
See How Products, Libraries, and Frameworks for Streaming Analytics Are Categorized and Compared
Blog: The Tibco Blog
Streaming Analytics processes data in real time while it is in motion. This concept and technology emerged several years ago in financial trading, but it is growing increasingly important these days due to digitalization and the Internet of Things (IoT). The following slide deck from a recent talk at a conference covers:
- Real-world success stories from different industries (Manufacturing, Retailing, Sports)
- Alternative frameworks and products for stream processing
- Complementary relationship to Data Warehouse, Apache Hadoop, Statistics, Machine Learning, Open Source R, SAS, Matlab, etc.
Stream Processing Frameworks and Products
The following picture shows the key differences between frameworks (no matter if open source such as Apache Storm, Apache Flink, Apache Spark or closed source such as Amazon Kinesis) and products such as TIBCO StreamBase and Live Datamart.
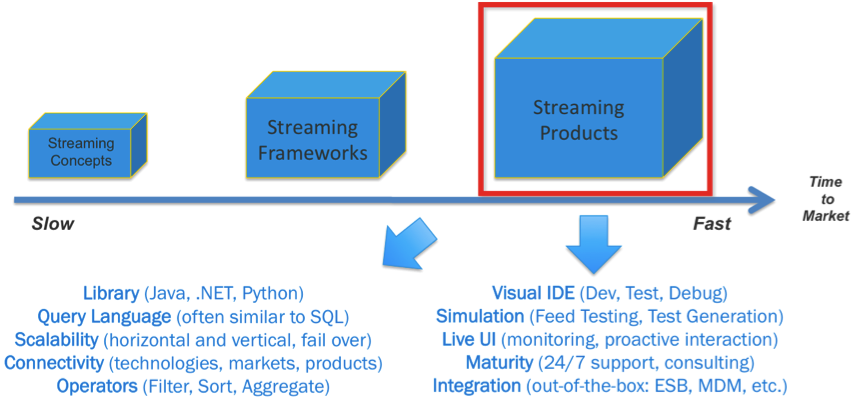
Of course, you can implement everything by writing code and using one or more frameworks. However, besides several other benefits, the key differentiator of using a product is time to market. You can realize projects in weeks instead of months or even years. Delivering quickly is the number one priority of most enterprises these days in a world where the only constant is change!
I recommend that you choose one or two frameworks and one or two products to implement a proof of concept (POC); spend five days, for example, with each one to implement a streaming analytics use case, which includes integration of input feeds or sensors, correlation / sliding windows / patterns, simulation and testing, and a live user interface to monitor and act proactively. At the end, you can compare the results and decide which fits you best.
Fast Data and Streaming Analytics in the Era of Hadoop, R, and Apache Spark
The full power of streaming analytics comes up by combining it with other concepts. A closed loop use case includes:
- analysis of historical data using a data discovery tool (done by a business user)
- added insights or patterns using more complex analytic models (done by a data scientist)
- implementation of a stream processing flow for acting in real time on new events (done by a developer)
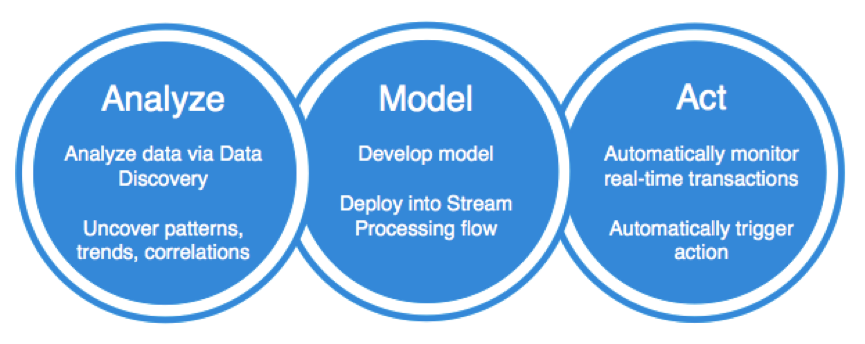
For example, you can combine TIBCO StreamBase with TIBCO Enterprise Runtime for R (TERR) to execute the analytics models (which your data scientists found by using TIBCO Spotfire and R language for analyzing historical data) in real time with every transaction while data is still in motion.
Slide Deck from JavaOne 2015 in San Francisco
The following slide deck discusses the above topics in much more detail:
Parts of this (extensive) slide deck were used for talks at several international conferences such as JavaOne 2015 in San Francisco. I appreciate any feedback about the content to improve it continuously…
If you want to learn more about Streaming Analytics and its relation to big data and Apache Hadoop, I recommend the following InfoQ article: Real-Time Stream Processing as Game Changer in a Big Data World with Hadoop and Data Warehouse.
Leave a Comment
You must be logged in to post a comment.






