3 Upcoming Challenges Your Data Science Team Will Face
Data science has been increasing in popularity the past 5 years. Most – if not all – companies are busy finding ways to optimize the potential of their data by building machine learning models and moving towards Artificial Intelligence (AI).
From traditional demand forecasting to dynamic pricing, from targeted advertising to predictive maintenance, the AI wave is changing the decision-making process for companies in every industry.
With such a big change comes challenges that these companies will inevitably face, especially for the data scientists working within these organizations. Here are the top three challenges that your data science team will most likely face in the upcoming years.
Challenge #1 – Managing Data Science Application Lifecycle
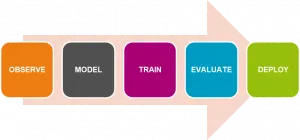
Many data scientists think that creating a machine learning model is a linear process.
To give you a short introduction, this means, observing the data to get a feel for the data-set, followed by modeling to understand how to better represent the intrinsic patterns of the data.
Once a suitable model is found, data scientists would train it on the historical data – and perhaps tune it using some error-flagging techniques like cross validation.
The team would then proceed with a performance evaluation of the model using one of the available metrics. If the model performed well and could be used in production, data scientists would pass it over to developers and data engineers who would then operationalize it and deploy it in a secure and scalable manner.
Up until now, that has been what a data science process has looked like. However, the concern with that is that patterns in the data can change and a model that works well today might not work well in the near future.
What’s the risk?
The risk here is, making the wrong business decisions due to the fact that the information you’re using is outdated. This can affect internal decisions but also, in some cases, the customers directly.
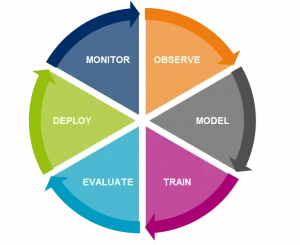
For this reason, it’s better to look at the machine learning model as a cyclical process. It’s highly important for data scientists to continue monitoring the performances of the live models and to come full circle, back to the observation phase they started at. This additional step will help the team find out what has changed in the model and how to manage this change moving forward.
Challenge #2 – Algorithm Ethics and Bias
A growing number of people rely on algorithms and data for their business decision-making. Meaning, your data science team that is developing such algorithms have a major responsibility to provide the most accurate product for your customers.
Algorithms cannot – in themselves – be unfair, per-se, but machine learning models are only as smart as the data they’ve been trained on. Training data is often biased, and this bias translates into unfair algorithms.
For example, facial recognition software is known to respond more accurately to white males than to females or to people of color. If we analyze why these machines responded a certain way, we would see that the set of images used during training were 75% male and were 80% white. Knowing this fact, there’s no wonder why facial recognition software analyzes information the way it does.
In response, larger companies – like IBM – are investing large amounts of money in finding ways to remove bias from training data and make algorithms more fair.
Biased algorithms are just the starting point. Your data scientists can build algorithms that produce up to 99% accuracy. However, the danger comes when we start relying on these algorithms to determine major decisions in our communities. What if algorithms decide who gets hired and who gets fired, who goes to jail and who walks free? What happens to the 1% then?
For now, the answer is, be wary and avoid blind trust in AI. There’s certainly a long way we must go before handing our workforce completely over to AI. Data can reveal a lot of valuable information about a scenario but that’s directly dependent upon the algorithm it has been programmed to. In short, always be critical thinkers, and try to understand and question AI-given results until it gets human approval.
Challenge #3 – Data Manipulation Risks and Algorithm Hacking
AI and machine learning models are most recently being used to determine and to steer business processes, but they also pose a risk to your company. They enable vulnerability to statistical cyber-attacks.
Take spam email senders, for example. They can disguise the content or other certain features in their emails to trick spam filtering algorithms. That’s why some spam emails still make it to our inbox.

Another great example to explain this challenge is a self driving car’s ability to recognize street signs. They quickly discovered the mishaps AI algorithms can have. In this case, the algorithm failed to recognize a stop sign when a slight change was applied to it. Something that can be easily recognized and differentiated by the human eye.
Many machine learning algorithms can sometimes be unpredictable, and their true behavior can be unclear, even to the data scientists themselves.
You see, the stickers applied on the stop sign work just like an optical illusion works for a neural network, even though they’re not an impediment to the human eye. So, it’s important to be aware that the algorithm, no matter how sophisticated, will not replace human judgement.
It is in cases like this that we expose just how great of a risk such experimental models are to human life, and it raise many questions.
What’s the solution?
There’s a lot of research taking place in the field of statistical cyber security to discover robust solutions to such attacks. However, scientists have not yet been able to create an antidote to such mishaps, and – unfortunately – all current attempts to overcome the issue have failed, thus far.
The only known solution to the issue, so far, is the use of multiple models to evaluate the same situation. The idea behind such approach is like crowdsourcing. Models work in different ways and what confuses one model will most likely not confuse another model. If multiple models think the street sign is a stop sign, and one of them doesn’t, it will just go with the majority.
If you would like to know more, please contact Erica D’Acunto, Senior Data Scientist at ORTEC Consulting, via [email protected] or via our website: www.ortec-consulting.com.
Sources:
- http://innodata.com/blog/data-training/
- https://www.nytimes.com/2018/02/09/technology/facial-recognition-race-artificial-intelligence.html
- https://spectrum.ieee.org/cars-that-think/transportation/sensors/slight-street-sign-modifications-can-fool-machine-learning-algorithms
The post 3 Upcoming Challenges Your Data Science Team Will Face appeared first on This Complex World.