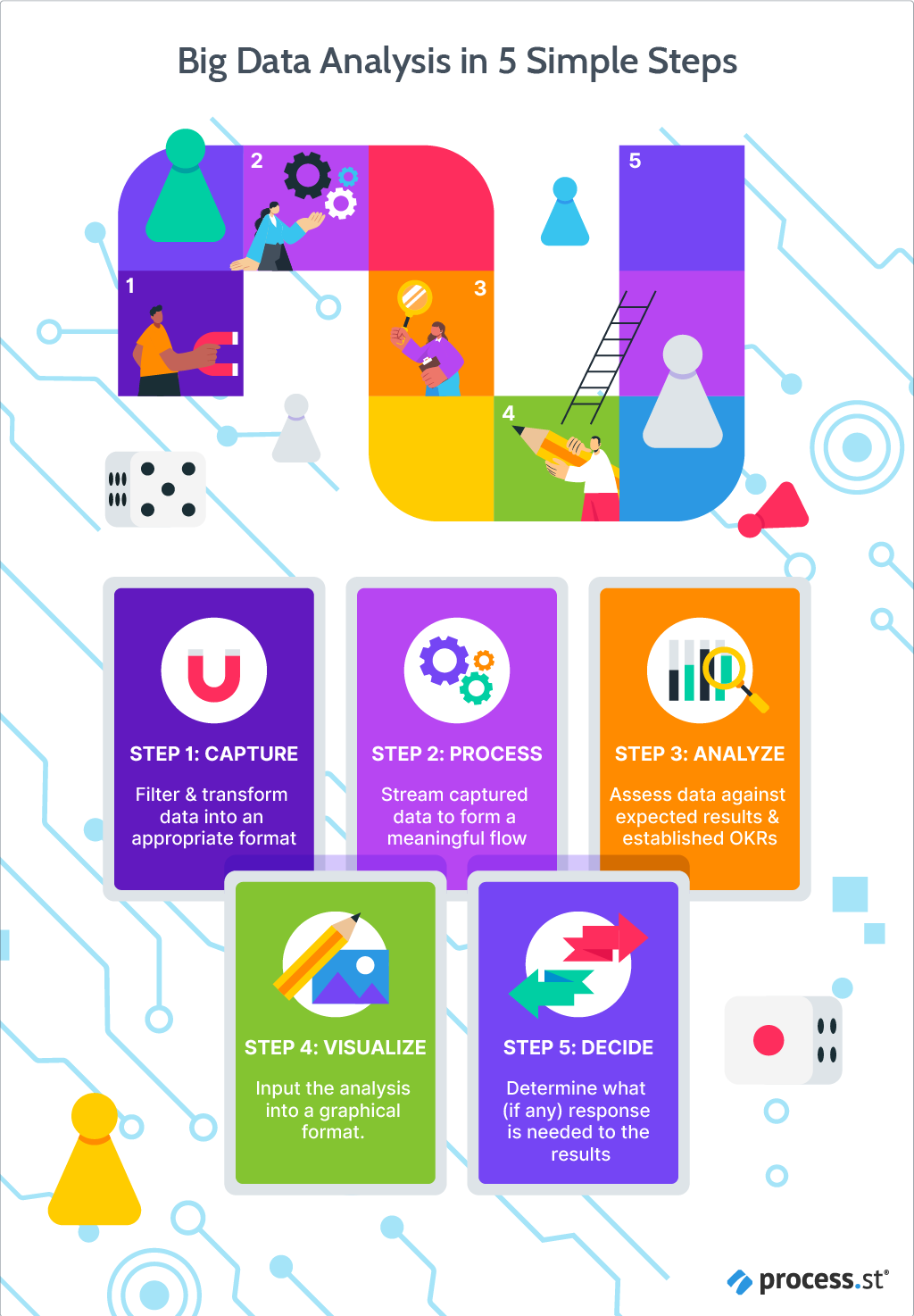
The 4 V’s of Big Data
For the past few months, People Analytics in the Era of Big Data has been propped open on my desk and consulted with more dedication than a religious text as I’ve coerced my editor into letting me dive further down the data collection/privacy/security rabbit hole.
I’m not the only one who’s put Isson and Harriott upon (7) pillar(s), though. It doesn’t take much digging to end up being directed towards their research over and over.
If this is your first encounter with them, however, allow me to provide a bit of introduction:
Jean-Paul Isson is an author, speaker, analyst, and teacher who currently serves as the VP and Chief Data Science & Artificial Intelligence Officer at SITA (data solutions for the aviation industry). Prior to that, he worked for Monster, and Concordia University (Canada).
Jesse S. Harriott, Ph.D. is a graduate of MIT and DePaul University and the Executive Director and Head of Analytics at WorkhumaniQ. He’s also a professor, analytics consultant, and political advisor.
Basically, these are two really smart guys who know their stuff.
Isson and Harriott follow Laney’s lead with the first three V’s – volume, velocity, and variety – but take it one step further by adding their own: value.

Volume
“The exact criteria for what is considered large volume is a moving target as the technology is improving so rapidly that yesterday’s large-volume data set is today’s typical-size data set.” – People Analytics in the Era of Big Data
The advantage of more volume is the ability to use statistical models for much more accurate behavior predictions. Best informed is best prepared, after all.
That said, large volumes of data can be unwieldy. Not only does it require scalable storage, but also the capacity to actually process it all, both of which pose challenges to conventional IT tools and systems. Companies usually have the ability to house large amounts of archived data, but ultimately lack the resources to do anything with it.
Velocity
Velocity means that Big Data travels very fast and it doesn’t stop. The modern company needs to have the architecture and tools to process all this very fast, very large data coming in nonstop.
While that can be a potential obstacle, these data streams allow companies to form detailed user profiles at the click of a button. This is how Amazon determines those “related item” prompts once you checkout or the grocery store can check if you’ve forgotten a frequently bought item.
Variety
Customer comments on social media, popular search terms on Google, GPS and/or WiFi tracking, metadata on uploaded images and videos – the sources and channels used to retrieve Big Data are growing exponentially.
The challenge with this is that companies are receiving unstructured data – which isn’t always easy to process and analyze – alongside the traditional structured data. Again, without the right infrastructure to review it, all that unstructured data will remain useless.
The advantage, though, is that this variety of interactions provides a more complete view of an individual’s actions and motivations, which allows for more accurate and precise algorithms to develop.
Value
I hoard information pretty indiscriminately. My partner is always asking: What are you going to do with that information? And I invariably respond: I don’t know, but I have it.
I’d estimate that a good 85-90% of the knowledge I have is just random detritus I’ve picked up somewhere (no, it does not make me exceptionally good at pub quizzes). Sometimes that data is unexpectedly useful, but more often than not – like all the other things we hold onto because we might need them in the future – it just sits there gathering figurative dust in my brain.
“Big Data without business value is simply noise.” – People Analytics in the Era of Big Data
Volume, velocity, and variety bring the picture into focus. The fourth V – value – is about what you can do with that picture. The data you have might be incredibly accurate, detailed, and interesting, but if your business can’t derive any value from it, why do you have it?
The future of Big Data and people analytics
Back in the olden days, job hunters had to physically hand in their CVs in person. If they looked like a good match on paper, they’d get an interview and the hiring manager would ask them questions like, What is your biggest weakness?
You were expected to respond with something like: My biggest weakness is that I’m a perfectionist. Then go on to describe yourself as a people person with strong leadership skills while also being a team player.
Basically, the traditional interview was BS and we all knew it. In a manufacturing economy, that generally worked out – if you made widgets for Brand X for 15 years, you could probably also make widgets for Brand F.
In a knowledge economy, with its plethora of alternative work options, competition, and employee mobility, companies need to be a bit more attentive to culture fit, tacit knowledge and skills, and where exactly to find the top talent they want – because chances are, your next star employee isn’t just going to walk through your front door (especially if you don’t have a front door to walk through).
Fortunately, Big Data solves a lot of these problems. A thorough analysis of Big Data allows HR departments to gain insight into their current employees (and their skills, priorities, interests, and ambitions) as well as future staffing needs (who, how many, when, for how long) and who should fill those roles (where/how to recruit, required training, concerns, and potential retention).
Cyborg HR: Resistance is futile
We are a society of cyborgs.
I know. Modern science fiction has taught you to imagine cyborgs as organic beings permanently fused with machines (or machines fused with organic features). The word “cyborg” makes you think of the Terminator, Star Trek’s Borg Collective, and RoboCop. That’s only one idea of the cyborg, though.
From implants and artificial organs to cell phones and smart houses, we are living in an age where humans are a synthesis of animal and machine far more than they are animal alone.
I won’t get philosophical about it (that’s another post for another blog), but ask yourself: How many things do machines do for (or with) you in a single day? And remember – computers aren’t the only machines out there.
We know from experience that the amount of data being captured has increased exponentially – even just in the last few years – and shows absolutely zero signs of slowing down any time soon.
It’s a simple question of supply and demand. As people analytics becomes more and more mainstream, employers will want more quantities of data at higher qualities. The need for more complex data will require more effective tools for collecting, processing, and analyzing it, which will, in turn, lead to a demand for faster tech that’s capable of handling those demands.
HR departments will be able to make even more precise and accurate predictions about workforce planning, employee engagement, and preparing for an organization’s future needs. (Which will inevitably lead back around to a demand for even more data, and the great cycle begins anew.)
More tasks will be handed over to the algorithms parsing the data. More processes will become automated. It’s possible that functions that once required multiple teams of people could be performed by only one or two individuals.
This is the cyborgization of HR management. Welcome to the Collective.

(C’mon. Like you never wanted to be a robot as a kid.  )
)
Relation analytics: Not your grandma’s data stream anymore
While we’re talking about data volumes, I might as well mention relation analytics. It’s like people analytics, but more (kinda a theme here, huh?). The main difference between the two is that people analytics focuses on quantitative data (work history, tenure, education, etc.) while relation analytics deals with qualitative data (influence, efficiency, motivation, etc.).
Basically, relation analytics doesn’t just focus on data about an individual. It’s that, sure, but it’s also about how they interact with all the other individuals you’re collecting data on.
TL;DR Relation analytics isn’t just what they do, but who they do it with.
Just like the current realm of people analytics covers a ridiculous array of data from the number of full-time employees in your organization to the number of times a single employee uses semi-colons, relation analytics is a pretty ambiguous term for an as-yet-fully-defined category.
The aim of relation analytics is to provide a more holistic view of a situation. Contemporary people analytics deals with facts about individuals, which are then compiled to assume facts about the group.
Say you have a team of 20 people: 11 women, 2 nonbinary people, and 6 men. Two of the women are the leading experts in their respective fields, and the team leader is one of the nonbinary individuals. All in all, this seems like a win for gender equality in the workplace, right?
Through the lens of people analytics – yes. If the data is pushed through a relation analytics filter, however, we might get more context on the situation. By reviewing the language each team member uses in their communications with each other, reports given, and casual conversation, their actual sentiments towards each other, the company, and their project can be better examined.
So you have this gender-diverse team, but some of the team members constantly undermine the team leader. It’s nothing overtly discriminatory and the team leader doesn’t feel targeted based on their gender, but it’s still hampering their ability to do their job and compromising the team’s productivity overall.
Even though one of the female experts consistently delivers high-quality work on time, data about her speech patterns reveals that she’s actually under extreme stress and is considering finding a position elsewhere as a result. Further investigation reveals that no one else in the company actually knows how to do her job, which is why she’s overworked in the first place.
One of the team members has only been at the company for a few months and this is his first position in the industry, so he doesn’t have a lot of experience. In his spare time, he spends a lot of time volunteering with community outreach organizations, largely working with council members, politicians, and other officials on various initiatives. As a result, he’s established his credibility within a large network of contacts, as well as the skills needed for negotiation, project management, and inter-organizational collaboration.
All three of these situations are problems that can be brought to light – and then dealt with – based on insights gotten from relation analytics data.
Just because you can doesn’t mean you should
In a remote part of Siberia, Dr. Sergey Zimov and his son, Nikita, have been working on a multi-generational project to recreate a rare ecosystem to combat climate change. Science says that replacing forests with grassland will slow the thawing permafrost and avert the sudden release of dangerous climate change accelerants that will decimate life on this planet.
It’s an ambitious project, to be sure, but since 1996, they’ve been pretty successful in seeding the grassland and even importing large grazing animals such as horses, musk ox, and bison to sustain this man-made biome.
The crucial element to the success of what’s become known as Pleistocene Park, however, is the woolly mammoth.

No, this is not another Jurassic Park reboot. The Zimovs are completely committed to doing this, and geneticist George Church is confident he can deliver a lab-grown woolly mammoth within the decade.
But editing an Asian elephant’s DNA and getting the fetus to term in an artificial environment are just the first of many challenges this scheme will have to face.
“The first of the resurrected mammoths will be the loneliest animal on Earth.” – Ross Anderson, “Welcome to Pleistocene Park”
In the mid-90s, Pilanesberg National Park was hit with a rash of brutal rhino murders. Ecologists quickly determined that the mutilations were being caused by a group of delinquent teenage males.
Specifically, a herd of orphaned elephants who’d grown up without the oversight of older, larger bulls to curb their more aggressive impulses.
The introduction of woolly mammoths to Pleistocene Park poses a similar situation: a herd entirely made up of a single generation with no possible exposure to mammoth elders. What would be the impact of that on those individuals – and on everyone else that shared their ecosystem?
“In the information society, nobody thinks. We expected to banish paper, but we actually banished thought.” – Michael Crichton, Jurassic Park
Big Data is the lab-grown woolly mammoth – large, demanding, and needs to be handled with careful consideration.
While the EU has forged the way by implementing the General Data Protection Regulation (GDPR), it was only the beginning. In its first two years of its existence, the GDPR has issued hundreds of fines to companies – Google and Facebook among them – that add up to over €114 million (roughly $132 million).
Following GDPR’s example, Brazil has created its Lei Geral de Proteção de Dados (or LGPD), India’s legislature will vote on its Personal Data Protection Bill, and both Canada and Australia are considering their own protection regulations.
The US hasn’t implemented a national regulation for Big Data, but California introduced the new California Consumer Privacy Act (CCPA); Texas, Nevada, New York, and Washington state are likely to follow suit in the near future.
What data can be collected, how it’s collected, what it’s used for by who, and where it’s stored (or erased) are growing issues that governments, industries, and businesses need to be aware of.
There is an ethical element to this question as well. Sure, the law may fully allow you to collect data on every keystroke, website, and communication your employees use, but why are you collecting that data? What rights to privacy do your employees have in their workplace (or home, in the case of remote workers)?
Going forward, the question of protecting employees’ privacy and data is going to become more and more significant. There will likely be a continuous evolution of legislation and regulations as new factors are considered and new situations arise, which means employers will need to be very careful about ensuring their practices and procedures are compliant and up-to-date.
“Prediction is very difficult, especially if it’s about the future.”
Tech & Big Data create an ever-changing landscape that, realistically, we can only guess at. That change is going to continue getting faster and faster, and, undoubtedly, will create obstacles, dilemmas, and complications we don’t have easy answers for.
As we look into the future of Big Data – and its uses – it’s important to consider both the benefits and consequences we – and others – face in doing so.
People analytics has the potential to be a revolutionary tool for improving employee experiences, addressing social inequities, and optimizing how business is managed. It can also be used to violate trust, disenfranchise particular groups, or cause tangible harm to an individual.
The possibilities for Big Data are no longer limited by even our imaginations so it’s important that caution, consideration, and empathy aren’t left behind in the wake of ambition. Sure, it’s cool if you can reconstruct a woolly mammoth, but how will that mammoth impact the wider sphere?
As one Mr. Samuel L. Clemens once said:
“Data is like garbage. You’d better know what you are going to do with it before you collect it.”
What are your predictions for the future of people analytics? Let us know in the comments below!
The post Blog first appeared on Process Street | Checklist, Workflow and SOP Software.
Leave a Comment
You must be logged in to post a comment.






